 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow do Self-Supervised Remote Sensing Vision Models Transfer to Downstream Tasks?
Jun 11, 2026Self-supervised geospatial foundation models (GeoFMs) learn transferable representations from remote sensing data, but their downstream behavior is difficult to characterize. We study six representative GeoFMs spanning joint-embedding, reconstruction, and multimodal pretraining families, and evaluate transfer across classification, regression, and segmentation benchmarks under different label availability and downstream pipelines. We find that model rankings change across tasks and adaptation settings. Layerwise probing shows that, in most cases, task-relevant information is more accessible in intermediate transformer blocks compared to final-layer embeddings, and that GeoFMs exhibit distinct depthwise profiles. In segmentation case studies on PASTIS and Sen1Floods11, downstream adaptation settings such as decoder design and fine-tuning can be as impactful as the choice of GeoFM, and standard dense-prediction heads may be poorly aligned with how GeoFMs organize information over depth. Finally, CKA analysis on case studies shows that fine-tuning does not rewrite GeoFMs uniformly across depth, and the strongest changes are localized to the first linear layer of the MLP in ViT blocks. These results help explain why GeoFM rankings shift across benchmarks and motivate more representation-aware evaluation and adaptation strategies.
A Proxy Consistency Loss for Grounded Fusion of Earth Observation and Location Encoders
Apr 20, 2026Supervised learning with Earth observation inputs is often limited by the sparsity of high-quality labeled or in-situ measured data to use as training labels. With the abundance of geographic data products, in many cases there are variables correlated with - but different from - the variable of interest that can be leveraged. We integrate such proxy variables within a geographic prior via a trainable location encoder and introduce a proxy consistency loss (PCL) formulation to imbue proxy data into the location encoder. The first key insight behind our approach is to use the location encoder as an agile and flexible way to learn from abundantly available proxy data which can be sampled independently of training label availability. Our second key insight is that we will need to regularize the location encoder appropriately to achieve performance and robustness with limited labeled data. Our experiments on air quality prediction and poverty mapping show that integrating proxy data implicitly through the location encoder outperforms using both as input to an observation encoder and fusion strategies that use frozen, pretrained location embeddings as a geographic prior. Superior performance for in-sample prediction shows that the PCL can incorporate rich information from the proxies, and superior out-of-sample prediction shows that the learned latent embeddings help generalize to areas without training labels.
Investigating the Effect of Spatial Context on Multi-Task Sea Ice Segmentation
Jul 28, 2025Capturing spatial context at multiple scales is crucial for deep learning-based sea ice segmentation. However, the optimal specification of spatial context based on observation resolution and task characteristics remains underexplored. This study investigates the impact of spatial context on the segmentation of sea ice concentration, stage of development, and floe size using a multi-task segmentation model. We implement Atrous Spatial Pyramid Pooling with varying atrous rates to systematically control the receptive field size of convolutional operations, and to capture multi-scale contextual information. We explore the interactions between spatial context and feature resolution for different sea ice properties and examine how spatial context influences segmentation performance across different input feature combinations from Sentinel-1 SAR and Advanced Microwave Radiometer-2 (AMSR2) for multi-task mapping. Using Gradient-weighted Class Activation Mapping, we visualize how atrous rates influence model decisions. Our findings indicate that smaller receptive fields excel for high-resolution Sentinel-1 data, while medium receptive fields yield better performances for stage of development segmentation and larger receptive fields often lead to diminished performances. The fusion of SAR and AMSR2 enhances segmentation across all tasks. We highlight the value of lower-resolution 18.7 and 36.5 GHz AMSR2 channels in sea ice mapping. These findings highlight the importance of selecting appropriate spatial context based on observation resolution and target properties in sea ice mapping. By systematically analyzing receptive field effects in a multi-task setting, our study provides insights for optimizing deep learning models in geospatial applications.
Integrating Spatiotemporal Features in LSTM for Spatially Informed COVID-19 Hospitalization Forecasting
Jun 06, 2025The COVID-19 pandemic's severe impact highlighted the need for accurate, timely hospitalization forecasting to support effective healthcare planning. However, most forecasting models struggled, especially during variant surges, when they were needed most. This study introduces a novel Long Short-Term Memory (LSTM) framework for forecasting daily state-level incident hospitalizations in the United States. We present a spatiotemporal feature, Social Proximity to Hospitalizations (SPH), derived from Facebook's Social Connectedness Index to improve forecasts. SPH serves as a proxy for interstate population interaction, capturing transmission dynamics across space and time. Our parallel LSTM architecture captures both short- and long-term temporal dependencies, and our multi-horizon ensembling strategy balances consistency and forecasting error. Evaluation against COVID-19 Forecast Hub ensemble models during the Delta and Omicron surges reveals superiority of our model. On average, our model surpasses the ensemble by 27, 42, 54, and 69 hospitalizations per state on the $7^{th}$, $14^{th}$, $21^{st}$, and $28^{th}$ forecast days, respectively, during the Omicron surge. Data-ablation experiments confirm SPH's predictive power, highlighting its effectiveness in enhancing forecasting models. This research not only advances hospitalization forecasting but also underscores the significance of spatiotemporal features, such as SPH, in refining predictive performance in modeling the complex dynamics of infectious disease spread.
Performance and Generalizability Impacts of Incorporating Geolocation into Deep Learning for Dynamic PM2.5 Estimation
May 24, 2025Deep learning models have demonstrated success in geospatial applications, yet quantifying the role of geolocation information in enhancing model performance and geographic generalizability remains underexplored. A new generation of location encoders have emerged with the goal of capturing attributes present at any given location for downstream use in predictive modeling. Being a nascent area of research, their evaluation has remained largely limited to static tasks such as species distributions or average temperature mapping. In this paper, we discuss and quantify the impact of incorporating geolocation into deep learning for a real-world application domain that is characteristically dynamic (with fast temporal change) and spatially heterogeneous at high resolutions: estimating surface-level daily PM2.5 levels using remotely sensed and ground-level data. We build on a recently published deep learning-based PM2.5 estimation model that achieves state-of-the-art performance on data observed in the contiguous United States. We examine three approaches for incorporating geolocation: excluding geolocation as a baseline, using raw geographic coordinates, and leveraging pretrained location encoders. We evaluate each approach under within-region (WR) and out-of-region (OoR) evaluation scenarios. Aggregate performance metrics indicate that while na\"ive incorporation of raw geographic coordinates improves within-region performance by retaining the interpolative value of geographic location, it can hinder generalizability across regions. In contrast, pretrained location encoders like GeoCLIP enhance predictive performance and geographic generalizability for both WR and OoR scenarios. However, qualitative analysis reveals artifact patterns caused by high-degree basis functions and sparse upstream samples in certain areas, and ablation results indicate varying performance among location encoders...
Exploring the Potential of Latent Embeddings for Sea Ice Characterization using ICESat-2 Data
Apr 25, 2025The Ice, Cloud, and Elevation Satellite-2 (ICESat-2) provides high-resolution measurements of sea ice height. Recent studies have developed machine learning methods on ICESat-2 data, primarily focusing on surface type classification. However, the heavy reliance on manually collected labels requires significant time and effort for supervised learning, as it involves cross-referencing track measurements with overlapping background optical imagery. Additionally, the coincidence of ICESat-2 tracks with background images is relatively rare due to the different overpass patterns and atmospheric conditions. To address these limitations, this study explores the potential of unsupervised autoencoder on unlabeled data to derive latent embeddings. We develop autoencoder models based on Long Short-Term Memory (LSTM) and Convolutional Neural Networks (CNN) to reconstruct topographic sequences from ICESat-2 and derive embeddings. We then apply Uniform Manifold Approximation and Projection (UMAP) to reduce dimensions and visualize the embeddings. Our results show that embeddings from autoencoders preserve the overall structure but generate relatively more compact clusters compared to the original ICESat-2 data, indicating the potential of embeddings to lessen the number of required labels samples.
A Genealogy of Multi-Sensor Foundation Models in Remote Sensing
Apr 24, 2025Foundation models have garnered increasing attention for representation learning in remote sensing, primarily adopting approaches that have demonstrated success in computer vision with minimal domain-specific modification. However, the development and application of foundation models in this field are still burgeoning, as there are a variety of competing approaches that each come with significant benefits and drawbacks. This paper examines these approaches along with their roots in the computer vision field in order to characterize potential advantages and pitfalls while outlining future directions to further improve remote sensing-specific foundation models. We discuss the quality of the learned representations and methods to alleviate the need for massive compute resources. We place emphasis on the multi-sensor aspect of Earth observations, and the extent to which existing approaches leverage multiple sensors in training foundation models in relation to multi-modal foundation models. Finally, we identify opportunities for further harnessing the vast amounts of unlabeled, seasonal, and multi-sensor remote sensing observations.
Assessing Foundation Models for Sea Ice Type Segmentation in Sentinel-1 SAR Imagery
Mar 28, 2025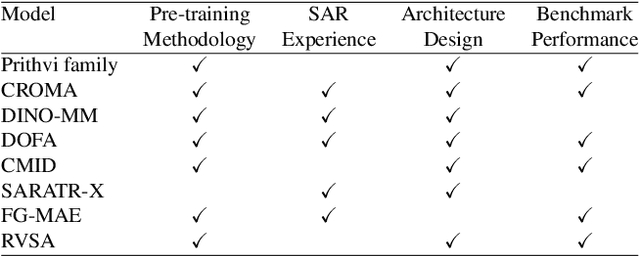
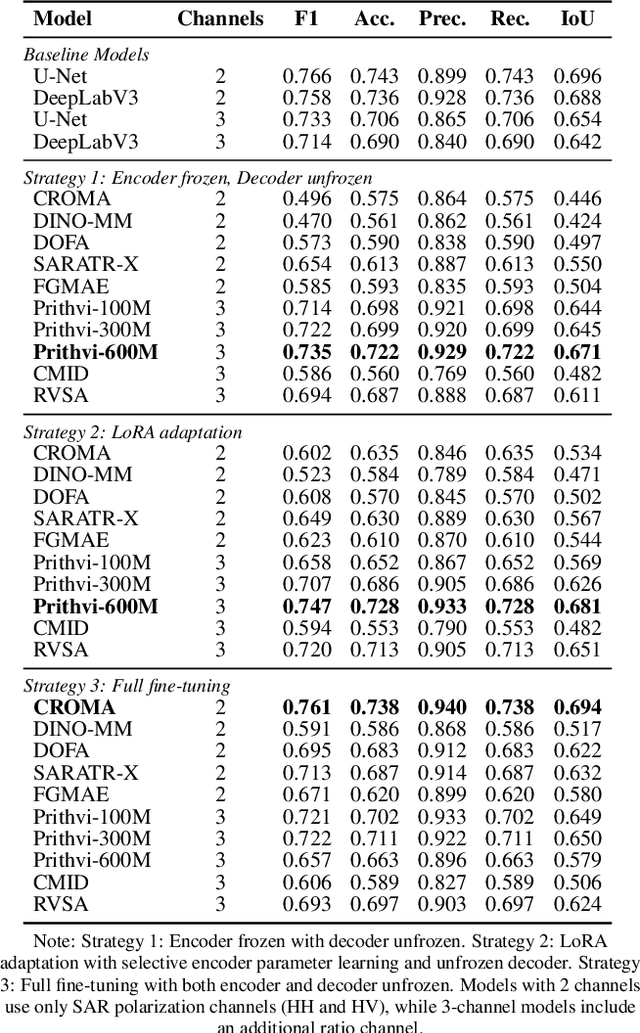
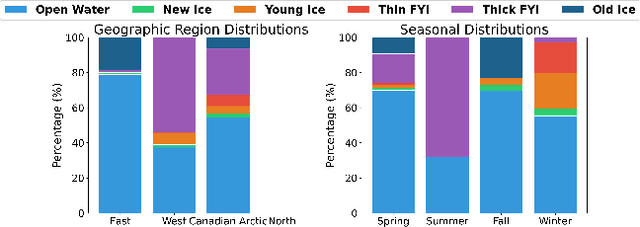
Accurate segmentation of sea ice types is essential for mapping and operational forecasting of sea ice conditions for safe navigation and resource extraction in ice-covered waters, as well as for understanding polar climate processes. While deep learning methods have shown promise in automating sea ice segmentation, they often rely on extensive labeled datasets which require expert knowledge and are time-consuming to create. Recently, foundation models (FMs) have shown excellent results for segmenting remote sensing images by utilizing pre-training on large datasets using self-supervised techniques. However, their effectiveness for sea ice segmentation remains unexplored, especially given sea ice's complex structures, seasonal changes, and unique spectral signatures, as well as peculiar Synthetic Aperture Radar (SAR) imagery characteristics including banding and scalloping noise, and varying ice backscatter characteristics, which are often missing in standard remote sensing pre-training datasets. In particular, SAR images over polar regions are acquired using different modes than used to capture the images at lower latitudes by the same sensors that form training datasets for FMs. This study evaluates ten remote sensing FMs for sea ice type segmentation using Sentinel-1 SAR imagery, focusing on their seasonal and spatial generalization. Among the selected models, Prithvi-600M outperforms the baseline models, while CROMA achieves a very similar performance in F1-score. Our contributions include offering a systematic methodology for selecting FMs for sea ice data analysis, a comprehensive benchmarking study on performances of FMs for sea ice segmentation with tailored performance metrics, and insights into existing gaps and future directions for improving domain-specific models in polar applications using SAR data.
Graph-Based Multimodal and Multi-view Alignment for Keystep Recognition
Jan 07, 2025Egocentric videos capture scenes from a wearer's viewpoint, resulting in dynamic backgrounds, frequent motion, and occlusions, posing challenges to accurate keystep recognition. We propose a flexible graph-learning framework for fine-grained keystep recognition that is able to effectively leverage long-term dependencies in egocentric videos, and leverage alignment between egocentric and exocentric videos during training for improved inference on egocentric videos. Our approach consists of constructing a graph where each video clip of the egocentric video corresponds to a node. During training, we consider each clip of each exocentric video (if available) as additional nodes. We examine several strategies to define connections across these nodes and pose keystep recognition as a node classification task on the constructed graphs. We perform extensive experiments on the Ego-Exo4D dataset and show that our proposed flexible graph-based framework notably outperforms existing methods by more than 12 points in accuracy. Furthermore, the constructed graphs are sparse and compute efficient. We also present a study examining on harnessing several multimodal features, including narrations, depth, and object class labels, on a heterogeneous graph and discuss their corresponding contribution to the keystep recognition performance.
Partial Label Learning with Focal Loss for Sea Ice Classification Based on Ice Charts
Jun 05, 2024



Sea ice, crucial to the Arctic and Earth's climate, requires consistent monitoring and high-resolution mapping. Manual sea ice mapping, however, is time-consuming and subjective, prompting the need for automated deep learning-based classification approaches. However, training these algorithms is challenging because expert-generated ice charts, commonly used as training data, do not map single ice types but instead map polygons with multiple ice types. Moreover, the distribution of various ice types in these charts is frequently imbalanced, resulting in a performance bias towards the dominant class. In this paper, we present a novel GeoAI approach to training sea ice classification by formalizing it as a partial label learning task with explicit confidence scores to address multiple labels and class imbalance. We treat the polygon-level labels as candidate partial labels, assign the corresponding ice concentrations as confidence scores to each candidate label, and integrate them with focal loss to train a Convolutional Neural Network (CNN). Our proposed approach leads to enhanced performance for sea ice classification in Sentinel-1 dual-polarized SAR images, improving classification accuracy (from 87% to 92%) and weighted average F-1 score (from 90% to 93%) compared to the conventional training approach of using one-hot encoded labels and Categorical Cross-Entropy loss. It also improves the F-1 score in 4 out of the 6 sea ice classes.