 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMELA-TTS: Joint transformer-diffusion model with representation alignment for speech synthesis
Sep 18, 2025This work introduces MELA-TTS, a novel joint transformer-diffusion framework for end-to-end text-to-speech synthesis. By autoregressively generating continuous mel-spectrogram frames from linguistic and speaker conditions, our architecture eliminates the need for speech tokenization and multi-stage processing pipelines. To address the inherent difficulties of modeling continuous features, we propose a representation alignment module that aligns output representations of the transformer decoder with semantic embeddings from a pretrained ASR encoder during training. This mechanism not only speeds up training convergence, but also enhances cross-modal coherence between the textual and acoustic domains. Comprehensive experiments demonstrate that MELA-TTS achieves state-of-the-art performance across multiple evaluation metrics while maintaining robust zero-shot voice cloning capabilities, in both offline and streaming synthesis modes. Our results establish a new benchmark for continuous feature generation approaches in TTS, offering a compelling alternative to discrete-token-based paradigms.
FunAudio-ASR Technical Report
Sep 15, 2025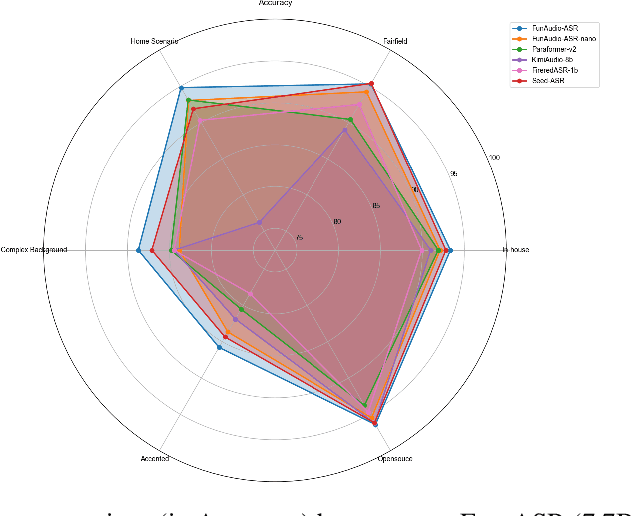
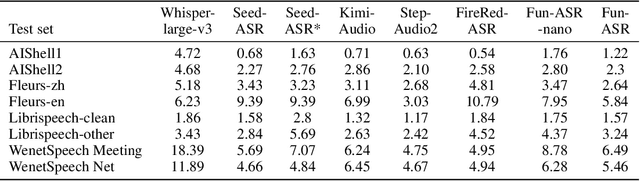
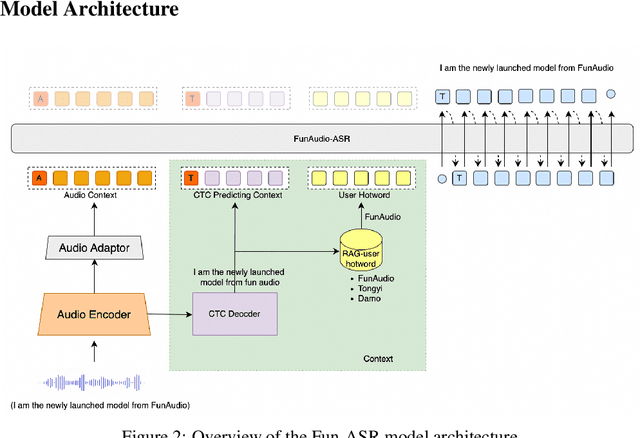
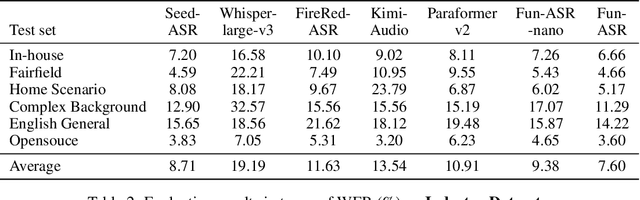
In recent years, automatic speech recognition (ASR) has witnessed transformative advancements driven by three complementary paradigms: data scaling, model size scaling, and deep integration with large language models (LLMs). However, LLMs are prone to hallucination, which can significantly degrade user experience in real-world ASR applications. In this paper, we present FunAudio-ASR, a large-scale, LLM-based ASR system that synergistically combines massive data, large model capacity, LLM integration, and reinforcement learning to achieve state-of-the-art performance across diverse and complex speech recognition scenarios. Moreover, FunAudio-ASR is specifically optimized for practical deployment, with enhancements in streaming capability, noise robustness, code-switching, hotword customization, and satisfying other real-world application requirements. Experimental results show that while most LLM-based ASR systems achieve strong performance on open-source benchmarks, they often underperform on real industry evaluation sets. Thanks to production-oriented optimizations, FunAudio-ASR achieves SOTA performance on real application datasets, demonstrating its effectiveness and robustness in practical settings.
Adapting Whisper for Streaming Speech Recognition via Two-Pass Decoding
Jun 13, 2025

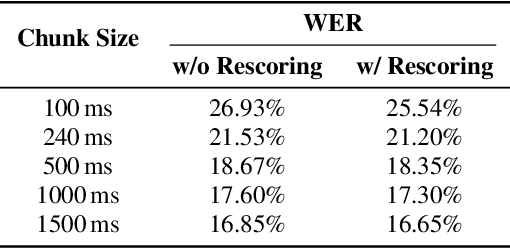
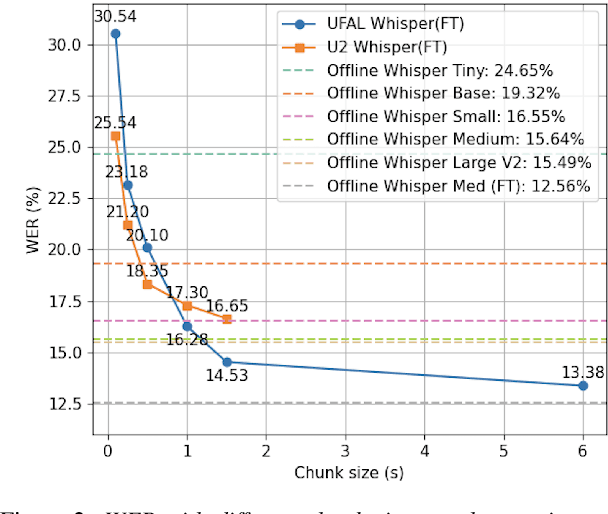
OpenAI Whisper is a family of robust Automatic Speech Recognition (ASR) models trained on 680,000 hours of audio. However, its encoder-decoder architecture, trained with a sequence-to-sequence objective, lacks native support for streaming ASR. In this paper, we fine-tune Whisper for streaming ASR using the WeNet toolkit by adopting a Unified Two-pass (U2) structure. We introduce an additional Connectionist Temporal Classification (CTC) decoder trained with causal attention masks to generate streaming partial transcripts, while the original Whisper decoder reranks these partial outputs. Our experiments on LibriSpeech and an earnings call dataset demonstrate that, with adequate fine-tuning data, Whisper can be adapted into a capable streaming ASR model. We also introduce a hybrid tokenizer approach, which uses a smaller token space for the CTC decoder while retaining Whisper's original token space for the attention decoder, resulting in improved data efficiency and generalization.
Hybrid Beamforming for RIS-Assisted Multiuser Fluid Antenna Systems
Apr 12, 2025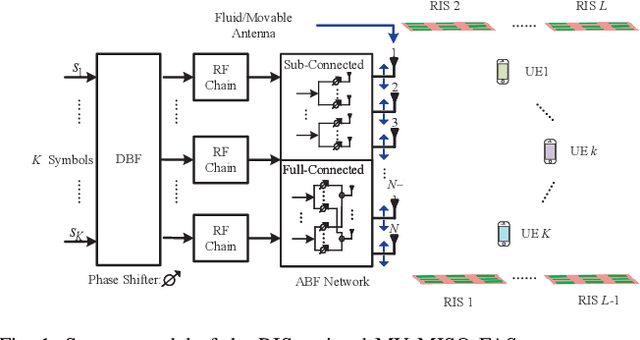
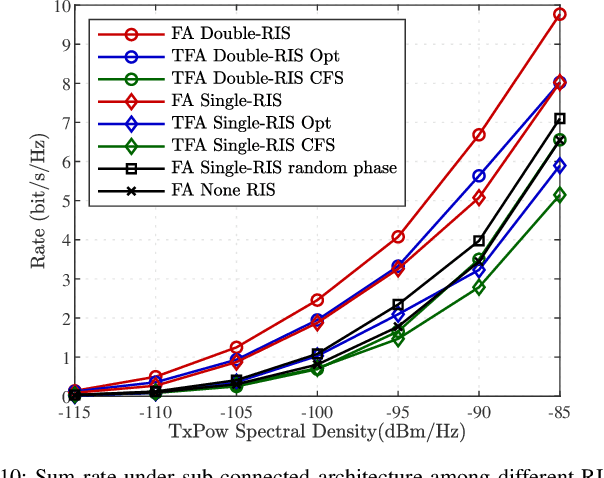
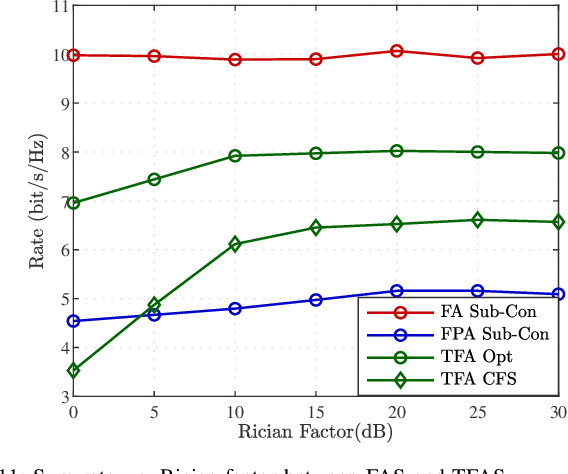
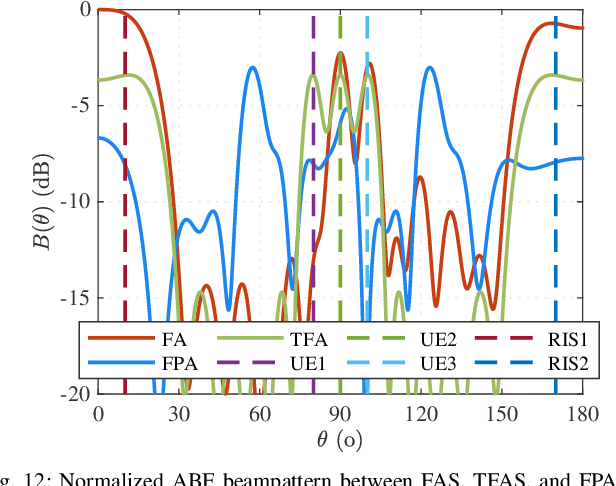
Recent advances in reconfigurable antennas have led to the new concept of the fluid antenna system (FAS) for shape and position flexibility, as another degree of freedom for wireless communication enhancement. This paper explores the integration of a transmit FAS array for hybrid beamforming (HBF) into a reconfigurable intelligent surface (RIS)-assisted communication architecture for multiuser communications in the downlink, corresponding to the downlink RIS-assisted multiuser multiple-input single-output (MISO) FAS model (Tx RIS-assisted-MISO-FAS). By considering Rician channel fading, we formulate a sum-rate maximization optimization problem to alternately optimize the HBF matrix, the RIS phase-shift matrix, and the FAS position. Due to the strong coupling of multiple optimization variables, the multi-fractional summation in the sum-rate expression, the modulus-1 limitation of analog phase shifters and RIS, and the antenna position variables appearing in the exponent, this problem is highly non-convex, which is addressed through the block coordinate descent (BCD) framework in conjunction with semidefinite relaxation (SDR) and majorization-minimization (MM) methods. To reduce the computational complexity, we then propose a low-complexity grating-lobe (GL)-based telescopic-FAS (TFA) with multiple delicately deployed RISs under the sub-connected HBF architecture and the line-of-sight (LoS)-dominant channel condition, to allow closed-form solutions for the HBF and TFA position. Our simulation results illustrate that the former optimization scheme significantly enhances the achievable rate of the proposed system, while the GL-based TFA scheme also provides a considerable gain over conventional fixed-position antenna (FPA) systems, requiring statistical channel state information (CSI) only and with low computational complexity.
TouchASP: Elastic Automatic Speech Perception that Everyone Can Touch
Dec 20, 2024



Large Automatic Speech Recognition (ASR) models demand a vast number of parameters, copious amounts of data, and significant computational resources during the training process. However, such models can merely be deployed on high-compute cloud platforms and are only capable of performing speech recognition tasks. This leads to high costs and restricted capabilities. In this report, we initially propose the elastic mixture of the expert (eMoE) model. This model can be trained just once and then be elastically scaled in accordance with deployment requirements. Secondly, we devise an unsupervised data creation and validation procedure and gather millions of hours of audio data from diverse domains for training. Using these two techniques, our system achieves elastic deployment capabilities while reducing the Character Error Rate (CER) on the SpeechIO testsets from 4.98\% to 2.45\%. Thirdly, our model is not only competent in Mandarin speech recognition but also proficient in multilingual, multi-dialect, emotion, gender, and sound event perception. We refer to this as Automatic Speech Perception (ASP), and the perception results are presented in the experimental section.
TouchTTS: An Embarrassingly Simple TTS Framework that Everyone Can Touch
Dec 12, 2024It is well known that LLM-based systems are data-hungry. Recent LLM-based TTS works typically employ complex data processing pipelines to obtain high-quality training data. These sophisticated pipelines require excellent models at each stage (e.g., speech denoising, speech enhancement, speaker diarization, and punctuation models), which themselves demand high-quality training data and are rarely open-sourced. Even with state-of-the-art models, issues persist, such as incomplete background noise removal and misalignment between punctuation and actual speech pauses. Moreover, the stringent filtering strategies often retain only 10-30\% of the original data, significantly impeding data scaling efforts. In this work, we leverage a noise-robust audio tokenizer (S3Tokenizer) to design a simplified yet effective TTS data processing pipeline that maintains data quality while substantially reducing data acquisition costs, achieving a data retention rate of over 50\%. Beyond data scaling challenges, LLM-based TTS systems also incur higher deployment costs compared to conventional approaches. Current systems typically use LLMs solely for text-to-token generation, while requiring separate models (e.g., flow matching models) for token-to-waveform generation, which cannot be directly executed by LLM inference engines, further complicating deployment. To address these challenges, we eliminate redundant modules in both LLM and flow components, replacing the flow model backbone with an LLM architecture. Building upon this simplified flow backbone, we propose a unified architecture for both streaming and non-streaming inference, significantly reducing deployment costs. Finally, we explore the feasibility of unifying TTS and ASR tasks using the same data for training, thanks to the simplified pipeline and the S3Tokenizer that reduces the quality requirements for TTS training data.
HydraFormer: One Encoder For All Subsampling Rates
Aug 08, 2024



In automatic speech recognition, subsampling is essential for tackling diverse scenarios. However, the inadequacy of a single subsampling rate to address various real-world situations often necessitates training and deploying multiple models, consequently increasing associated costs. To address this issue, we propose HydraFormer, comprising HydraSub, a Conformer-based encoder, and a BiTransformer-based decoder. HydraSub encompasses multiple branches, each representing a distinct subsampling rate, allowing for the flexible selection of any branch during inference based on the specific use case. HydraFormer can efficiently manage different subsampling rates, significantly reducing training and deployment expenses. Experiments on AISHELL-1 and LibriSpeech datasets reveal that HydraFormer effectively adapts to various subsampling rates and languages while maintaining high recognition performance. Additionally, HydraFormer showcases exceptional stability, sustaining consistent performance under various initialization conditions, and exhibits robust transferability by learning from pretrained single subsampling rate automatic speech recognition models\footnote{Model code and scripts: https://github.com/HydraFormer/hydraformer}.
Synchronization Scheme based on Pilot Sharing in Cell-Free Massive MIMO Systems
May 29, 2024



This paper analyzes the impact of pilot-sharing scheme on synchronization performance in a scenario where several slave access points (APs) with uncertain carrier frequency offsets (CFOs) and timing offsets (TOs) share a common pilot sequence. First, the Cramer-Rao bound (CRB) with pilot contamination is derived for pilot-pairing estimation. Furthermore, a maximum likelihood algorithm is presented to estimate the CFO and TO among the pairing APs. Then, to minimize the sum of CRBs, we devise a synchronization strategy based on a pilot-sharing scheme by jointly optimizing the cluster classification, synchronization overhead, and pilot-sharing scheme, while simultaneously considering the overhead and each AP's synchronization requirements. To solve this NP-hard problem, we simplify it into two sub-problems, namely cluster classification problem and the pilot sharing problem. To strike a balance between synchronization performance and overhead, we first classify the clusters by using the K-means algorithm, and propose a criteria to find a good set of master APs. Then, the pilot-sharing scheme is obtained by using the swap-matching operations. Simulation results validate the accuracy of our derivations and demonstrate the effectiveness of the proposed scheme over the benchmark schemes.
U2++ MoE: Scaling 4.7x parameters with minimal impact on RTF
Apr 25, 2024



Scale has opened new frontiers in natural language processing, but at a high cost. In response, by learning to only activate a subset of parameters in training and inference, Mixture-of-Experts (MoE) have been proposed as an energy efficient path to even larger and more capable language models and this shift towards a new generation of foundation models is gaining momentum, particularly within the field of Automatic Speech Recognition (ASR). Recent works that incorporating MoE into ASR models have complex designs such as routing frames via supplementary embedding network, improving multilingual ability for the experts, and utilizing dedicated auxiliary losses for either expert load balancing or specific language handling. We found that delicate designs are not necessary, while an embarrassingly simple substitution of MoE layers for all Feed-Forward Network (FFN) layers is competent for the ASR task. To be more specific, we benchmark our proposed model on a large scale inner-source dataset (160k hours), the results show that we can scale our baseline Conformer (Dense-225M) to its MoE counterparts (MoE-1B) and achieve Dense-1B level Word Error Rate (WER) while maintaining a Dense-225M level Real Time Factor (RTF). Furthermore, by applying Unified 2-pass framework with bidirectional attention decoders (U2++), we achieve the streaming and non-streaming decoding modes in a single MoE based model, which we call U2++ MoE. We hope that our study can facilitate the research on scaling speech foundation models without sacrificing deployment efficiency.
Radar Rainbow Beams For Wideband mmWave Communication: Beam Training And Tracking
Mar 14, 2024We propose a novel integrated sensing and communication (ISAC) system that leverages sensing to assist communication, ensuring fast initial access, seamless user tracking, and uninterrupted communication for millimeter wave (mmWave) wideband systems. True-time-delayers (TTDs) are utilized to generate frequency-dependent radar rainbow beams by controlling the beam squint effect. These beams cover users across the entire angular space simultaneously for fast beam training using just one orthogonal frequency-division multiplexing (OFDM) symbol. Three detection and estimation schemes are proposed based on radar rainbow beams for estimation of the users' angles, distances, and velocities, which are then exploited for communication beamformer design. The first proposed scheme utilizes a single-antenna radar receiver and one set of rainbow beams, but may cause a Doppler ambiguity. To tackle this limitation, two additional schemes are introduced, utilizing two sets of rainbow beams and a multi-antenna receiver, respectively. Furthermore, the proposed detection and estimation schemes are extended to realize user tracking by choosing different subsets of OFDM subcarriers. This approach eliminates the need to switch phase shifters and TTDs, which are typically necessary in existing tracking technologies, thereby reducing the demands on the control circurity. Simulation results reveal the effectiveness of the proposed rainbow beam-based training and tracking methods for mobile users. Notably, the scheme employing a multi-antenna radar receiver can accurately estimate the channel parameters and can support communication rates comparable to those achieved with perfect channel information.