 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Localization and Affordance Prediction for Tasks in Egocentric Video
Jul 18, 2024



Vision-Language Models (VLMs) have shown great success as foundational models for downstream vision and natural language applications in a variety of domains. However, these models lack the spatial understanding necessary for robotics applications where the agent must reason about the affordances provided by the 3D world around them. We present a system which trains on spatially-localized egocentric videos in order to connect visual input and task descriptions to predict a task's spatial affordance, that is the location where a person would go to accomplish the task. We show our approach outperforms the baseline of using a VLM to map similarity of a task's description over a set of location-tagged images. Our learning-based approach has less error both on predicting where a task may take place and on predicting what tasks are likely to happen at the current location. The resulting system enables robots to use egocentric sensing to navigate to physical locations of novel tasks specified in natural language.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021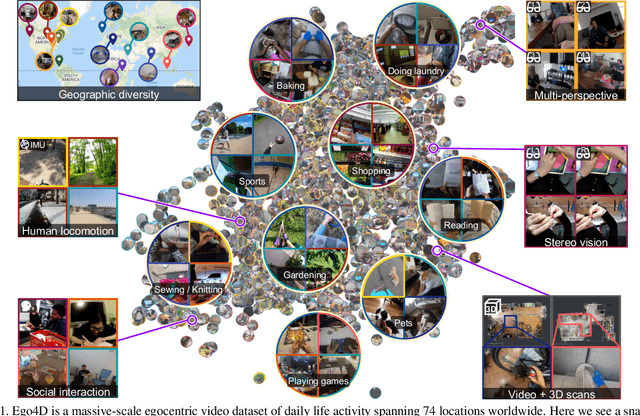
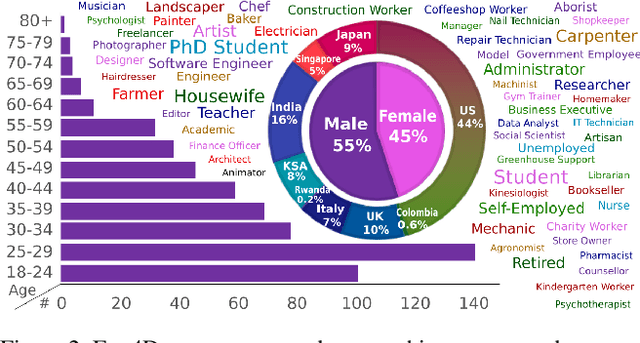

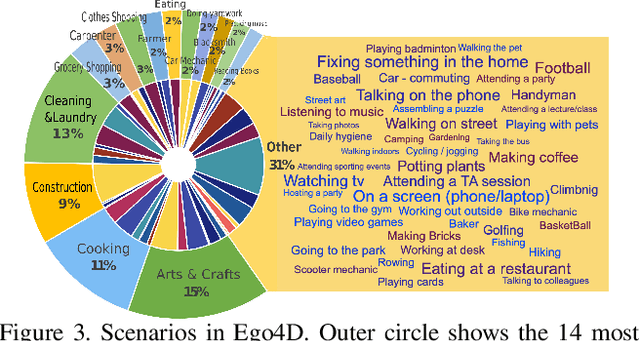
We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/