 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Latency for CTC-Based Streaming Automatic Speech Recognition With Emformer
Paper and Code
Mar 29, 2022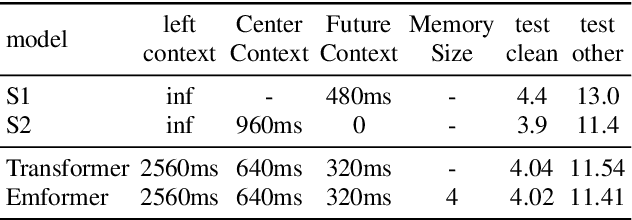
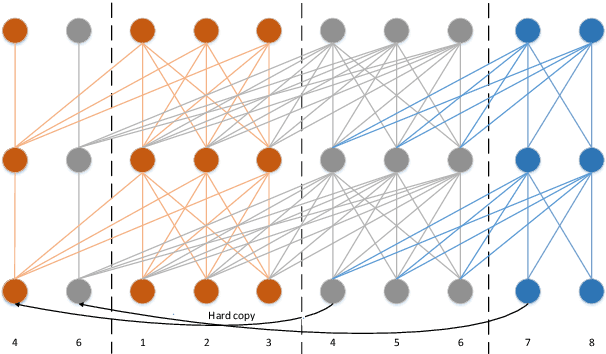

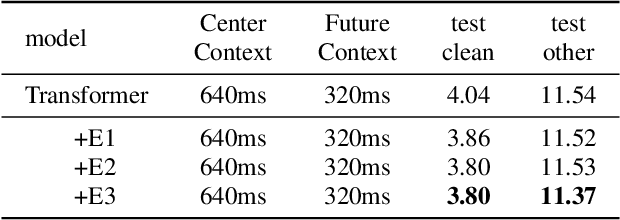
An inferior performance of the streaming automatic speech recognition models versus non-streaming model is frequently seen due to the absence of future context. In order to improve the performance of the streaming model and reduce the computational complexity, a frame-level model using efficient augment memory transformer block and dynamic latency training method is employed for streaming automatic speech recognition in this paper. The long-range history context is stored into the augment memory bank as a complement to the limited history context used in the encoder. Key and value are cached by a cache mechanism and reused for next chunk to reduce computation. Afterwards, a dynamic latency training method is proposed to obtain better performance and support low and high latency inference simultaneously. Our experiments are conducted on benchmark 960h LibriSpeech data set. With an average latency of 640ms, our model achieves a relative WER reduction of 6.0% on test-clean and 3.0% on test-other versus the truncate chunk-wise Transformer.