 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Effect of Spatial Context on Multi-Task Sea Ice Segmentation
Jul 28, 2025Capturing spatial context at multiple scales is crucial for deep learning-based sea ice segmentation. However, the optimal specification of spatial context based on observation resolution and task characteristics remains underexplored. This study investigates the impact of spatial context on the segmentation of sea ice concentration, stage of development, and floe size using a multi-task segmentation model. We implement Atrous Spatial Pyramid Pooling with varying atrous rates to systematically control the receptive field size of convolutional operations, and to capture multi-scale contextual information. We explore the interactions between spatial context and feature resolution for different sea ice properties and examine how spatial context influences segmentation performance across different input feature combinations from Sentinel-1 SAR and Advanced Microwave Radiometer-2 (AMSR2) for multi-task mapping. Using Gradient-weighted Class Activation Mapping, we visualize how atrous rates influence model decisions. Our findings indicate that smaller receptive fields excel for high-resolution Sentinel-1 data, while medium receptive fields yield better performances for stage of development segmentation and larger receptive fields often lead to diminished performances. The fusion of SAR and AMSR2 enhances segmentation across all tasks. We highlight the value of lower-resolution 18.7 and 36.5 GHz AMSR2 channels in sea ice mapping. These findings highlight the importance of selecting appropriate spatial context based on observation resolution and target properties in sea ice mapping. By systematically analyzing receptive field effects in a multi-task setting, our study provides insights for optimizing deep learning models in geospatial applications.
Partial Label Learning with Focal Loss for Sea Ice Classification Based on Ice Charts
Jun 05, 2024



Sea ice, crucial to the Arctic and Earth's climate, requires consistent monitoring and high-resolution mapping. Manual sea ice mapping, however, is time-consuming and subjective, prompting the need for automated deep learning-based classification approaches. However, training these algorithms is challenging because expert-generated ice charts, commonly used as training data, do not map single ice types but instead map polygons with multiple ice types. Moreover, the distribution of various ice types in these charts is frequently imbalanced, resulting in a performance bias towards the dominant class. In this paper, we present a novel GeoAI approach to training sea ice classification by formalizing it as a partial label learning task with explicit confidence scores to address multiple labels and class imbalance. We treat the polygon-level labels as candidate partial labels, assign the corresponding ice concentrations as confidence scores to each candidate label, and integrate them with focal loss to train a Convolutional Neural Network (CNN). Our proposed approach leads to enhanced performance for sea ice classification in Sentinel-1 dual-polarized SAR images, improving classification accuracy (from 87% to 92%) and weighted average F-1 score (from 90% to 93%) compared to the conventional training approach of using one-hot encoded labels and Categorical Cross-Entropy loss. It also improves the F-1 score in 4 out of the 6 sea ice classes.
Comparison of Cross-Entropy, Dice, and Focal Loss for Sea Ice Type Segmentation
Oct 26, 2023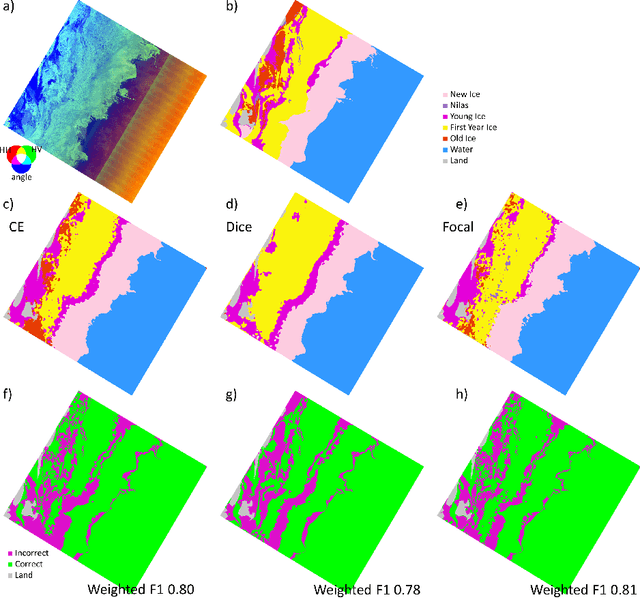
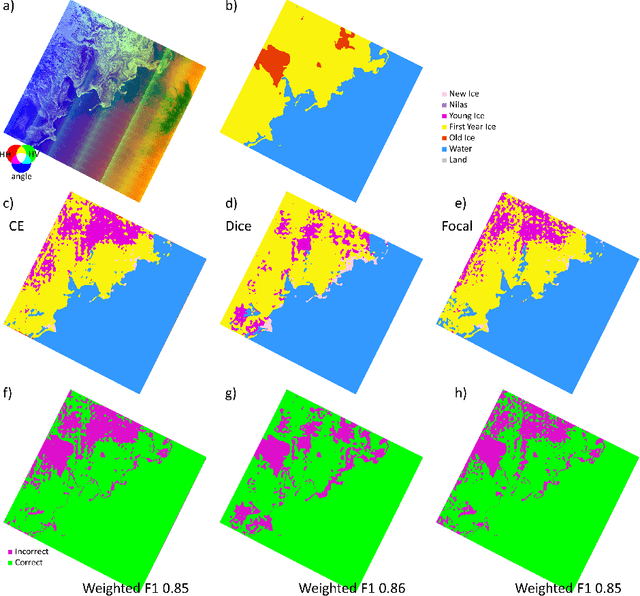
Up-to-date sea ice charts are crucial for safer navigation in ice-infested waters. Recently, Convolutional Neural Network (CNN) models show the potential to accelerate the generation of ice maps for large regions. However, results from CNN models still need to undergo scrutiny as higher metrics performance not always translate to adequate outputs. Sea ice type classes are imbalanced, requiring special treatment during training. We evaluate how three different loss functions, some developed for imbalanced class problems, affect the performance of CNN models trained to predict the dominant ice type in Sentinel-1 images. Despite the fact that Dice and Focal loss produce higher metrics, results from cross-entropy seem generally more physically consistent.
Enhancing sea ice segmentation in Sentinel-1 images with atrous convolutions
Oct 26, 2023Due to the growing volume of remote sensing data and the low latency required for safe marine navigation, machine learning (ML) algorithms are being developed to accelerate sea ice chart generation, currently a manual interpretation task. However, the low signal-to-noise ratio of the freely available Sentinel-1 Synthetic Aperture Radar (SAR) imagery, the ambiguity of backscatter signals for ice types, and the scarcity of open-source high-resolution labelled data makes automating sea ice mapping challenging. We use Extreme Earth version 2, a high-resolution benchmark dataset generated for ML training and evaluation, to investigate the effectiveness of ML for automated sea ice mapping. Our customized pipeline combines ResNets and Atrous Spatial Pyramid Pooling for SAR image segmentation. We investigate the performance of our model for: i) binary classification of sea ice and open water in a segmentation framework; and ii) a multiclass segmentation of five sea ice types. For binary ice-water classification, models trained with our largest training set have weighted F1 scores all greater than 0.95 for January and July test scenes. Specifically, the median weighted F1 score was 0.98, indicating high performance for both months. By comparison, a competitive baseline U-Net has a weighted average F1 score of ranging from 0.92 to 0.94 (median 0.93) for July, and 0.97 to 0.98 (median 0.97) for January. Multiclass ice type classification is more challenging, and even though our models achieve 2% improvement in weighted F1 average compared to the baseline U-Net, test weighted F1 is generally between 0.6 and 0.80. Our approach can efficiently segment full SAR scenes in one run, is faster than the baseline U-Net, retains spatial resolution and dimension, and is more robust against noise compared to approaches that rely on patch classification.
A spatiotemporal machine learning approach to forecasting COVID-19 incidence at the county level in the United States
Sep 27, 2021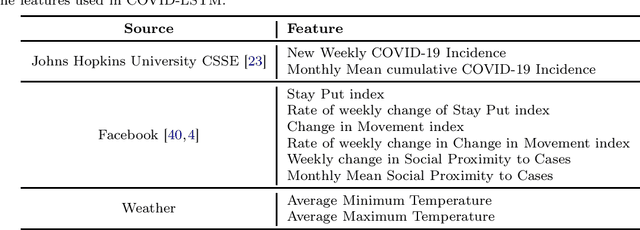


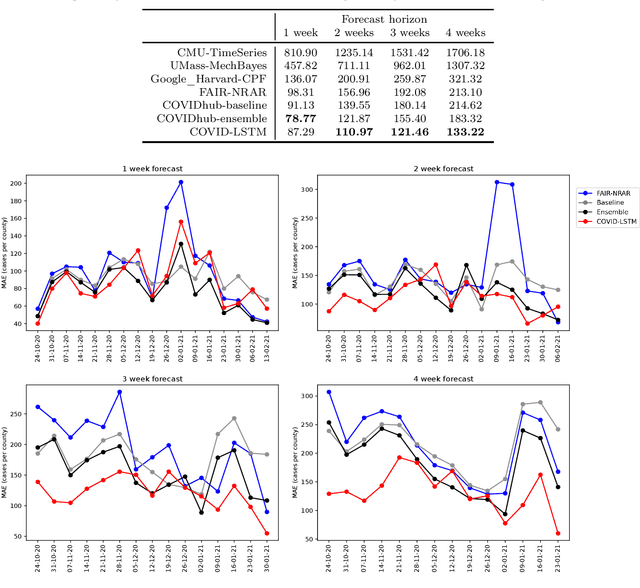
With COVID-19 affecting every country globally and changing everyday life, the ability to forecast the spread of the disease is more important than any previous epidemic. The conventional methods of disease-spread modeling, compartmental models, are based on the assumption of spatiotemporal homogeneity of the spread of the virus, which may cause forecasting to underperform, especially at high spatial resolutions. In this paper we approach the forecasting task with an alternative technique - spatiotemporal machine learning. We present COVID-LSTM, a data-driven model based on a Long Short-term Memory deep learning architecture for forecasting COVID-19 incidence at the county-level in the US. We use the weekly number of new positive cases as temporal input, and hand-engineered spatial features from Facebook movement and connectedness datasets to capture the spread of the disease in time and space. COVID-LSTM outperforms the COVID-19 Forecast Hub's Ensemble model (COVIDhub-ensemble) on our 17-week evaluation period, making it the first model to be more accurate than the COVIDhub-ensemble over one or more forecast periods. Over the 4-week forecast horizon, our model is on average 50 cases per county more accurate than the COVIDhub-ensemble. We highlight that the underutilization of data-driven forecasting of disease spread prior to COVID-19 is likely due to the lack of sufficient data available for previous diseases, in addition to the recent advances in machine learning methods for spatiotemporal forecasting. We discuss the impediments to the wider uptake of data-driven forecasting, and whether it is likely that more deep learning-based models will be used in the future.