 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Whisper for Streaming Speech Recognition via Two-Pass Decoding
Jun 13, 2025

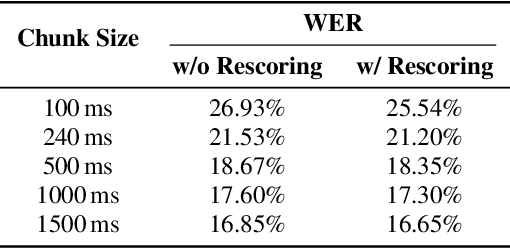
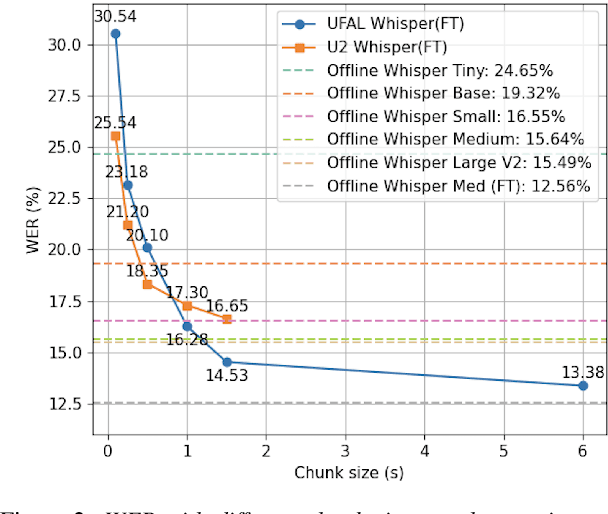
OpenAI Whisper is a family of robust Automatic Speech Recognition (ASR) models trained on 680,000 hours of audio. However, its encoder-decoder architecture, trained with a sequence-to-sequence objective, lacks native support for streaming ASR. In this paper, we fine-tune Whisper for streaming ASR using the WeNet toolkit by adopting a Unified Two-pass (U2) structure. We introduce an additional Connectionist Temporal Classification (CTC) decoder trained with causal attention masks to generate streaming partial transcripts, while the original Whisper decoder reranks these partial outputs. Our experiments on LibriSpeech and an earnings call dataset demonstrate that, with adequate fine-tuning data, Whisper can be adapted into a capable streaming ASR model. We also introduce a hybrid tokenizer approach, which uses a smaller token space for the CTC decoder while retaining Whisper's original token space for the attention decoder, resulting in improved data efficiency and generalization.
Learning When to Speak: Latency and Quality Trade-offs for Simultaneous Speech-to-Speech Translation with Offline Models
Jun 01, 2023

Recent work in speech-to-speech translation (S2ST) has focused primarily on offline settings, where the full input utterance is available before any output is given. This, however, is not reasonable in many real-world scenarios. In latency-sensitive applications, rather than waiting for the full utterance, translations should be spoken as soon as the information in the input is present. In this work, we introduce a system for simultaneous S2ST targeting real-world use cases. Our system supports translation from 57 languages to English with tunable parameters for dynamically adjusting the latency of the output -- including four policies for determining when to speak an output sequence. We show that these policies achieve offline-level accuracy with minimal increases in latency over a Greedy (wait-$k$) baseline. We open-source our evaluation code and interactive test script to aid future SimulS2ST research and application development.
AraBERT and Farasa Segmentation Based Approach For Sarcasm and Sentiment Detection in Arabic Tweets
Mar 02, 2021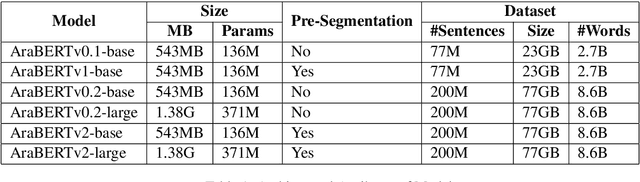
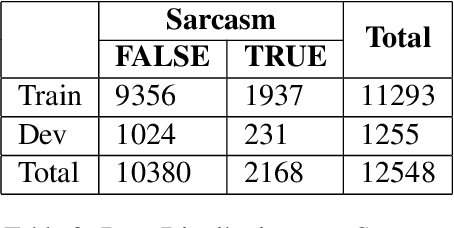
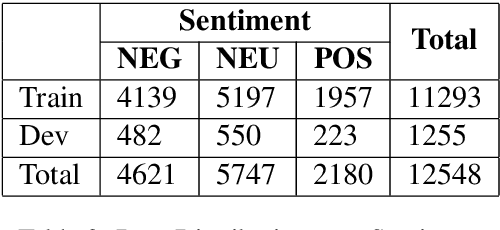
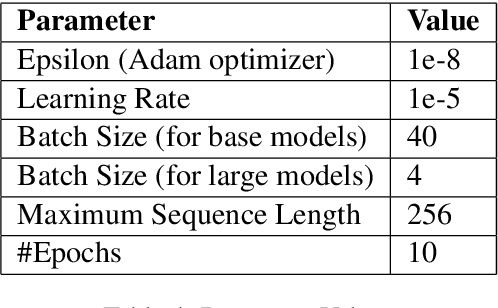
This paper presents our strategy to tackle the EACL WANLP-2021 Shared Task 2: Sarcasm and Sentiment Detection. One of the subtasks aims at developing a system that identifies whether a given Arabic tweet is sarcastic in nature or not, while the other aims to identify the sentiment of the Arabic tweet. We approach the task in two steps. The first step involves pre processing the provided ArSarcasm-v2 dataset by performing insertions, deletions and segmentation operations on various parts of the text. The second step involves experimenting with multiple variants of two transformer based models, AraELECTRA and AraBERT. Our final approach was ranked seventh and fourth in the Sarcasm and Sentiment Detection subtasks respectively.
Towards Emotion Recognition in Hindi-English Code-Mixed Data: A Transformer Based Approach
Feb 28, 2021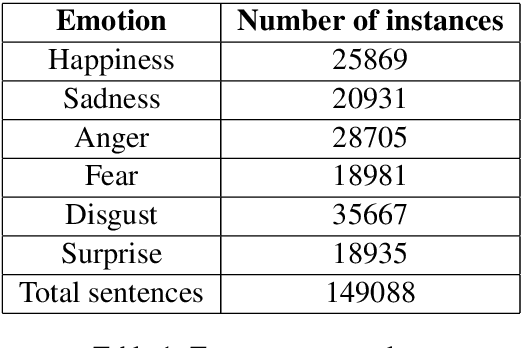
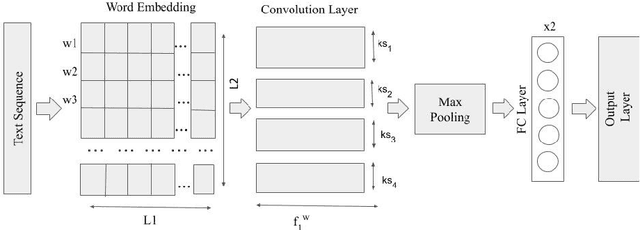
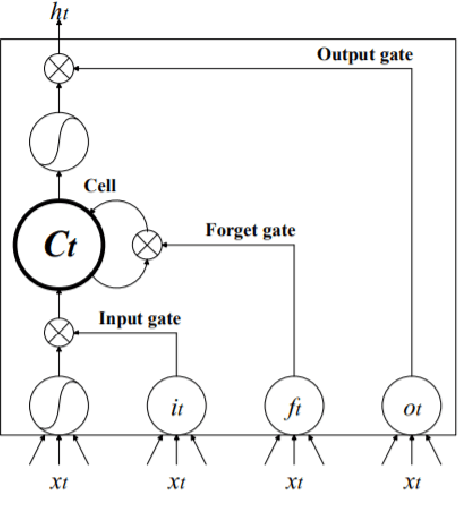
In the last few years, emotion detection in social-media text has become a popular problem due to its wide ranging application in better understanding the consumers, in psychology, in aiding human interaction with computers, designing smart systems etc. Because of the availability of huge amounts of data from social-media, which is regularly used for expressing sentiments and opinions, this problem has garnered great attention. In this paper, we present a Hinglish dataset labelled for emotion detection. We highlight a deep learning based approach for detecting emotions in Hindi-English code mixed tweets, using bilingual word embeddings derived from FastText and Word2Vec approaches, as well as transformer based models. We experiment with various deep learning models, including CNNs, LSTMs, Bi-directional LSTMs (with and without attention), along with transformers like BERT, RoBERTa, and ALBERT. The transformer based BERT model outperforms all other models giving the best performance with an accuracy of 71.43%.
Hopeful_Men@LT-EDI-EACL2021: Hope Speech Detection Using Indic Transliteration and Transformers
Feb 25, 2021
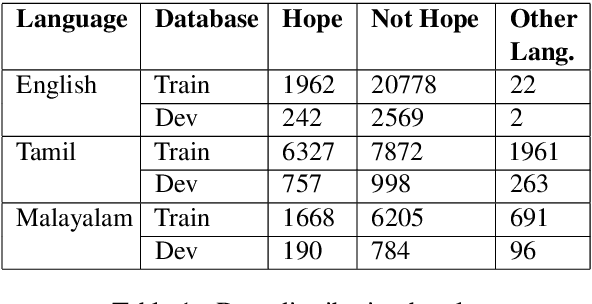
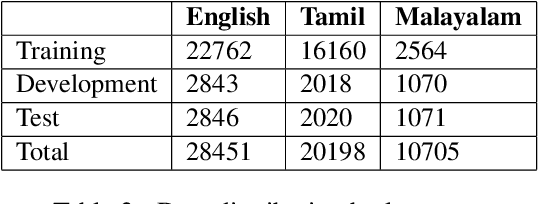
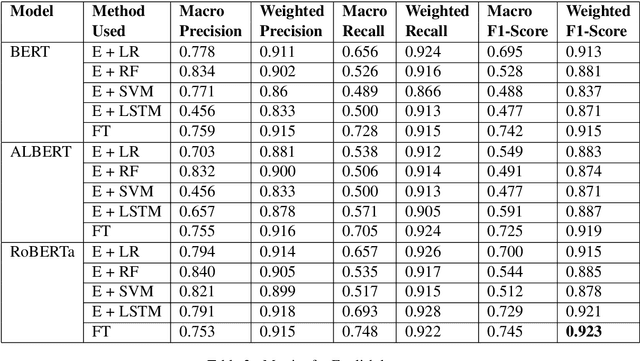
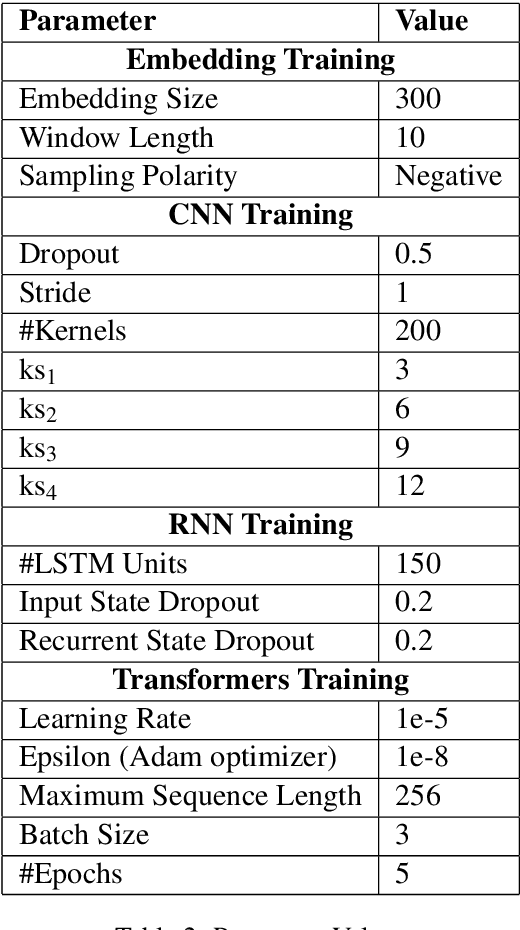
This paper aims to describe the approach we used to detect hope speech in the HopeEDI dataset. We experimented with two approaches. In the first approach, we used contextual embeddings to train classifiers using logistic regression, random forest, SVM, and LSTM based models.The second approach involved using a majority voting ensemble of 11 models which were obtained by fine-tuning pre-trained transformer models (BERT, ALBERT, RoBERTa, IndicBERT) after adding an output layer. We found that the second approach was superior for English, Tamil and Malayalam. Our solution got a weighted F1 score of 0.93, 0.75 and 0.49 for English,Malayalam and Tamil respectively. Our solution ranked first in English, eighth in Malayalam and eleventh in Tamil.
Dialect Identification in Nuanced Arabic Tweets Using Farasa Segmentation and AraBERT
Feb 22, 2021
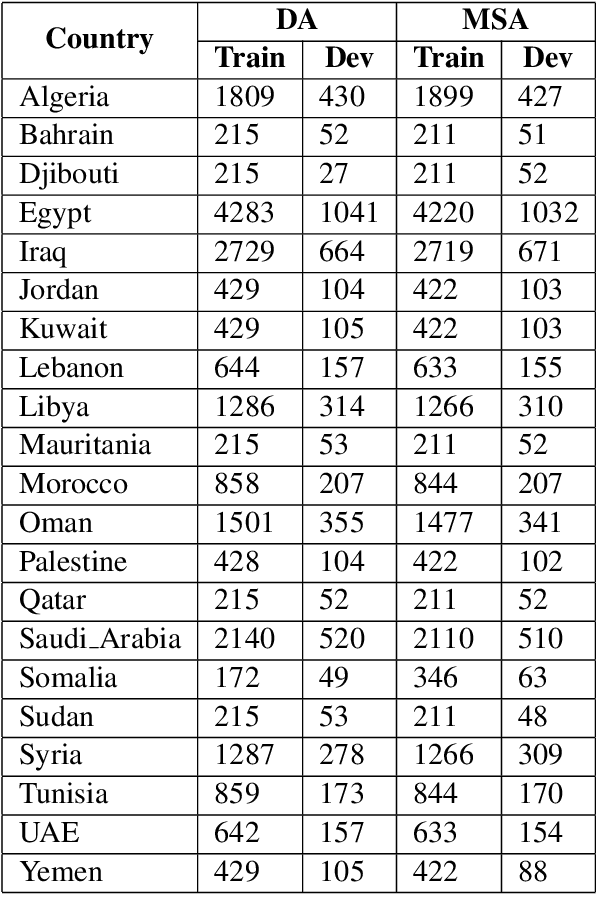
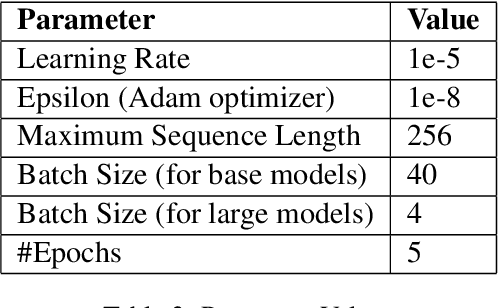
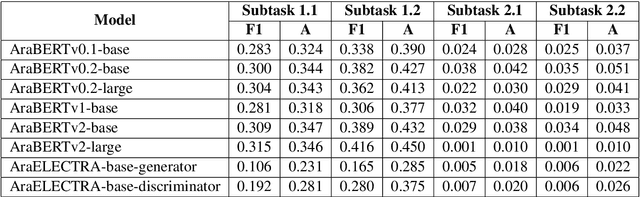
This paper presents our approach to address the EACL WANLP-2021 Shared Task 1: Nuanced Arabic Dialect Identification (NADI). The task is aimed at developing a system that identifies the geographical location(country/province) from where an Arabic tweet in the form of modern standard Arabic or dialect comes from. We solve the task in two parts. The first part involves pre-processing the provided dataset by cleaning, adding and segmenting various parts of the text. This is followed by carrying out experiments with different versions of two Transformer based models, AraBERT and AraELECTRA. Our final approach achieved macro F1-scores of 0.216, 0.235, 0.054, and 0.043 in the four subtasks, and we were ranked second in MSA identification subtasks and fourth in DA identification subtasks.
Phonemer at WNUT-2020 Task 2: Sequence Classification Using COVID Twitter BERT and Bagging Ensemble Technique based on Plurality Voting
Oct 15, 2020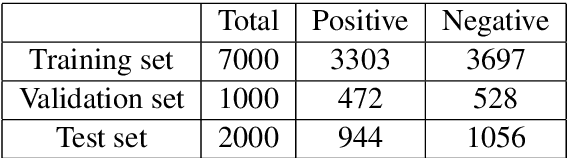
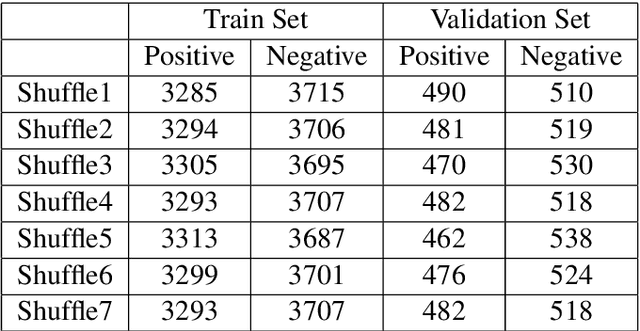
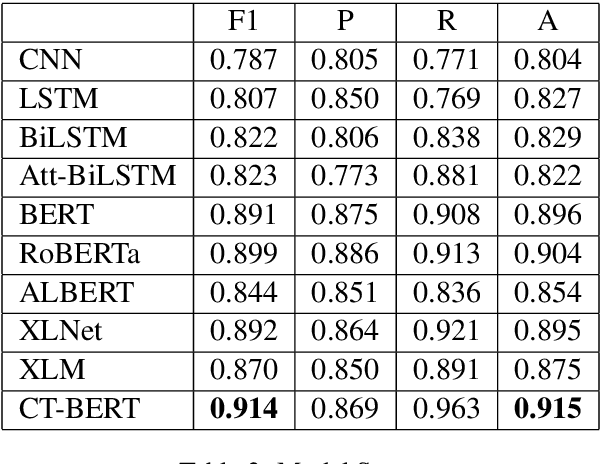
This paper presents the approach that we employed to tackle the EMNLP WNUT-2020 Shared Task 2 : Identification of informative COVID-19 English Tweets. The task is to develop a system that automatically identifies whether an English Tweet related to the novel coronavirus (COVID-19) is informative or not. We solve the task in three stages. The first stage involves pre-processing the dataset by filtering only relevant information. This is followed by experimenting with multiple deep learning models like CNNs, RNNs and Transformer based models. In the last stage, we propose an ensemble of the best model trained on different subsets of the provided dataset. Our final approach achieved an F1-score of 0.9037 and we were ranked sixth overall with F1-score as the evaluation criteria.
PublishInCovid19 at WNUT 2020 Shared Task-1: Entity Recognition in Wet Lab Protocols using Structured Learning Ensemble and Contextualised Embeddings
Oct 15, 2020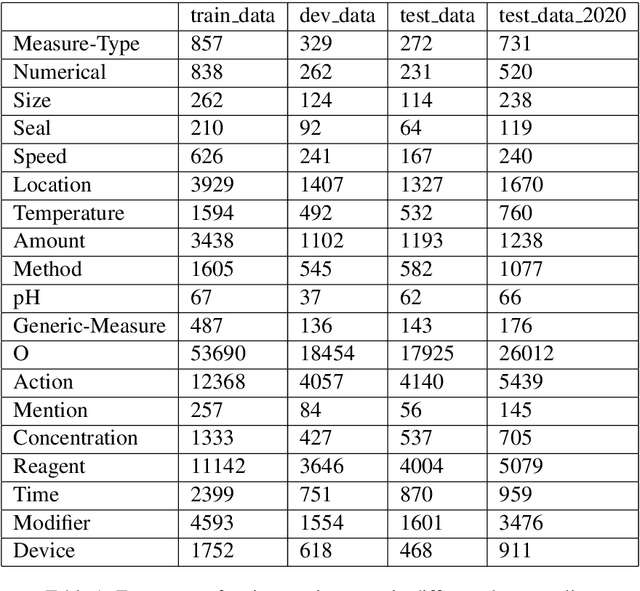
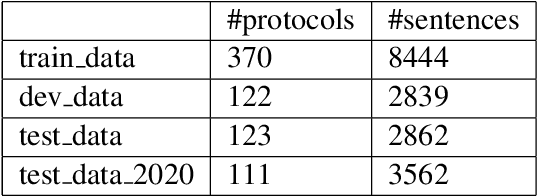
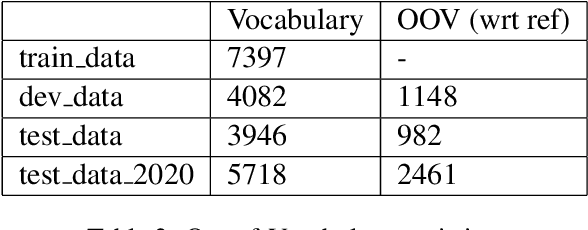
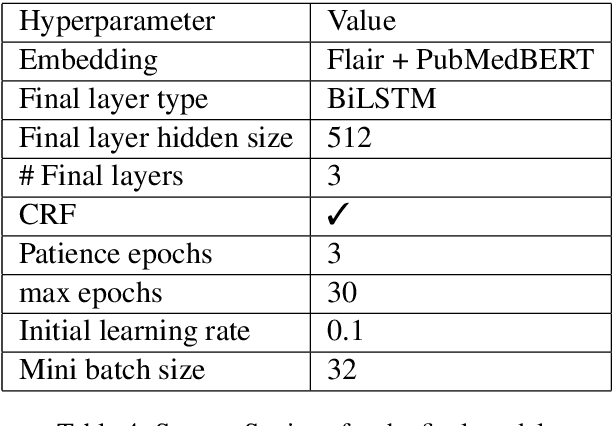
In this paper, we describe the approach that we employed to address the task of Entity Recognition over Wet Lab Protocols -- a shared task in EMNLP WNUT-2020 Workshop. Our approach is composed of two phases. In the first phase, we experiment with various contextualised word embeddings (like Flair, BERT-based) and a BiLSTM-CRF model to arrive at the best-performing architecture. In the second phase, we create an ensemble composed of eleven BiLSTM-CRF models. The individual models are trained on random train-validation splits of the complete dataset. Here, we also experiment with different output merging schemes, including Majority Voting and Structured Learning Ensembling (SLE). Our final submission achieved a micro F1-score of 0.8175 and 0.7757 for the partial and exact match of the entity spans, respectively. We were ranked first and second, in terms of partial and exact match, respectively.
"Did you really mean what you said?" : Sarcasm Detection in Hindi-English Code-Mixed Data using Bilingual Word Embeddings
Oct 15, 2020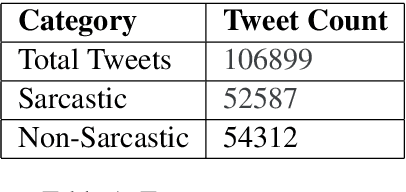
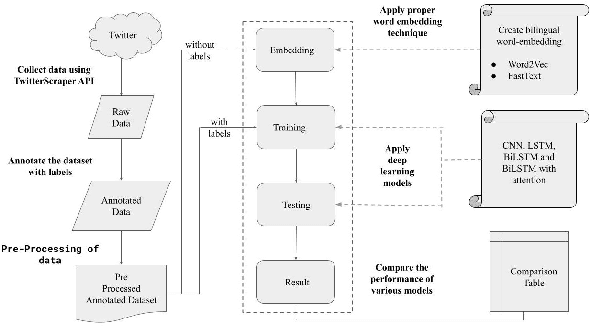
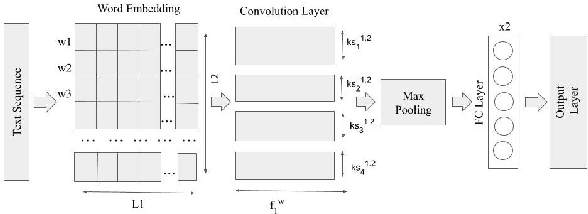
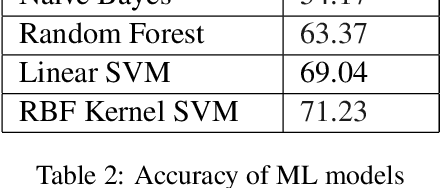
With the increased use of social media platforms by people across the world, many new interesting NLP problems have come into existence. One such being the detection of sarcasm in the social media texts. We present a corpus of tweets for training custom word embeddings and a Hinglish dataset labelled for sarcasm detection. We propose a deep learning based approach to address the issue of sarcasm detection in Hindi-English code mixed tweets using bilingual word embeddings derived from FastText and Word2Vec approaches. We experimented with various deep learning models, including CNNs, LSTMs, Bi-directional LSTMs (with and without attention). We were able to outperform all state-of-the-art performances with our deep learning models, with attention based Bi-directional LSTMs giving the best performance exhibiting an accuracy of 78.49%.