 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIAL: Decoupling Intent and Action via Latent World Modeling for End-to-End VLA
Mar 31, 2026The development of Vision-Language-Action (VLA) models has been significantly accelerated by pre-trained Vision-Language Models (VLMs). However, most existing end-to-end VLAs treat the VLM primarily as a multimodal encoder, directly mapping vision-language features to low-level actions. This paradigm underutilizes the VLM's potential in high-level decision making and introduces training instability, frequently degrading its rich semantic representations. To address these limitations, we introduce DIAL, a framework bridging high-level decision making and low-level motor execution through a differentiable latent intent bottleneck. Specifically, a VLM-based System-2 performs latent world modeling by synthesizing latent visual foresight within the VLM's native feature space; this foresight explicitly encodes intent and serves as the structural bottleneck. A lightweight System-1 policy then decodes this predicted intent together with the current observation into precise robot actions via latent inverse dynamics. To ensure optimization stability, we employ a two-stage training paradigm: a decoupled warmup phase where System-2 learns to predict latent futures while System-1 learns motor control under ground-truth future guidance within a unified feature space, followed by seamless end-to-end joint optimization. This enables action-aware gradients to refine the VLM backbone in a controlled manner, preserving pre-trained knowledge. Extensive experiments on the RoboCasa GR1 Tabletop benchmark show that DIAL establishes a new state-of-the-art, achieving superior performance with 10x fewer demonstrations than prior methods. Furthermore, by leveraging heterogeneous human demonstrations, DIAL learns physically grounded manipulation priors and exhibits robust zero-shot generalization to unseen objects and novel configurations during real-world deployment on a humanoid robot.
PosterVerse: A Full-Workflow Framework for Commercial-Grade Poster Generation with HTML-Based Scalable Typography
Jan 07, 2026Commercial-grade poster design demands the seamless integration of aesthetic appeal with precise, informative content delivery. Current automated poster generation systems face significant limitations, including incomplete design workflows, poor text rendering accuracy, and insufficient flexibility for commercial applications. To address these challenges, we propose PosterVerse, a full-workflow, commercial-grade poster generation method that seamlessly automates the entire design process while delivering high-density and scalable text rendering. PosterVerse replicates professional design through three key stages: (1) blueprint creation using fine-tuned LLMs to extract key design elements from user requirements, (2) graphical background generation via customized diffusion models to create visually appealing imagery, and (3) unified layout-text rendering with an MLLM-powered HTML engine to guarantee high text accuracy and flexible customization. In addition, we introduce PosterDNA, a commercial-grade, HTML-based dataset tailored for training and validating poster design models. To the best of our knowledge, PosterDNA is the first Chinese poster generation dataset to introduce HTML typography files, enabling scalable text rendering and fundamentally solving the challenges of rendering small and high-density text. Experimental results demonstrate that PosterVerse consistently produces commercial-grade posters with appealing visuals, accurate text alignment, and customizable layouts, making it a promising solution for automating commercial poster design. The code and model are available at https://github.com/wuhaer/PosterVerse.
Bohrium + SciMaster: Building the Infrastructure and Ecosystem for Agentic Science at Scale
Dec 23, 2025



AI agents are emerging as a practical way to run multi-step scientific workflows that interleave reasoning with tool use and verification, pointing to a shift from isolated AI-assisted steps toward \emph{agentic science at scale}. This shift is increasingly feasible, as scientific tools and models can be invoked through stable interfaces and verified with recorded execution traces, and increasingly necessary, as AI accelerates scientific output and stresses the peer-review and publication pipeline, raising the bar for traceability and credible evaluation. However, scaling agentic science remains difficult: workflows are hard to observe and reproduce; many tools and laboratory systems are not agent-ready; execution is hard to trace and govern; and prototype AI Scientist systems are often bespoke, limiting reuse and systematic improvement from real workflow signals. We argue that scaling agentic science requires an infrastructure-and-ecosystem approach, instantiated in Bohrium+SciMaster. Bohrium acts as a managed, traceable hub for AI4S assets -- akin to a HuggingFace of AI for Science -- that turns diverse scientific data, software, compute, and laboratory systems into agent-ready capabilities. SciMaster orchestrates these capabilities into long-horizon scientific workflows, on which scientific agents can be composed and executed. Between infrastructure and orchestration, a \emph{scientific intelligence substrate} organizes reusable models, knowledge, and components into executable building blocks for workflow reasoning and action, enabling composition, auditability, and improvement through use. We demonstrate this stack with eleven representative master agents in real workflows, achieving orders-of-magnitude reductions in end-to-end scientific cycle time and generating execution-grounded signals from real workloads at multi-million scale.
Native-AI Empowered Scalable Architectures and Solutions for Future Non-Terrestrial Networks: An Overview
Jul 16, 2025As the path toward 6G networks is being charted, the emerging applications have motivated evolutions of network architectures to realize the efficient, reliable, and flexible wireless networks. Among the potential architectures, the non-terrestrial network (NTN) and open radio access network (ORAN) have received increasing interest from both academia and industry. Although the deployment of NTNs ensures coverage, enhances spectral efficiency, and improves the resilience of wireless networks. The high altitude and mobility of NTN present new challenges in the development and operations (DevOps) lifecycle, hindering intelligent and scalable network management due to the lack of native artificial intelligence (AI) capability. With the advantages of ORAN in disaggregation, openness, virtualization, and intelligence, several works propose integrating ORAN principles into the NTN, focusing mainly on ORAN deployment options based on transparent and regenerative systems. However, a holistic view of how to effectively combine ORAN and NTN throughout the DevOps lifecycle is still missing, especially regarding how intelligent ORAN addresses the scalability challenges in NTN. Motivated by this, in this paper, we first provide the background knowledge about ORAN and NTN, outline the state-of-the-art research on ORAN for NTNs, and present the DevOps challenges that motivate the adoption of ORAN solutions. We then propose the ORAN-based NTN framework, discussing its features and architectures in detail. These include the discussion about flexible fronthaul split, RAN intelligent controllers (RICs) enhancement for distributed learning, scalable deployment architecture, and multi-domain service management. Finally, the future research directions, including combinations of the ORAN-based NTN framework and other enabling technologies and schemes, as well as the candidate use cases, are highlighted.
A Clinician-Friendly Platform for Ophthalmic Image Analysis Without Technical Barriers
Apr 22, 2025Artificial intelligence (AI) shows remarkable potential in medical imaging diagnostics, but current models typically require retraining when deployed across different clinical centers, limiting their widespread adoption. We introduce GlobeReady, a clinician-friendly AI platform that enables ocular disease diagnosis without retraining/fine-tuning or technical expertise. GlobeReady achieves high accuracy across imaging modalities: 93.9-98.5% for an 11-category fundus photo dataset and 87.2-92.7% for a 15-category OCT dataset. Through training-free local feature augmentation, it addresses domain shifts across centers and populations, reaching an average accuracy of 88.9% across five centers in China, 86.3% in Vietnam, and 90.2% in the UK. The built-in confidence-quantifiable diagnostic approach further boosted accuracy to 94.9-99.4% (fundus) and 88.2-96.2% (OCT), while identifying out-of-distribution cases at 86.3% (49 CFP categories) and 90.6% (13 OCT categories). Clinicians from multiple countries rated GlobeReady highly (average 4.6 out of 5) for its usability and clinical relevance. These results demonstrate GlobeReady's robust, scalable diagnostic capability and potential to support ophthalmic care without technical barriers.
Exposing the Copycat Problem of Imitation-based Planner: A Novel Closed-Loop Simulator, Causal Benchmark and Joint IL-RL Baseline
Apr 20, 2025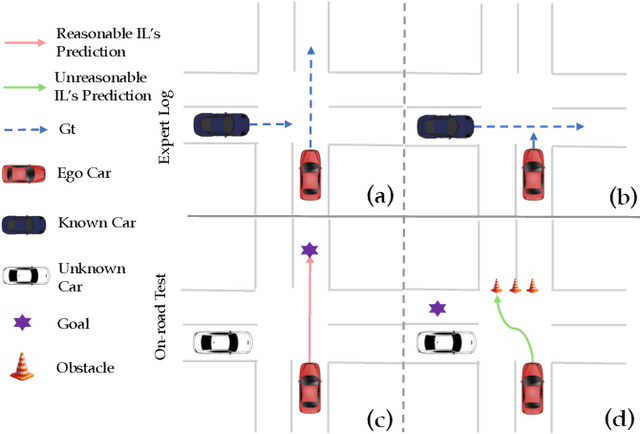
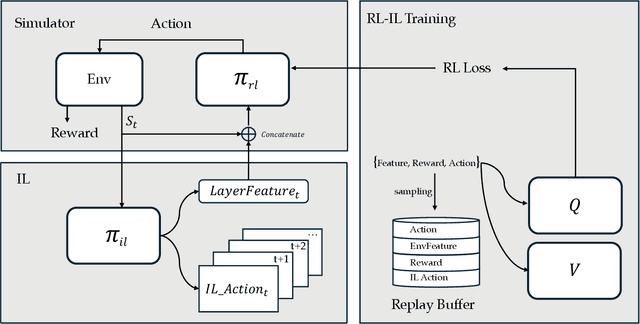
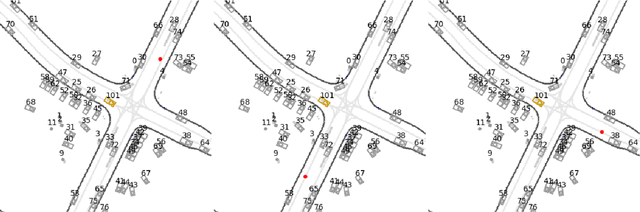
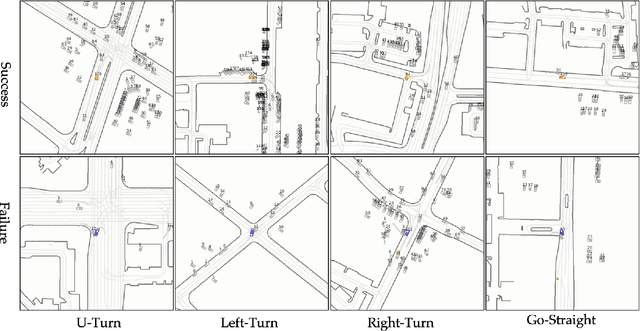
Machine learning (ML)-based planners have recently gained significant attention. They offer advantages over traditional optimization-based planning algorithms. These advantages include fewer manually selected parameters and faster development. Within ML-based planning, imitation learning (IL) is a common algorithm. It primarily learns driving policies directly from supervised trajectory data. While IL has demonstrated strong performance on many open-loop benchmarks, it remains challenging to determine if the learned policy truly understands fundamental driving principles, rather than simply extrapolating from the ego-vehicle's initial state. Several studies have identified this limitation and proposed algorithms to address it. However, these methods often use original datasets for evaluation. In these datasets, future trajectories are heavily dependent on initial conditions. Furthermore, IL often overfits to the most common scenarios. It struggles to generalize to rare or unseen situations. To address these challenges, this work proposes: 1) a novel closed-loop simulator supporting both imitation and reinforcement learning, 2) a causal benchmark derived from the Waymo Open Dataset to rigorously assess the impact of the copycat problem, and 3) a novel framework integrating imitation learning and reinforcement learning to overcome the limitations of purely imitative approaches. The code for this work will be released soon.
Breaking Through the Spike: Spike Window Decoding for Accelerated and Precise Automatic Speech Recognition
Jan 01, 2025



Recently, end-to-end automatic speech recognition has become the mainstream approach in both industry and academia. To optimize system performance in specific scenarios, the Weighted Finite-State Transducer (WFST) is extensively used to integrate acoustic and language models, leveraging its capacity to implicitly fuse language models within static graphs, thereby ensuring robust recognition while also facilitating rapid error correction. However, WFST necessitates a frame-by-frame search of CTC posterior probabilities through autoregression, which significantly hampers inference speed. In this work, we thoroughly investigate the spike property of CTC outputs and further propose the conjecture that adjacent frames to non-blank spikes carry semantic information beneficial to the model. Building on this, we propose the Spike Window Decoding algorithm, which greatly improves the inference speed by making the number of frames decoded in WFST linearly related to the number of spiking frames in the CTC output, while guaranteeing the recognition performance. Our method achieves SOTA recognition accuracy with significantly accelerates decoding speed, proven across both AISHELL-1 and large-scale In-House datasets, establishing a pioneering approach for integrating CTC output with WFST.
A General Sensing-assisted Channel Estimation Framework in Distributed MIMO Network
Nov 24, 2024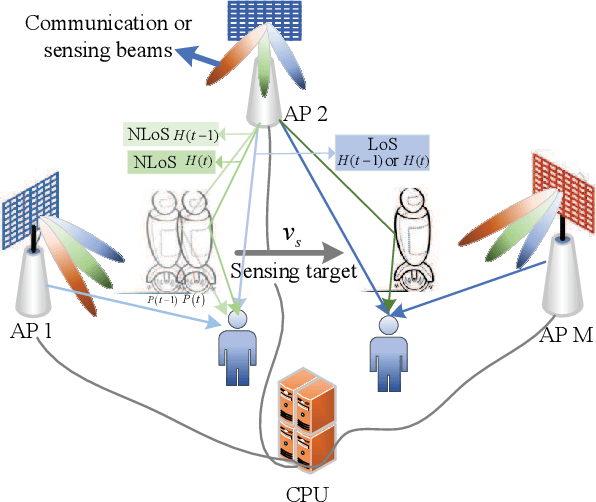
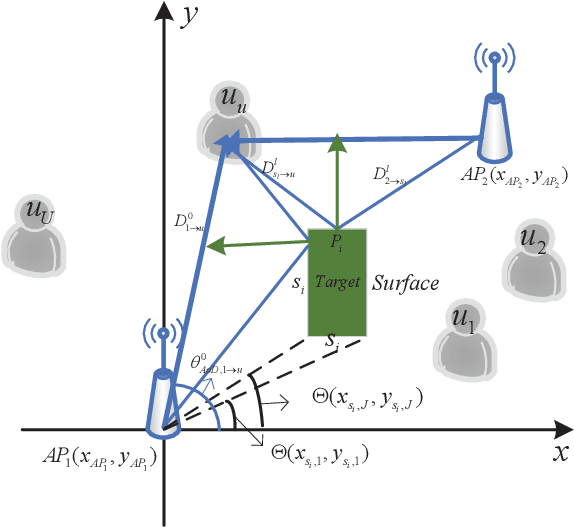
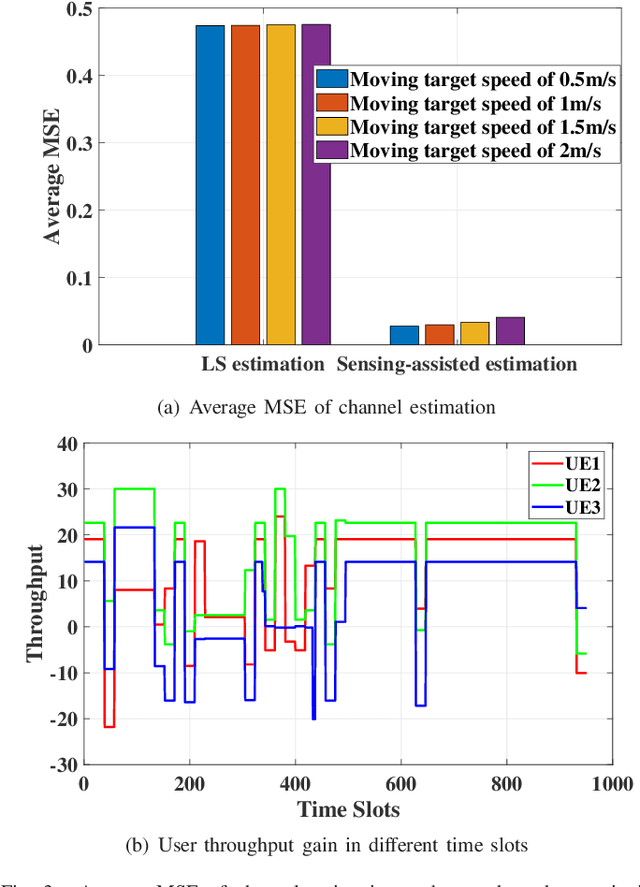
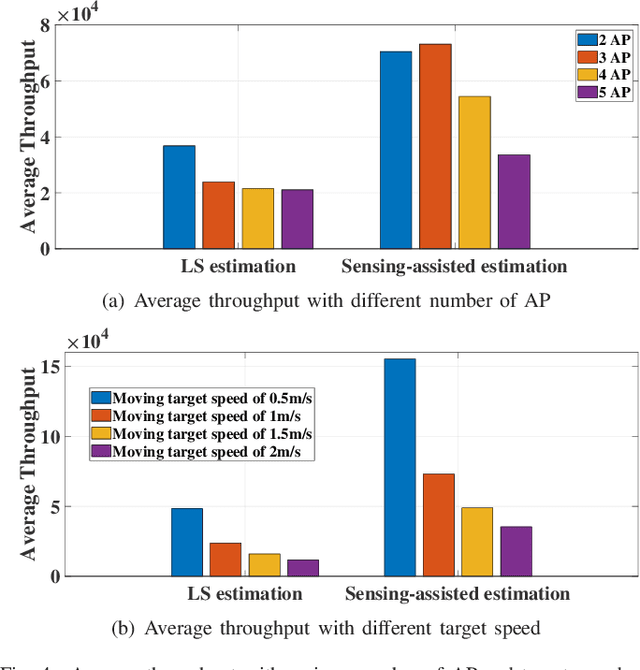
Joint sensing and communication (JSC) research direction has been envisioned to be a key technology in 6G communications, which has the potential to equip the traditional base station with sensing capability by fully exploiting the existing wireless communication infrastructures. To further enhance wireless communication performance in JSC, sensing-assisted communication has attracted attention from both industry and academia. However, most existing papers focused on sensing-assisted communication under line-of-sight (LoS) scenarios due to sensing limitations, where the sensing target and communication user remain the same. In this paper, we propose a general sensing-assisted channel estimation framework, where the channel estimation accuracy for both Los and non-line-of-sight (NLoS) are considered. Simulation results demonstrate that our proposed sensing-assisted communication framework achieves higher channel estimation accuracy and throughput compared to the traditional least-square (LS) estimation. More importantly, the feasibility of the proposed framework has been validated to solve the complex channel estimation challenge in distributed multiple input and multiple output (MIMO) network.
Deploying Multi-task Online Server with Large Language Model
Nov 07, 2024
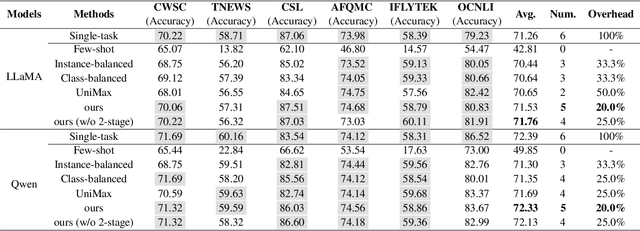
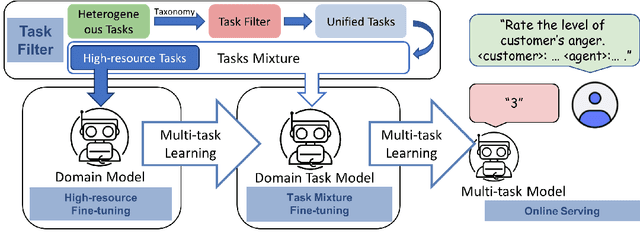

In the industry, numerous tasks are deployed online. Traditional approaches often tackle each task separately by its own network, which leads to excessive costs for developing and scaling models, especially in the context of large language models. Although multi-task methods can save costs through parameter sharing, they often struggle to outperform single-task methods in real-world applications. To tackle these challenges, we present a three-stage multi-task learning framework for large language models. It involves task filtering, followed by fine-tuning on high-resource tasks, and finally fine-tuning on all tasks. We conducted comprehensive experiments in single-task and multi-task settings. Our approach, exemplified on different benchmarks, demonstrates that it is able to achieve performance comparable to the single-task method while reducing up to 90.9\% of its overhead.
Towards Reflected Object Detection: A Benchmark
Jul 08, 2024



Object detection has greatly improved over the past decade thanks to advances in deep learning and large-scale datasets. However, detecting objects reflected in surfaces remains an underexplored area. Reflective surfaces are ubiquitous in daily life, appearing in homes, offices, public spaces, and natural environments. Accurate detection and interpretation of reflected objects are essential for various applications. This paper addresses this gap by introducing a extensive benchmark specifically designed for Reflected Object Detection. Our Reflected Object Detection Dataset (RODD) features a diverse collection of images showcasing reflected objects in various contexts, providing standard annotations for both real and reflected objects. This distinguishes it from traditional object detection benchmarks. RODD encompasses 10 categories and includes 21,059 images of real and reflected objects across different backgrounds, complete with standard bounding box annotations and the classification of objects as real or reflected. Additionally, we present baseline results by adapting five state-of-the-art object detection models to address this challenging task. Experimental results underscore the limitations of existing methods when applied to reflected object detection, highlighting the need for specialized approaches. By releasing RODD, we aim to support and advance future research on detecting reflected objects. Dataset and code are available at: https: //github.com/Tqybu-hans/RODD.