 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESSENTIAL: Episodic and Semantic Memory Integration for Video Class-Incremental Learning
Aug 14, 2025In this work, we tackle the problem of video classincremental learning (VCIL). Many existing VCIL methods mitigate catastrophic forgetting by rehearsal training with a few temporally dense samples stored in episodic memory, which is memory-inefficient. Alternatively, some methods store temporally sparse samples, sacrificing essential temporal information and thereby resulting in inferior performance. To address this trade-off between memory-efficiency and performance, we propose EpiSodic and SEmaNTIc memory integrAtion for video class-incremental Learning (ESSENTIAL). ESSENTIAL consists of episodic memory for storing temporally sparse features and semantic memory for storing general knowledge represented by learnable prompts. We introduce a novel memory retrieval (MR) module that integrates episodic memory and semantic prompts through cross-attention, enabling the retrieval of temporally dense features from temporally sparse features. We rigorously validate ESSENTIAL on diverse datasets: UCF-101, HMDB51, and Something-Something-V2 from the TCD benchmark and UCF-101, ActivityNet, and Kinetics-400 from the vCLIMB benchmark. Remarkably, with significantly reduced memory, ESSENTIAL achieves favorable performance on the benchmarks.
EASG-Bench: Video Q&A Benchmark with Egocentric Action Scene Graphs
Jun 06, 2025We introduce EASG-Bench, a question-answering benchmark for egocentric videos where the question-answering pairs are created from spatio-temporally grounded dynamic scene graphs capturing intricate relationships among actors, actions, and objects. We propose a systematic evaluation framework and evaluate several language-only and video large language models (video-LLMs) on this benchmark. We observe a performance gap in language-only and video-LLMs, especially on questions focusing on temporal ordering, thus identifying a research gap in the area of long-context video understanding. To promote the reproducibility of our findings and facilitate further research, the benchmark and accompanying code are available at the following GitHub page: https://github.com/fpv-iplab/EASG-bench.
Reinforcement Learning meets Masked Video Modeling : Trajectory-Guided Adaptive Token Selection
May 13, 2025Masked video modeling~(MVM) has emerged as a highly effective pre-training strategy for visual foundation models, whereby the model reconstructs masked spatiotemporal tokens using information from visible tokens. However, a key challenge in such approaches lies in selecting an appropriate masking strategy. Previous studies have explored predefined masking techniques, including random and tube-based masking, as well as approaches that leverage key motion priors, optical flow and semantic cues from externally pre-trained models. In this work, we introduce a novel and generalizable Trajectory-Aware Adaptive Token Sampler (TATS), which models the motion dynamics of tokens and can be seamlessly integrated into the masked autoencoder (MAE) framework to select motion-centric tokens in videos. Additionally, we propose a unified training strategy that enables joint optimization of both MAE and TATS from scratch using Proximal Policy Optimization (PPO). We show that our model allows for aggressive masking without compromising performance on the downstream task of action recognition while also ensuring that the pre-training remains memory efficient. Extensive experiments of the proposed approach across four benchmarks, including Something-Something v2, Kinetics-400, UCF101, and HMDB51, demonstrate the effectiveness, transferability, generalization, and efficiency of our work compared to other state-of-the-art methods.
DecompDreamer: Advancing Structured 3D Asset Generation with Multi-Object Decomposition and Gaussian Splatting
Mar 15, 2025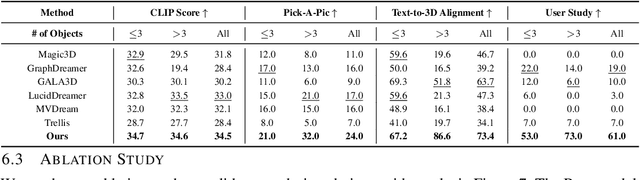
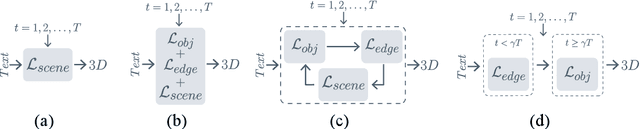

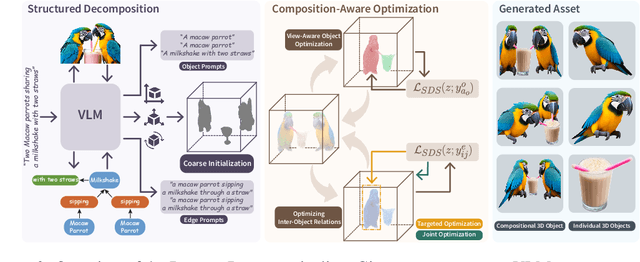
Text-to-3D generation saw dramatic advances in recent years by leveraging Text-to-Image models. However, most existing techniques struggle with compositional prompts, which describe multiple objects and their spatial relationships. They often fail to capture fine-grained inter-object interactions. We introduce DecompDreamer, a Gaussian splatting-based training routine designed to generate high-quality 3D compositions from such complex prompts. DecompDreamer leverages Vision-Language Models (VLMs) to decompose scenes into structured components and their relationships. We propose a progressive optimization strategy that first prioritizes joint relationship modeling before gradually shifting toward targeted object refinement. Our qualitative and quantitative evaluations against state-of-the-art text-to-3D models demonstrate that DecompDreamer effectively generates intricate 3D compositions with superior object disentanglement, offering enhanced control and flexibility in 3D generation. Project page : https://decompdreamer3d.github.io
Graph-Based Multimodal and Multi-view Alignment for Keystep Recognition
Jan 07, 2025Egocentric videos capture scenes from a wearer's viewpoint, resulting in dynamic backgrounds, frequent motion, and occlusions, posing challenges to accurate keystep recognition. We propose a flexible graph-learning framework for fine-grained keystep recognition that is able to effectively leverage long-term dependencies in egocentric videos, and leverage alignment between egocentric and exocentric videos during training for improved inference on egocentric videos. Our approach consists of constructing a graph where each video clip of the egocentric video corresponds to a node. During training, we consider each clip of each exocentric video (if available) as additional nodes. We examine several strategies to define connections across these nodes and pose keystep recognition as a node classification task on the constructed graphs. We perform extensive experiments on the Ego-Exo4D dataset and show that our proposed flexible graph-based framework notably outperforms existing methods by more than 12 points in accuracy. Furthermore, the constructed graphs are sparse and compute efficient. We also present a study examining on harnessing several multimodal features, including narrations, depth, and object class labels, on a heterogeneous graph and discuss their corresponding contribution to the keystep recognition performance.
Deep Geometric Moments Promote Shape Consistency in Text-to-3D Generation
Aug 12, 2024



To address the data scarcity associated with 3D assets, 2D-lifting techniques such as Score Distillation Sampling (SDS) have become a widely adopted practice in text-to-3D generation pipelines. However, the diffusion models used in these techniques are prone to viewpoint bias and thus lead to geometric inconsistencies such as the Janus problem. To counter this, we introduce MT3D, a text-to-3D generative model that leverages a high-fidelity 3D object to overcome viewpoint bias and explicitly infuse geometric understanding into the generation pipeline. Firstly, we employ depth maps derived from a high-quality 3D model as control signals to guarantee that the generated 2D images preserve the fundamental shape and structure, thereby reducing the inherent viewpoint bias. Next, we utilize deep geometric moments to ensure geometric consistency in the 3D representation explicitly. By incorporating geometric details from a 3D asset, MT3D enables the creation of diverse and geometrically consistent objects, thereby improving the quality and usability of our 3D representations.
Ego-VPA: Egocentric Video Understanding with Parameter-efficient Adaptation
Jul 28, 2024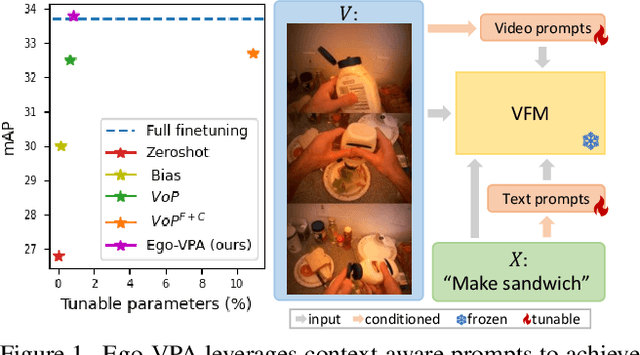
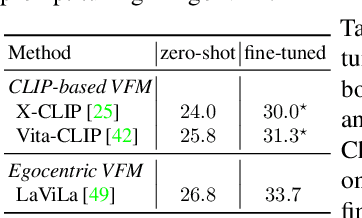
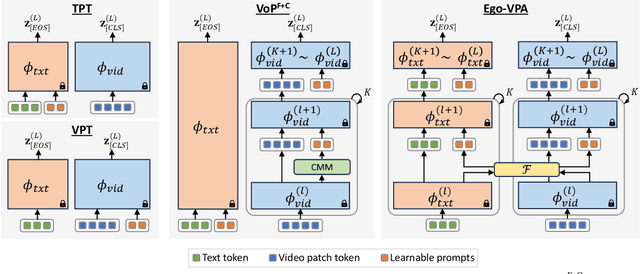
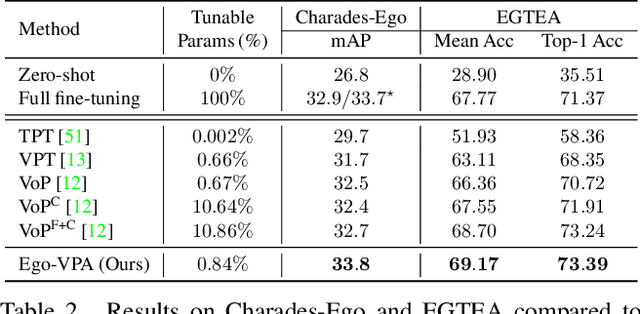
Video understanding typically requires fine-tuning the large backbone when adapting to new domains. In this paper, we leverage the egocentric video foundation models (Ego-VFMs) based on video-language pre-training and propose a parameter-efficient adaptation for egocentric video tasks, namely Ego-VPA. It employs a local sparse approximation for each video frame/text feature using the basis prompts, and the selected basis prompts are used to synthesize video/text prompts. Since the basis prompts are shared across frames and modalities, it models context fusion and cross-modal transfer in an efficient fashion. Experiments show that Ego-VPA excels in lightweight adaptation (with only 0.84% learnable parameters), largely improving over baselines and reaching the performance of full fine-tuning.
SViTT-Ego: A Sparse Video-Text Transformer for Egocentric Video
Jun 13, 2024Pretraining egocentric vision-language models has become essential to improving downstream egocentric video-text tasks. These egocentric foundation models commonly use the transformer architecture. The memory footprint of these models during pretraining can be substantial. Therefore, we pretrain SViTT-Ego, the first sparse egocentric video-text transformer model integrating edge and node sparsification. We pretrain on the EgoClip dataset and incorporate the egocentric-friendly objective EgoNCE, instead of the frequently used InfoNCE. Most notably, SViTT-Ego obtains a +2.8% gain on EgoMCQ (intra-video) accuracy compared to LAVILA large, with no additional data augmentation techniques other than standard image augmentations, yet pretrainable on memory-limited devices.
Contrastive Language Video Time Pre-training
Jun 04, 2024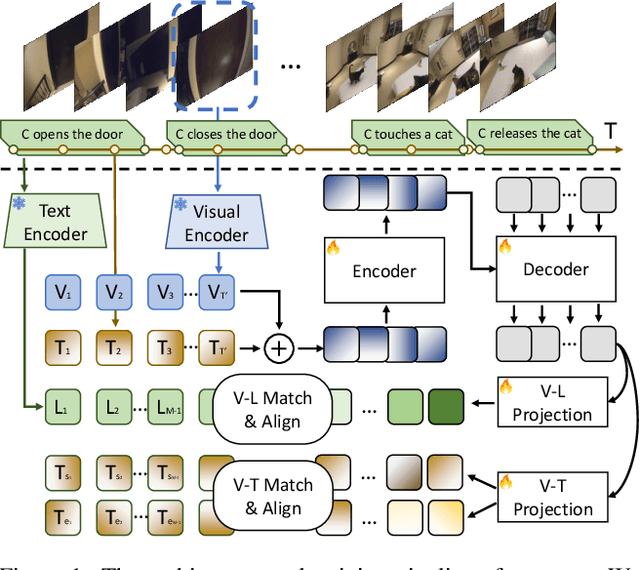
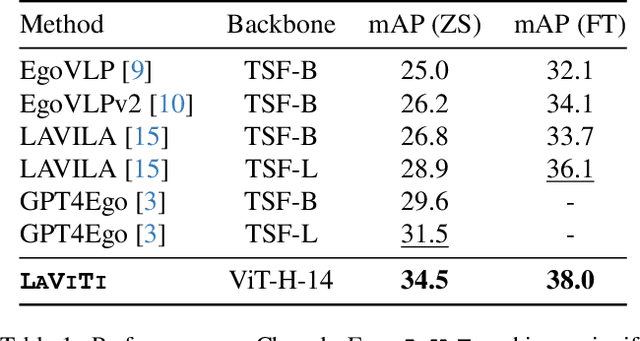

We introduce LAVITI, a novel approach to learning language, video, and temporal representations in long-form videos via contrastive learning. Different from pre-training on video-text pairs like EgoVLP, LAVITI aims to align language, video, and temporal features by extracting meaningful moments in untrimmed videos. Our model employs a set of learnable moment queries to decode clip-level visual, language, and temporal features. In addition to vision and language alignment, we introduce relative temporal embeddings (TE) to represent timestamps in videos, which enables contrastive learning of time. Significantly different from traditional approaches, the prediction of a particular timestamp is transformed by computing the similarity score between the predicted TE and all TEs. Furthermore, existing approaches for video understanding are mainly designed for short videos due to high computational complexity and memory footprint. Our method can be trained on the Ego4D dataset with only 8 NVIDIA RTX-3090 GPUs in a day. We validated our method on CharadesEgo action recognition, achieving state-of-the-art results.
R.A.C.E.: Robust Adversarial Concept Erasure for Secure Text-to-Image Diffusion Model
May 25, 2024
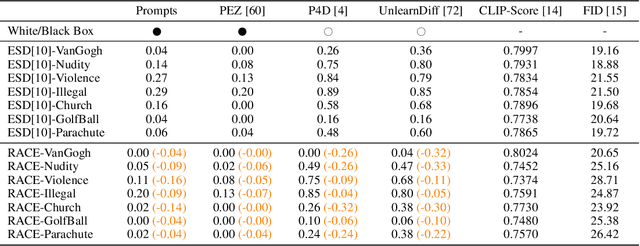
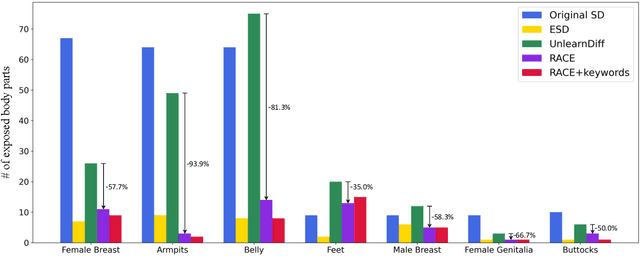
In the evolving landscape of text-to-image (T2I) diffusion models, the remarkable capability to generate high-quality images from textual descriptions faces challenges with the potential misuse of reproducing sensitive content. To address this critical issue, we introduce Robust Adversarial Concept Erase (RACE), a novel approach designed to mitigate these risks by enhancing the robustness of concept erasure method for T2I models. RACE utilizes a sophisticated adversarial training framework to identify and mitigate adversarial text embeddings, significantly reducing the Attack Success Rate (ASR). Impressively, RACE achieves a 30 percentage point reduction in ASR for the ``nudity'' concept against the leading white-box attack method. Our extensive evaluations demonstrate RACE's effectiveness in defending against both white-box and black-box attacks, marking a significant advancement in protecting T2I diffusion models from generating inappropriate or misleading imagery. This work underlines the essential need for proactive defense measures in adapting to the rapidly advancing field of adversarial challenges.