 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeploying Multi-task Online Server with Large Language Model
Nov 07, 2024
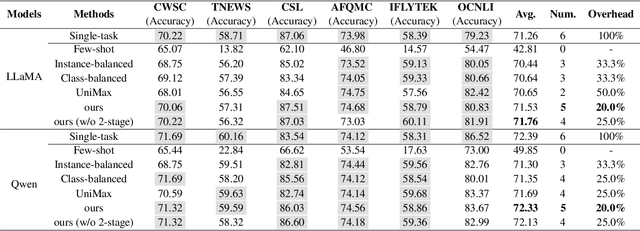
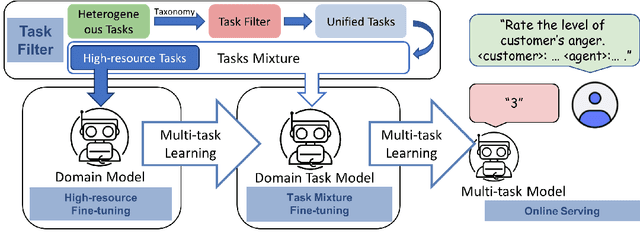

In the industry, numerous tasks are deployed online. Traditional approaches often tackle each task separately by its own network, which leads to excessive costs for developing and scaling models, especially in the context of large language models. Although multi-task methods can save costs through parameter sharing, they often struggle to outperform single-task methods in real-world applications. To tackle these challenges, we present a three-stage multi-task learning framework for large language models. It involves task filtering, followed by fine-tuning on high-resource tasks, and finally fine-tuning on all tasks. We conducted comprehensive experiments in single-task and multi-task settings. Our approach, exemplified on different benchmarks, demonstrates that it is able to achieve performance comparable to the single-task method while reducing up to 90.9\% of its overhead.