 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSay Goodbye to RNN-T Loss: A Novel CIF-based Transducer Architecture for Automatic Speech Recognition
Jul 27, 2023



RNN-T models are widely used in ASR, which rely on the RNN-T loss to achieve length alignment between input audio and target sequence. However, the implementation complexity and the alignment-based optimization target of RNN-T loss lead to computational redundancy and a reduced role for predictor network, respectively. In this paper, we propose a novel model named CIF-Transducer (CIF-T) which incorporates the Continuous Integrate-and-Fire (CIF) mechanism with the RNN-T model to achieve efficient alignment. In this way, the RNN-T loss is abandoned, thus bringing a computational reduction and allowing the predictor network a more significant role. We also introduce Funnel-CIF, Context Blocks, Unified Gating and Bilinear Pooling joint network, and auxiliary training strategy to further improve performance. Experiments on the 178-hour AISHELL-1 and 10000-hour WenetSpeech datasets show that CIF-T achieves state-of-the-art results with lower computational overhead compared to RNN-T models.
Dynamic Latency for CTC-Based Streaming Automatic Speech Recognition With Emformer
Mar 29, 2022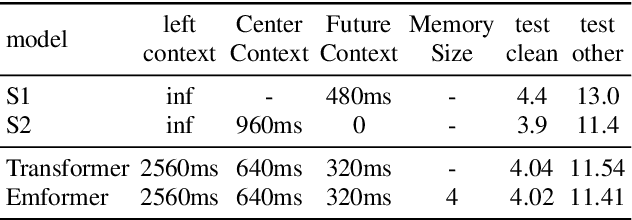
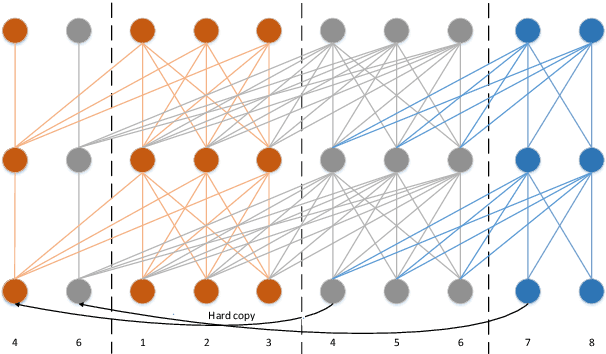

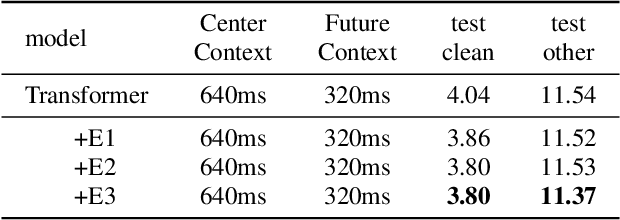
An inferior performance of the streaming automatic speech recognition models versus non-streaming model is frequently seen due to the absence of future context. In order to improve the performance of the streaming model and reduce the computational complexity, a frame-level model using efficient augment memory transformer block and dynamic latency training method is employed for streaming automatic speech recognition in this paper. The long-range history context is stored into the augment memory bank as a complement to the limited history context used in the encoder. Key and value are cached by a cache mechanism and reused for next chunk to reduce computation. Afterwards, a dynamic latency training method is proposed to obtain better performance and support low and high latency inference simultaneously. Our experiments are conducted on benchmark 960h LibriSpeech data set. With an average latency of 640ms, our model achieves a relative WER reduction of 6.0% on test-clean and 3.0% on test-other versus the truncate chunk-wise Transformer.
Locality Matters: A Locality-Biased Linear Attention for Automatic Speech Recognition
Mar 29, 2022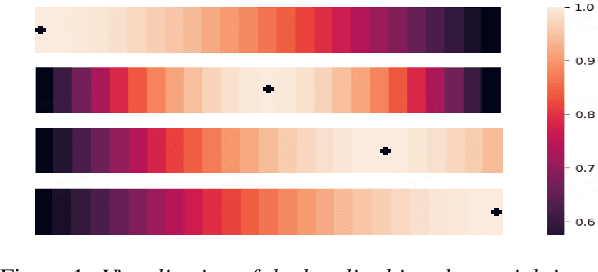
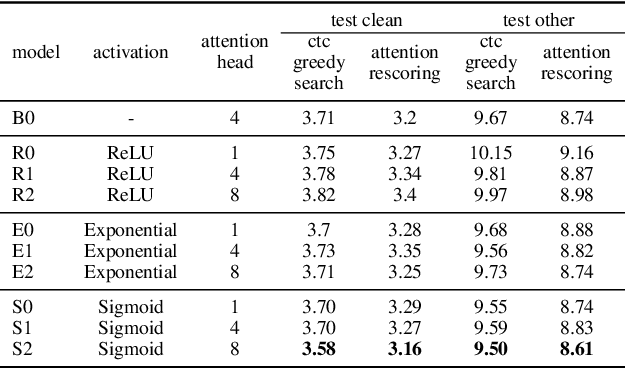
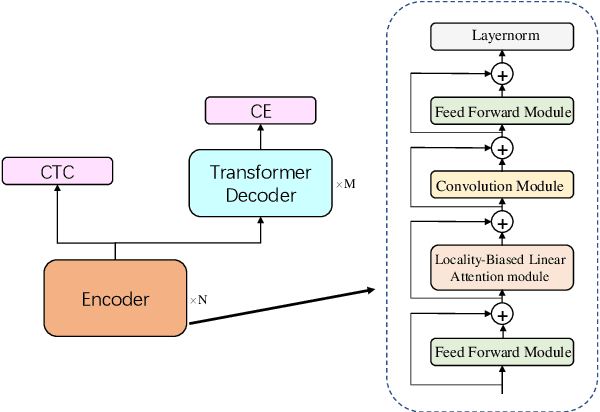
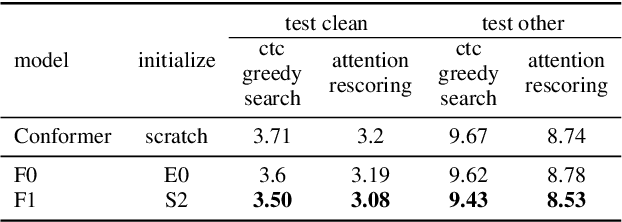
Conformer has shown a great success in automatic speech recognition (ASR) on many public benchmarks. One of its crucial drawbacks is the quadratic time-space complexity with respect to the input sequence length, which prohibits the model to scale-up as well as process longer input audio sequences. To solve this issue, numerous linear attention methods have been proposed. However, these methods often have limited performance on ASR as they treat tokens equally in modeling, neglecting the fact that the neighbouring tokens are often more connected than the distanced tokens. In this paper, we take this fact into account and propose a new locality-biased linear attention for Conformer. It not only achieves higher accuracy than the vanilla Conformer, but also enjoys linear space-time computational complexity. To be specific, we replace the softmax attention with a locality-biased linear attention (LBLA) mechanism in Conformer blocks. The LBLA contains a kernel function to ensure the linear complexities and a cosine reweighing matrix to impose more weights on neighbouring tokens. Extensive experiments on the LibriSpeech corpus show that by introducing this locality bias to the Conformer, our method achieves a lower word error rate with more than 22% inference speed.