 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePALM-Bench: A Comprehensive Benchmark for Personalized Audio-Language Models
Jan 07, 2026Large Audio-Language Models (LALMs) have demonstrated strong performance in audio understanding and generation. Yet, our extensive benchmarking reveals that their behavior is largely generic (e.g., summarizing spoken content) and fails to adequately support personalized question answering (e.g., summarizing what my best friend says). In contrast, human conditions their interpretation and decision-making on each individual's personal context. To bridge this gap, we formalize the task of Personalized LALMs (PALM) for recognizing personal concepts and reasoning within personal context. Moreover, we create the first benchmark (PALM-Bench) to foster the methodological advances in PALM and enable structured evaluation on several tasks across multi-speaker scenarios. Our extensive experiments on representative open-source LALMs, show that existing training-free prompting and supervised fine-tuning strategies, while yield improvements, remains limited in modeling personalized knowledge and transferring them across tasks robustly. Data and code will be released.
IKFST: IOO and KOO Algorithms for Accelerated and Precise WFST-based End-to-End Automatic Speech Recognition
Jan 01, 2026End-to-end automatic speech recognition has become the dominant paradigm in both academia and industry. To enhance recognition performance, the Weighted Finite-State Transducer (WFST) is widely adopted to integrate acoustic and language models through static graph composition, providing robust decoding and effective error correction. However, WFST decoding relies on a frame-by-frame autoregressive search over CTC posterior probabilities, which severely limits inference efficiency. Motivated by establishing a more principled compatibility between WFST decoding and CTC modeling, we systematically study the two fundamental components of CTC outputs, namely blank and non-blank frames, and identify a key insight: blank frames primarily encode positional information, while non-blank frames carry semantic content. Building on this observation, we introduce Keep-Only-One and Insert-Only-One, two decoding algorithms that explicitly exploit the structural roles of blank and non-blank frames to achieve significantly faster WFST-based inference without compromising recognition accuracy. Experiments on large-scale in-house, AISHELL-1, and LibriSpeech datasets demonstrate state-of-the-art recognition accuracy with substantially reduced decoding latency, enabling truly efficient and high-performance WFST decoding in modern speech recognition systems.
FaceSpeak: Expressive and High-Quality Speech Synthesis from Human Portraits of Different Styles
Jan 02, 2025



Humans can perceive speakers' characteristics (e.g., identity, gender, personality and emotion) by their appearance, which are generally aligned to their voice style. Recently, vision-driven Text-to-speech (TTS) scholars grounded their investigations on real-person faces, thereby restricting effective speech synthesis from applying to vast potential usage scenarios with diverse characters and image styles. To solve this issue, we introduce a novel FaceSpeak approach. It extracts salient identity characteristics and emotional representations from a wide variety of image styles. Meanwhile, it mitigates the extraneous information (e.g., background, clothing, and hair color, etc.), resulting in synthesized speech closely aligned with a character's persona. Furthermore, to overcome the scarcity of multi-modal TTS data, we have devised an innovative dataset, namely Expressive Multi-Modal TTS, which is diligently curated and annotated to facilitate research in this domain. The experimental results demonstrate our proposed FaceSpeak can generate portrait-aligned voice with satisfactory naturalness and quality.
Breaking Through the Spike: Spike Window Decoding for Accelerated and Precise Automatic Speech Recognition
Jan 01, 2025



Recently, end-to-end automatic speech recognition has become the mainstream approach in both industry and academia. To optimize system performance in specific scenarios, the Weighted Finite-State Transducer (WFST) is extensively used to integrate acoustic and language models, leveraging its capacity to implicitly fuse language models within static graphs, thereby ensuring robust recognition while also facilitating rapid error correction. However, WFST necessitates a frame-by-frame search of CTC posterior probabilities through autoregression, which significantly hampers inference speed. In this work, we thoroughly investigate the spike property of CTC outputs and further propose the conjecture that adjacent frames to non-blank spikes carry semantic information beneficial to the model. Building on this, we propose the Spike Window Decoding algorithm, which greatly improves the inference speed by making the number of frames decoded in WFST linearly related to the number of spiking frames in the CTC output, while guaranteeing the recognition performance. Our method achieves SOTA recognition accuracy with significantly accelerates decoding speed, proven across both AISHELL-1 and large-scale In-House datasets, establishing a pioneering approach for integrating CTC output with WFST.
I2TTS: Image-indicated Immersive Text-to-speech Synthesis with Spatial Perception
Nov 20, 2024Controlling the style and characteristics of speech synthesis is crucial for adapting the output to specific contexts and user requirements. Previous Text-to-speech (TTS) works have focused primarily on the technical aspects of producing natural-sounding speech, such as intonation, rhythm, and clarity. However, they overlook the fact that there is a growing emphasis on spatial perception of synthesized speech, which may provide immersive experience in gaming and virtual reality. To solve this issue, in this paper, we present a novel multi-modal TTS approach, namely Image-indicated Immersive Text-to-speech Synthesis (I2TTS). Specifically, we introduce a scene prompt encoder that integrates visual scene prompts directly into the synthesis pipeline to control the speech generation process. Additionally, we propose a reverberation classification and refinement technique that adjusts the synthesized mel-spectrogram to enhance the immersive experience, ensuring that the involved reverberation condition matches the scene accurately. Experimental results demonstrate that our model achieves high-quality scene and spatial matching without compromising speech naturalness, marking a significant advancement in the field of context-aware speech synthesis. Project demo page: https://spatialTTS.github.io/ Index Terms-Speech synthesis, scene prompt, spatial perception
Improving Zero-Shot Chinese-English Code-Switching ASR with kNN-CTC and Gated Monolingual Datastores
Jun 06, 2024



The kNN-CTC model has proven to be effective for monolingual automatic speech recognition (ASR). However, its direct application to multilingual scenarios like code-switching, presents challenges. Although there is potential for performance improvement, a kNN-CTC model utilizing a single bilingual datastore can inadvertently introduce undesirable noise from the alternative language. To address this, we propose a novel kNN-CTC-based code-switching ASR (CS-ASR) framework that employs dual monolingual datastores and a gated datastore selection mechanism to reduce noise interference. Our method selects the appropriate datastore for decoding each frame, ensuring the injection of language-specific information into the ASR process. We apply this framework to cutting-edge CTC-based models, developing an advanced CS-ASR system. Extensive experiments demonstrate the remarkable effectiveness of our gated datastore mechanism in enhancing the performance of zero-shot Chinese-English CS-ASR.
Say Goodbye to RNN-T Loss: A Novel CIF-based Transducer Architecture for Automatic Speech Recognition
Jul 27, 2023



RNN-T models are widely used in ASR, which rely on the RNN-T loss to achieve length alignment between input audio and target sequence. However, the implementation complexity and the alignment-based optimization target of RNN-T loss lead to computational redundancy and a reduced role for predictor network, respectively. In this paper, we propose a novel model named CIF-Transducer (CIF-T) which incorporates the Continuous Integrate-and-Fire (CIF) mechanism with the RNN-T model to achieve efficient alignment. In this way, the RNN-T loss is abandoned, thus bringing a computational reduction and allowing the predictor network a more significant role. We also introduce Funnel-CIF, Context Blocks, Unified Gating and Bilinear Pooling joint network, and auxiliary training strategy to further improve performance. Experiments on the 178-hour AISHELL-1 and 10000-hour WenetSpeech datasets show that CIF-T achieves state-of-the-art results with lower computational overhead compared to RNN-T models.
Rethinking Speech Recognition with A Multimodal Perspective via Acoustic and Semantic Cooperative Decoding
May 23, 2023



Attention-based encoder-decoder (AED) models have shown impressive performance in ASR. However, most existing AED methods neglect to simultaneously leverage both acoustic and semantic features in decoder, which is crucial for generating more accurate and informative semantic states. In this paper, we propose an Acoustic and Semantic Cooperative Decoder (ASCD) for ASR. In particular, unlike vanilla decoders that process acoustic and semantic features in two separate stages, ASCD integrates them cooperatively. To prevent information leakage during training, we design a Causal Multimodal Mask. Moreover, a variant Semi-ASCD is proposed to balance accuracy and computational cost. Our proposal is evaluated on the publicly available AISHELL-1 and aidatatang_200zh datasets using Transformer, Conformer, and Branchformer as encoders, respectively. The experimental results show that ASCD significantly improves the performance by leveraging both the acoustic and semantic information cooperatively.
Non-autoregressive Transformer with Unified Bidirectional Decoder for Automatic Speech Recognition
Sep 14, 2021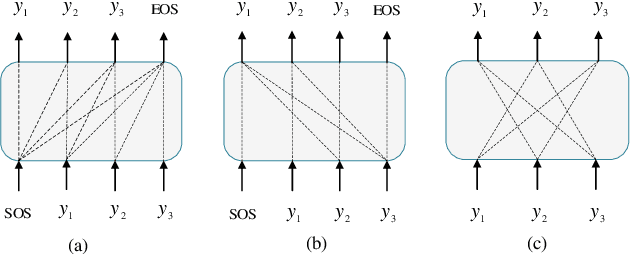
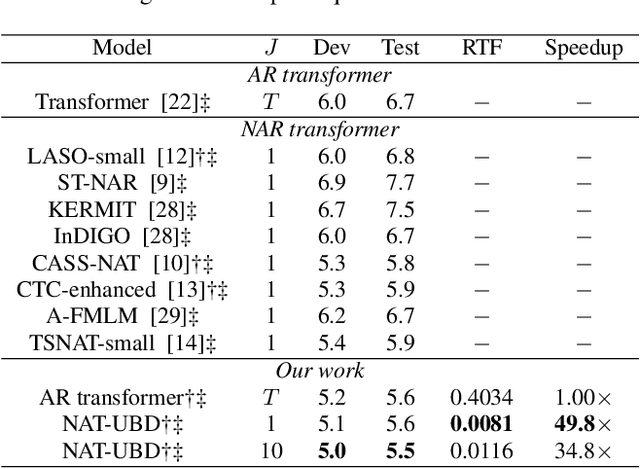
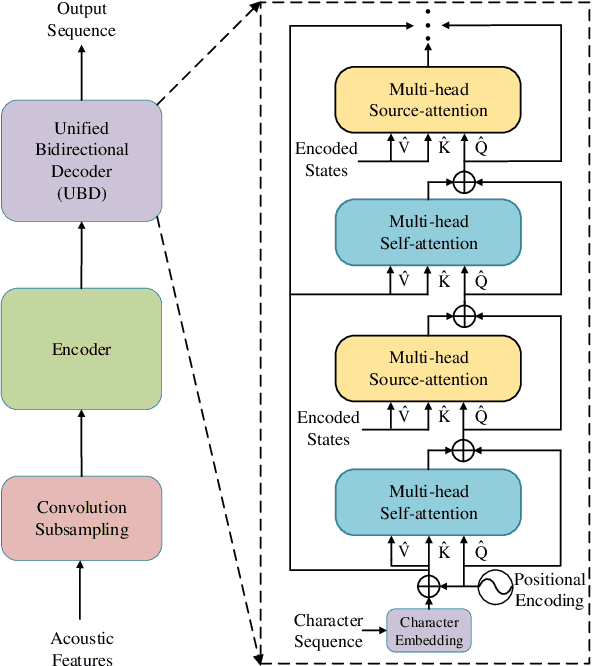

Non-autoregressive (NAR) transformer models have been studied intensively in automatic speech recognition (ASR), and a substantial part of NAR transformer models is to use the casual mask to limit token dependencies. However, the casual mask is designed for the left-to-right decoding process of the non-parallel autoregressive (AR) transformer, which is inappropriate for the parallel NAR transformer since it ignores the right-to-left contexts. Some models are proposed to utilize right-to-left contexts with an extra decoder, but these methods increase the model complexity. To tackle the above problems, we propose a new non-autoregressive transformer with a unified bidirectional decoder (NAT-UBD), which can simultaneously utilize left-to-right and right-to-left contexts. However, direct use of bidirectional contexts will cause information leakage, which means the decoder output can be affected by the character information from the input of the same position. To avoid information leakage, we propose a novel attention mask and modify vanilla queries, keys, and values matrices for NAT-UBD. Experimental results verify that NAT-UBD can achieve character error rates (CERs) of 5.0%/5.5% on the Aishell1 dev/test sets, outperforming all previous NAR transformer models. Moreover, NAT-UBD can run 49.8x faster than the AR transformer baseline when decoding in a single step.