 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSViTT-Ego: A Sparse Video-Text Transformer for Egocentric Video
Jun 13, 2024Pretraining egocentric vision-language models has become essential to improving downstream egocentric video-text tasks. These egocentric foundation models commonly use the transformer architecture. The memory footprint of these models during pretraining can be substantial. Therefore, we pretrain SViTT-Ego, the first sparse egocentric video-text transformer model integrating edge and node sparsification. We pretrain on the EgoClip dataset and incorporate the egocentric-friendly objective EgoNCE, instead of the frequently used InfoNCE. Most notably, SViTT-Ego obtains a +2.8% gain on EgoMCQ (intra-video) accuracy compared to LAVILA large, with no additional data augmentation techniques other than standard image augmentations, yet pretrainable on memory-limited devices.
Contrastive Language Video Time Pre-training
Jun 04, 2024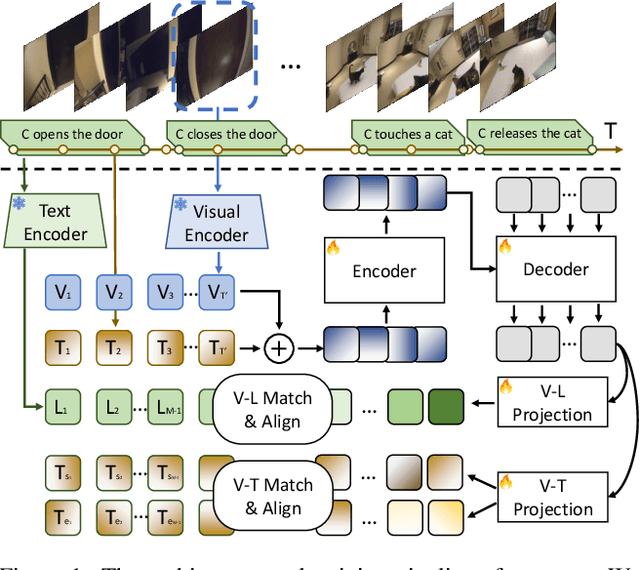
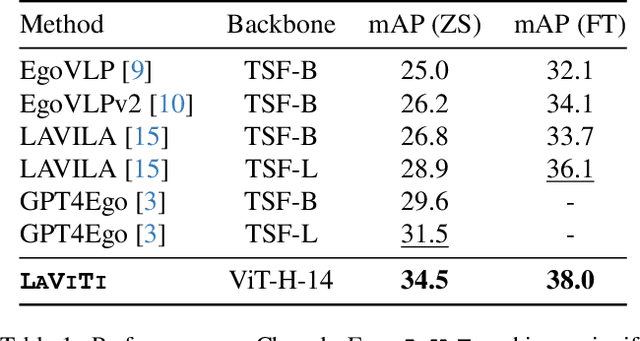

We introduce LAVITI, a novel approach to learning language, video, and temporal representations in long-form videos via contrastive learning. Different from pre-training on video-text pairs like EgoVLP, LAVITI aims to align language, video, and temporal features by extracting meaningful moments in untrimmed videos. Our model employs a set of learnable moment queries to decode clip-level visual, language, and temporal features. In addition to vision and language alignment, we introduce relative temporal embeddings (TE) to represent timestamps in videos, which enables contrastive learning of time. Significantly different from traditional approaches, the prediction of a particular timestamp is transformed by computing the similarity score between the predicted TE and all TEs. Furthermore, existing approaches for video understanding are mainly designed for short videos due to high computational complexity and memory footprint. Our method can be trained on the Ego4D dataset with only 8 NVIDIA RTX-3090 GPUs in a day. We validated our method on CharadesEgo action recognition, achieving state-of-the-art results.