 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeploying Multi-task Online Server with Large Language Model
Nov 07, 2024
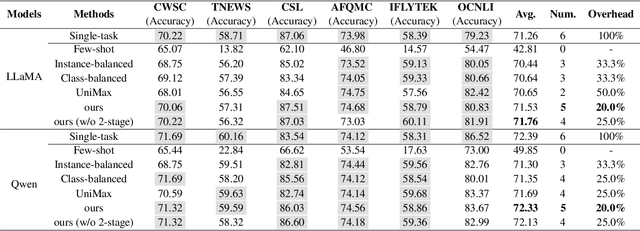
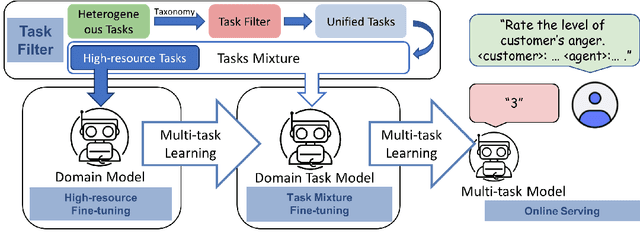

In the industry, numerous tasks are deployed online. Traditional approaches often tackle each task separately by its own network, which leads to excessive costs for developing and scaling models, especially in the context of large language models. Although multi-task methods can save costs through parameter sharing, they often struggle to outperform single-task methods in real-world applications. To tackle these challenges, we present a three-stage multi-task learning framework for large language models. It involves task filtering, followed by fine-tuning on high-resource tasks, and finally fine-tuning on all tasks. We conducted comprehensive experiments in single-task and multi-task settings. Our approach, exemplified on different benchmarks, demonstrates that it is able to achieve performance comparable to the single-task method while reducing up to 90.9\% of its overhead.
InBox: Recommendation with Knowledge Graph using Interest Box Embedding
Mar 19, 2024



Knowledge graphs (KGs) have become vitally important in modern recommender systems, effectively improving performance and interpretability. Fundamentally, recommender systems aim to identify user interests based on historical interactions and recommend suitable items. However, existing works overlook two key challenges: (1) an interest corresponds to a potentially large set of related items, and (2) the lack of explicit, fine-grained exploitation of KG information and interest connectivity. This leads to an inability to reflect distinctions between entities and interests when modeling them in a single way. Additionally, the granularity of concepts in the knowledge graphs used for recommendations tends to be coarse, failing to match the fine-grained nature of user interests. This homogenization limits the precise exploitation of knowledge graph data and interest connectivity. To address these limitations, we introduce a novel embedding-based model called InBox. Specifically, various knowledge graph entities and relations are embedded as points or boxes, while user interests are modeled as boxes encompassing interaction history. Representing interests as boxes enables containing collections of item points related to that interest. We further propose that an interest comprises diverse basic concepts, and box intersection naturally supports concept combination. Across three training steps, InBox significantly outperforms state-of-the-art methods like HAKG and KGIN on recommendation tasks. Further analysis provides meaningful insights into the variable value of different KG data for recommendations. In summary, InBox advances recommender systems through box-based interest and concept modeling for sophisticated knowledge graph exploitation.
Commonsense Knowledge Salience Evaluation with a Benchmark Dataset in E-commerce
May 22, 2022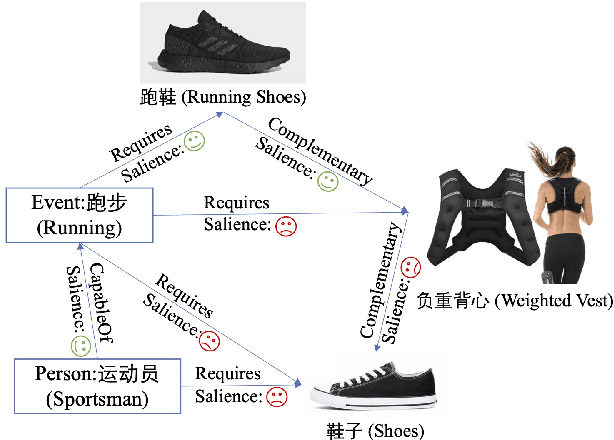


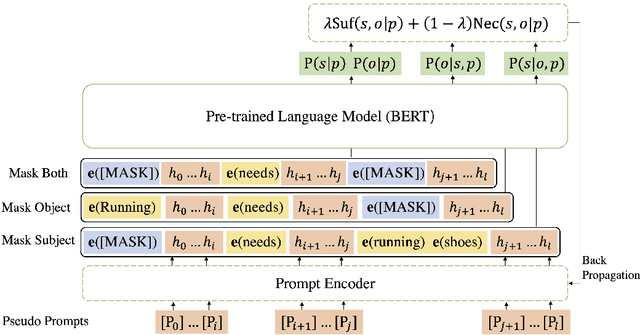
In e-commerce, the salience of commonsense knowledge (CSK) is beneficial for widespread applications such as product search and recommendation. For example, when users search for "running" in e-commerce, they would like to find items highly related to running, such as "running shoes" rather than "shoes". However, many existing CSK collections rank statements solely by confidence scores, and there is no information about which ones are salient from a human perspective. In this work, we define the task of supervised salience evaluation, where given a CSK triple, the model is required to learn whether the triple is salient or not. In addition to formulating the new task, we also release a new Benchmark dataset of Salience Evaluation in E-commerce (BSEE) and hope to promote related research on commonsense knowledge salience evaluation. We conduct experiments in the dataset with several representative baseline models. The experimental results show that salience evaluation is a hard task where models perform poorly on our evaluation set. We further propose a simple but effective approach, PMI-tuning, which shows promise for solving this novel problem.
SQUIRE: A Sequence-to-sequence Framework for Multi-hop Knowledge Graph Reasoning
Jan 17, 2022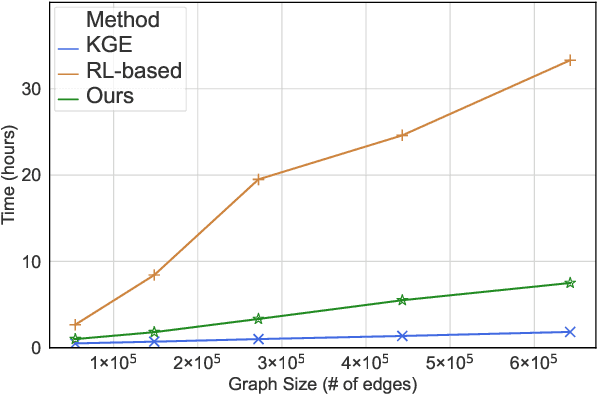
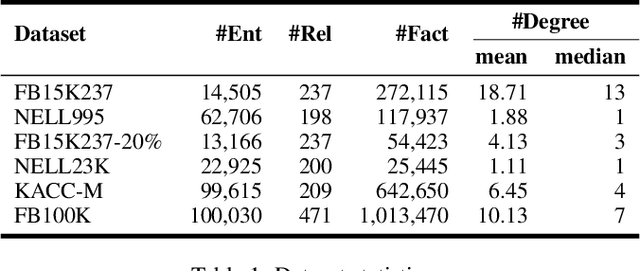
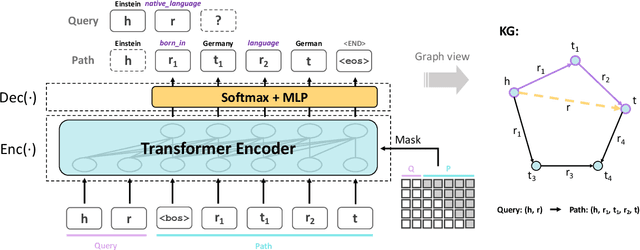
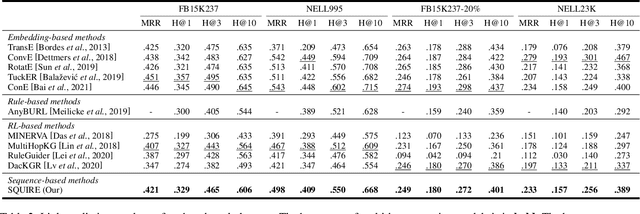
Multi-hop knowledge graph (KG) reasoning has been widely studied in recent years to provide interpretable predictions on missing links. Given a triple query, multi-hop reasoning task aims to give an evidential path that indicates the inference process. Most previous works use reinforcement learning (RL) based method that learns to navigate the path towards the target entity. However, these methods suffer from slow and poor convergence, and they may fail to infer a certain path when there is a missing edge along the path. Here we present SQUIRE, the first Sequence-to-sequence based multi-hop reasoning framework, which utilizes an encoder-decoder structure to translate the query to a path. Our model design brings about two benefits: (1) It can learn and predict in an end-to-end fashion, which gives better and faster convergence; (2) Our model does not rely on existing edges to generate the path, and has the flexibility to complete missing edges along the path, especially in sparse KGs. Experiments on standard and sparse KGs show that our approach yields significant improvement over prior methods, while converging 4x-7x faster.