 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF3-Tokenizer: Taming Audio Autoencoder Latents for Understanding and Generation
Jun 04, 2026Continuous audio autoencoders reconstruct waveforms well but often produce latents with weak structure for understanding, while self-supervised audio encoders capture semantics but are not directly decodable. This mismatch complicates a single audio tokenizer that must support both understanding and generation. We adapt continuous autoencoder latents to this setting with two components: a noise-regularized autoencoder bottleneck and a latent-side representation encoder. The bottleneck uses channel normalization and stochastic perturbation instead of KL-based variational training, yielding scale-controlled continuous latents for reconstruction and autoregressive generation. The representation encoder is trained on frozen autoencoder latents with RQ-MTP and frozen-LLM supervision. The resulting tokenizer provides high-dimensional representations for understanding while preserving normalized continuous latents as generation targets
Borderless Long Speech Synthesis
Mar 20, 2026Most existing text-to-speech (TTS) systems either synthesize speech sentence by sentence and stitch the results together, or drive synthesis from plain-text dialogues alone. Both approaches leave models with little understanding of global context or paralinguistic cues, making it hard to capture real-world phenomena such as multi-speaker interactions (interruptions, overlapping speech), evolving emotional arcs, and varied acoustic environments. We introduce the Borderless Long Speech Synthesis framework for agent-centric, borderless long audio synthesis. Rather than targeting a single narrow task, the system is designed as a unified capability set spanning VoiceDesigner, multi-speaker synthesis, Instruct TTS, and long-form text synthesis. On the data side, we propose a "Labeling over filtering/cleaning" strategy and design a top-down, multi-level annotation schema we call Global-Sentence-Token. On the model side, we adopt a backbone with a continuous tokenizer and add Chain-of-Thought (CoT) reasoning together with Dimension Dropout, both of which markedly improve instruction following under complex conditions. We further show that the system is Native Agentic by design: the hierarchical annotation doubles as a Structured Semantic Interface between the LLM Agent and the synthesis engine, creating a layered control protocol stack that spans from scene semantics down to phonetic detail. Text thereby becomes an information-complete, wide-band control channel, enabling a front-end LLM to convert inputs of any modality into structured generation commands, extending the paradigm from Text2Speech to borderless long speech synthesis.
Back to Ear: Perceptually Driven High Fidelity Music Reconstruction
Sep 18, 2025Variational Autoencoders (VAEs) are essential for large-scale audio tasks like diffusion-based generation. However, existing open-source models often neglect auditory perceptual aspects during training, leading to weaknesses in phase accuracy and stereophonic spatial representation. To address these challenges, we propose {\epsilon}ar-VAE, an open-source music signal reconstruction model that rethinks and optimizes the VAE training paradigm. Our contributions are threefold: (i) A K-weighting perceptual filter applied prior to loss calculation to align the objective with auditory perception. (ii) Two novel phase losses: a Correlation Loss for stereo coherence, and a Phase Loss using its derivatives--Instantaneous Frequency and Group Delay--for precision. (iii) A new spectral supervision paradigm where magnitude is supervised by all four Mid/Side/Left/Right components, while phase is supervised only by the LR components. Experiments show {\epsilon}ar-VAE at 44.1kHz substantially outperforms leading open-source models across diverse metrics, showing particular strength in reconstructing high-frequency harmonics and the spatial characteristics.
TouchASP: Elastic Automatic Speech Perception that Everyone Can Touch
Dec 20, 2024



Large Automatic Speech Recognition (ASR) models demand a vast number of parameters, copious amounts of data, and significant computational resources during the training process. However, such models can merely be deployed on high-compute cloud platforms and are only capable of performing speech recognition tasks. This leads to high costs and restricted capabilities. In this report, we initially propose the elastic mixture of the expert (eMoE) model. This model can be trained just once and then be elastically scaled in accordance with deployment requirements. Secondly, we devise an unsupervised data creation and validation procedure and gather millions of hours of audio data from diverse domains for training. Using these two techniques, our system achieves elastic deployment capabilities while reducing the Character Error Rate (CER) on the SpeechIO testsets from 4.98\% to 2.45\%. Thirdly, our model is not only competent in Mandarin speech recognition but also proficient in multilingual, multi-dialect, emotion, gender, and sound event perception. We refer to this as Automatic Speech Perception (ASP), and the perception results are presented in the experimental section.
TouchTTS: An Embarrassingly Simple TTS Framework that Everyone Can Touch
Dec 12, 2024It is well known that LLM-based systems are data-hungry. Recent LLM-based TTS works typically employ complex data processing pipelines to obtain high-quality training data. These sophisticated pipelines require excellent models at each stage (e.g., speech denoising, speech enhancement, speaker diarization, and punctuation models), which themselves demand high-quality training data and are rarely open-sourced. Even with state-of-the-art models, issues persist, such as incomplete background noise removal and misalignment between punctuation and actual speech pauses. Moreover, the stringent filtering strategies often retain only 10-30\% of the original data, significantly impeding data scaling efforts. In this work, we leverage a noise-robust audio tokenizer (S3Tokenizer) to design a simplified yet effective TTS data processing pipeline that maintains data quality while substantially reducing data acquisition costs, achieving a data retention rate of over 50\%. Beyond data scaling challenges, LLM-based TTS systems also incur higher deployment costs compared to conventional approaches. Current systems typically use LLMs solely for text-to-token generation, while requiring separate models (e.g., flow matching models) for token-to-waveform generation, which cannot be directly executed by LLM inference engines, further complicating deployment. To address these challenges, we eliminate redundant modules in both LLM and flow components, replacing the flow model backbone with an LLM architecture. Building upon this simplified flow backbone, we propose a unified architecture for both streaming and non-streaming inference, significantly reducing deployment costs. Finally, we explore the feasibility of unifying TTS and ASR tasks using the same data for training, thanks to the simplified pipeline and the S3Tokenizer that reduces the quality requirements for TTS training data.
U2++ MoE: Scaling 4.7x parameters with minimal impact on RTF
Apr 25, 2024



Scale has opened new frontiers in natural language processing, but at a high cost. In response, by learning to only activate a subset of parameters in training and inference, Mixture-of-Experts (MoE) have been proposed as an energy efficient path to even larger and more capable language models and this shift towards a new generation of foundation models is gaining momentum, particularly within the field of Automatic Speech Recognition (ASR). Recent works that incorporating MoE into ASR models have complex designs such as routing frames via supplementary embedding network, improving multilingual ability for the experts, and utilizing dedicated auxiliary losses for either expert load balancing or specific language handling. We found that delicate designs are not necessary, while an embarrassingly simple substitution of MoE layers for all Feed-Forward Network (FFN) layers is competent for the ASR task. To be more specific, we benchmark our proposed model on a large scale inner-source dataset (160k hours), the results show that we can scale our baseline Conformer (Dense-225M) to its MoE counterparts (MoE-1B) and achieve Dense-1B level Word Error Rate (WER) while maintaining a Dense-225M level Real Time Factor (RTF). Furthermore, by applying Unified 2-pass framework with bidirectional attention decoders (U2++), we achieve the streaming and non-streaming decoding modes in a single MoE based model, which we call U2++ MoE. We hope that our study can facilitate the research on scaling speech foundation models without sacrificing deployment efficiency.
Say Goodbye to RNN-T Loss: A Novel CIF-based Transducer Architecture for Automatic Speech Recognition
Jul 27, 2023



RNN-T models are widely used in ASR, which rely on the RNN-T loss to achieve length alignment between input audio and target sequence. However, the implementation complexity and the alignment-based optimization target of RNN-T loss lead to computational redundancy and a reduced role for predictor network, respectively. In this paper, we propose a novel model named CIF-Transducer (CIF-T) which incorporates the Continuous Integrate-and-Fire (CIF) mechanism with the RNN-T model to achieve efficient alignment. In this way, the RNN-T loss is abandoned, thus bringing a computational reduction and allowing the predictor network a more significant role. We also introduce Funnel-CIF, Context Blocks, Unified Gating and Bilinear Pooling joint network, and auxiliary training strategy to further improve performance. Experiments on the 178-hour AISHELL-1 and 10000-hour WenetSpeech datasets show that CIF-T achieves state-of-the-art results with lower computational overhead compared to RNN-T models.
Dynamic Latency for CTC-Based Streaming Automatic Speech Recognition With Emformer
Mar 29, 2022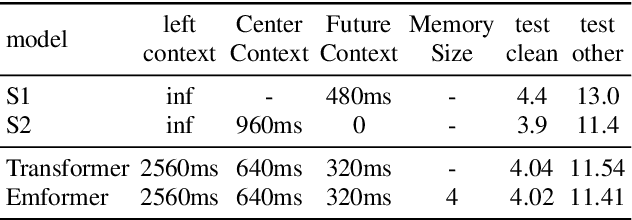
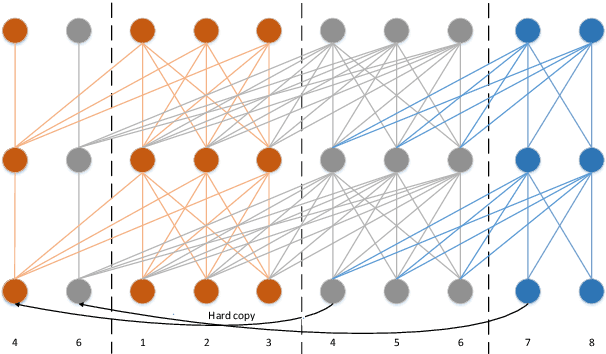

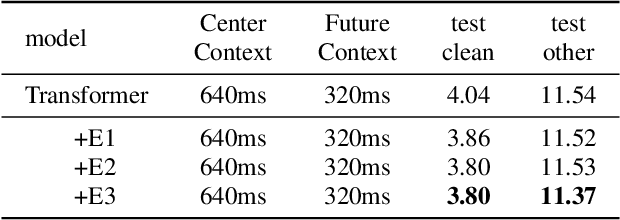
An inferior performance of the streaming automatic speech recognition models versus non-streaming model is frequently seen due to the absence of future context. In order to improve the performance of the streaming model and reduce the computational complexity, a frame-level model using efficient augment memory transformer block and dynamic latency training method is employed for streaming automatic speech recognition in this paper. The long-range history context is stored into the augment memory bank as a complement to the limited history context used in the encoder. Key and value are cached by a cache mechanism and reused for next chunk to reduce computation. Afterwards, a dynamic latency training method is proposed to obtain better performance and support low and high latency inference simultaneously. Our experiments are conducted on benchmark 960h LibriSpeech data set. With an average latency of 640ms, our model achieves a relative WER reduction of 6.0% on test-clean and 3.0% on test-other versus the truncate chunk-wise Transformer.
Locality Matters: A Locality-Biased Linear Attention for Automatic Speech Recognition
Mar 29, 2022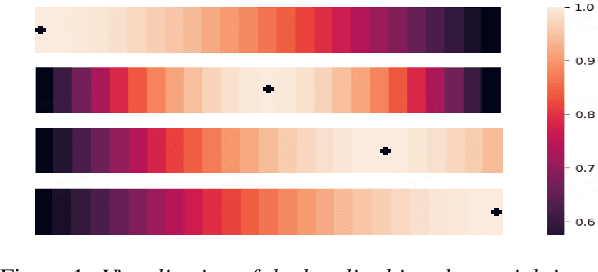
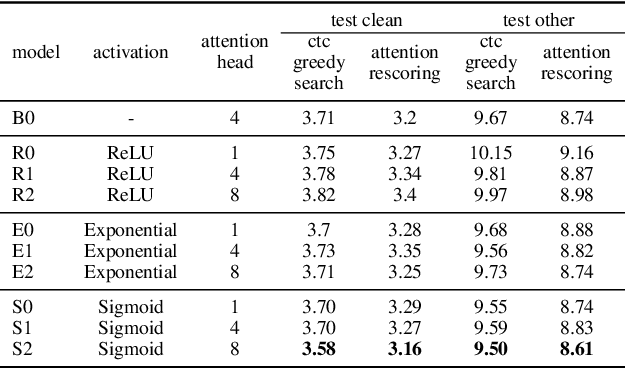
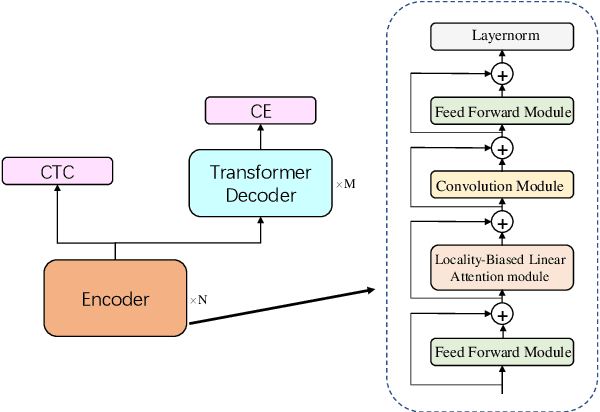
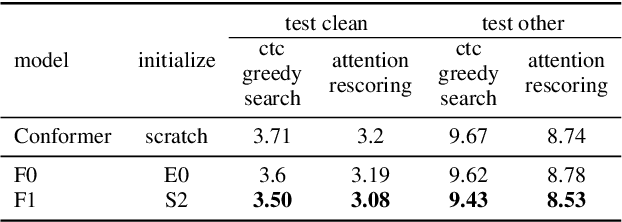
Conformer has shown a great success in automatic speech recognition (ASR) on many public benchmarks. One of its crucial drawbacks is the quadratic time-space complexity with respect to the input sequence length, which prohibits the model to scale-up as well as process longer input audio sequences. To solve this issue, numerous linear attention methods have been proposed. However, these methods often have limited performance on ASR as they treat tokens equally in modeling, neglecting the fact that the neighbouring tokens are often more connected than the distanced tokens. In this paper, we take this fact into account and propose a new locality-biased linear attention for Conformer. It not only achieves higher accuracy than the vanilla Conformer, but also enjoys linear space-time computational complexity. To be specific, we replace the softmax attention with a locality-biased linear attention (LBLA) mechanism in Conformer blocks. The LBLA contains a kernel function to ensure the linear complexities and a cosine reweighing matrix to impose more weights on neighbouring tokens. Extensive experiments on the LibriSpeech corpus show that by introducing this locality bias to the Conformer, our method achieves a lower word error rate with more than 22% inference speed.