 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeploying Multi-task Online Server with Large Language Model
Nov 07, 2024
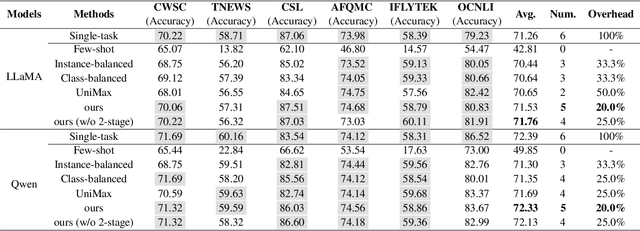
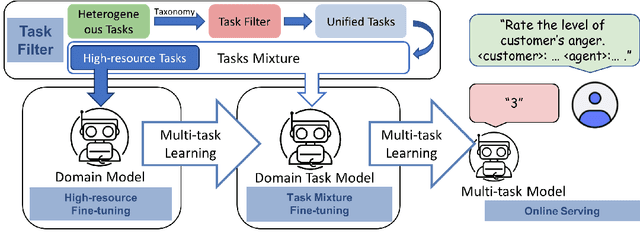

In the industry, numerous tasks are deployed online. Traditional approaches often tackle each task separately by its own network, which leads to excessive costs for developing and scaling models, especially in the context of large language models. Although multi-task methods can save costs through parameter sharing, they often struggle to outperform single-task methods in real-world applications. To tackle these challenges, we present a three-stage multi-task learning framework for large language models. It involves task filtering, followed by fine-tuning on high-resource tasks, and finally fine-tuning on all tasks. We conducted comprehensive experiments in single-task and multi-task settings. Our approach, exemplified on different benchmarks, demonstrates that it is able to achieve performance comparable to the single-task method while reducing up to 90.9\% of its overhead.
Contrastive Language Video Time Pre-training
Jun 04, 2024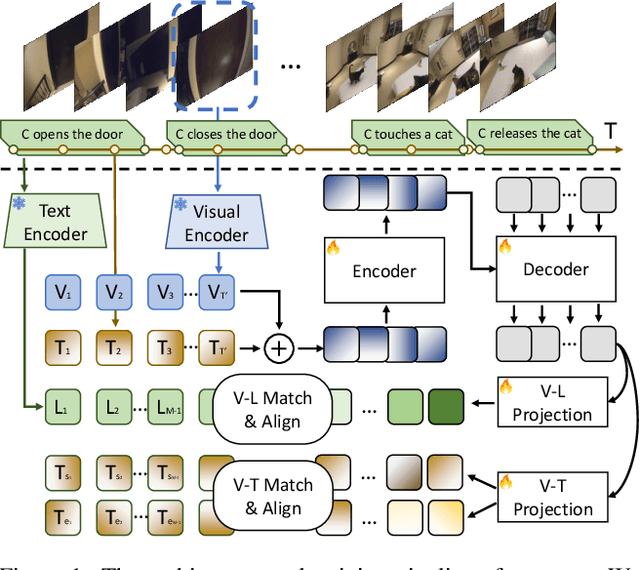
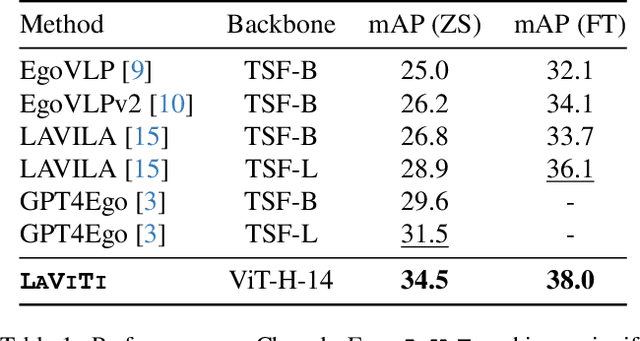

We introduce LAVITI, a novel approach to learning language, video, and temporal representations in long-form videos via contrastive learning. Different from pre-training on video-text pairs like EgoVLP, LAVITI aims to align language, video, and temporal features by extracting meaningful moments in untrimmed videos. Our model employs a set of learnable moment queries to decode clip-level visual, language, and temporal features. In addition to vision and language alignment, we introduce relative temporal embeddings (TE) to represent timestamps in videos, which enables contrastive learning of time. Significantly different from traditional approaches, the prediction of a particular timestamp is transformed by computing the similarity score between the predicted TE and all TEs. Furthermore, existing approaches for video understanding are mainly designed for short videos due to high computational complexity and memory footprint. Our method can be trained on the Ego4D dataset with only 8 NVIDIA RTX-3090 GPUs in a day. We validated our method on CharadesEgo action recognition, achieving state-of-the-art results.
RepSGG: Novel Representations of Entities and Relationships for Scene Graph Generation
Sep 06, 2023Scene Graph Generation (SGG) has achieved significant progress recently. However, most previous works rely heavily on fixed-size entity representations based on bounding box proposals, anchors, or learnable queries. As each representation's cardinality has different trade-offs between performance and computation overhead, extracting highly representative features efficiently and dynamically is both challenging and crucial for SGG. In this work, a novel architecture called RepSGG is proposed to address the aforementioned challenges, formulating a subject as queries, an object as keys, and their relationship as the maximum attention weight between pairwise queries and keys. With more fine-grained and flexible representation power for entities and relationships, RepSGG learns to sample semantically discriminative and representative points for relationship inference. Moreover, the long-tailed distribution also poses a significant challenge for generalization of SGG. A run-time performance-guided logit adjustment (PGLA) strategy is proposed such that the relationship logits are modified via affine transformations based on run-time performance during training. This strategy encourages a more balanced performance between dominant and rare classes. Experimental results show that RepSGG achieves the state-of-the-art or comparable performance on the Visual Genome and Open Images V6 datasets with fast inference speed, demonstrating the efficacy and efficiency of the proposed methods.
Fully Convolutional Scene Graph Generation
Mar 30, 2021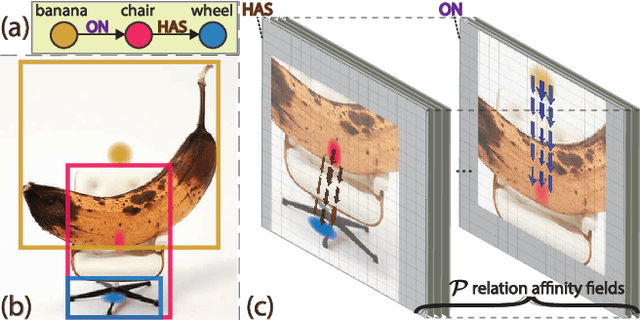
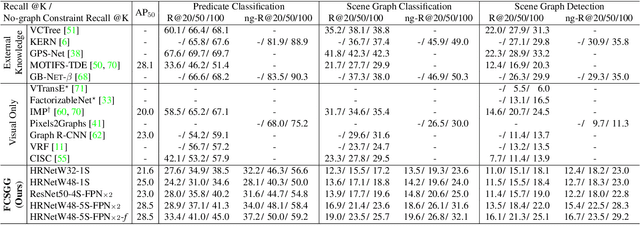
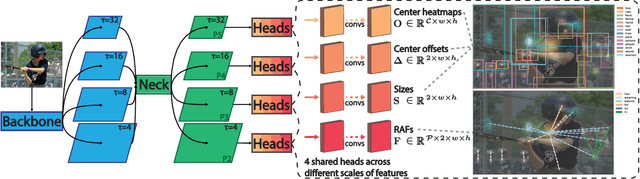
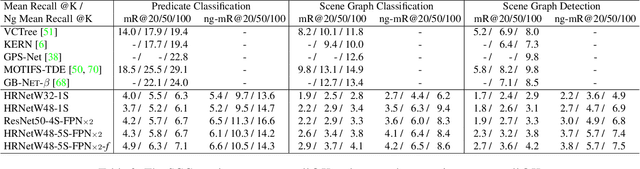
This paper presents a fully convolutional scene graph generation (FCSGG) model that detects objects and relations simultaneously. Most of the scene graph generation frameworks use a pre-trained two-stage object detector, like Faster R-CNN, and build scene graphs using bounding box features. Such pipeline usually has a large number of parameters and low inference speed. Unlike these approaches, FCSGG is a conceptually elegant and efficient bottom-up approach that encodes objects as bounding box center points, and relationships as 2D vector fields which are named as Relation Affinity Fields (RAFs). RAFs encode both semantic and spatial features, and explicitly represent the relationship between a pair of objects by the integral on a sub-region that points from subject to object. FCSGG only utilizes visual features and still generates strong results for scene graph generation. Comprehensive experiments on the Visual Genome dataset demonstrate the efficacy, efficiency, and generalizability of the proposed method. FCSGG achieves highly competitive results on recall and zero-shot recall with significantly reduced inference time.
Dynamically Throttleable Neural Networks (TNN)
Nov 01, 2020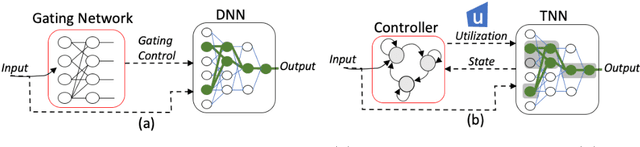


Conditional computation for Deep Neural Networks (DNNs) reduce overall computational load and improve model accuracy by running a subset of the network. In this work, we present a runtime throttleable neural network (TNN) that can adaptively self-regulate its own performance target and computing resources. We designed TNN with several properties that enable more flexibility for dynamic execution based on runtime context. TNNs are defined as throttleable modules gated with a separately trained controller that generates a single utilization control parameter. We validate our proposal on a number of experiments, including Convolution Neural Networks (CNNs such as VGG, ResNet, ResNeXt, DenseNet) using CiFAR-10 and ImageNet dataset, for object classification and recognition tasks. We also demonstrate the effectiveness of dynamic TNN execution on a 3D Convolustion Network (C3D) for a hand gesture task. Results show that TNN can maintain peak accuracy performance compared to vanilla solutions, while providing a graceful reduction in computational requirement, down to 74% reduction in latency and 52% energy savings.