 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePublishInCovid19 at WNUT 2020 Shared Task-1: Entity Recognition in Wet Lab Protocols using Structured Learning Ensemble and Contextualised Embeddings
Paper and Code
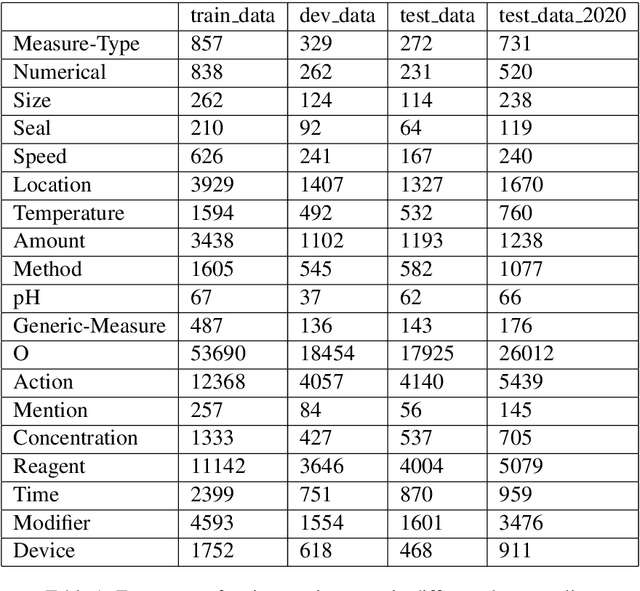
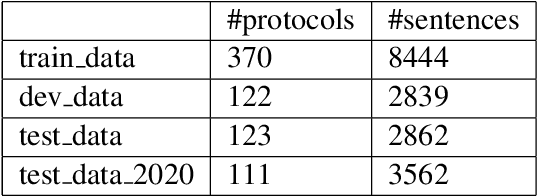
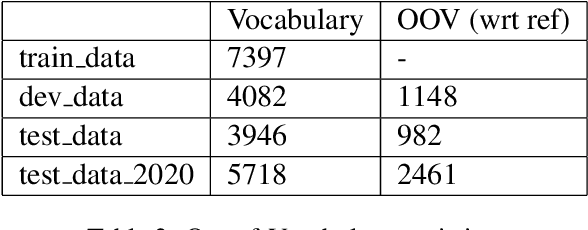
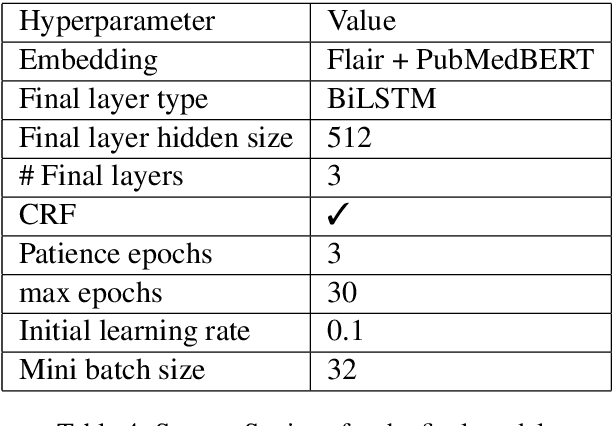
In this paper, we describe the approach that we employed to address the task of Entity Recognition over Wet Lab Protocols -- a shared task in EMNLP WNUT-2020 Workshop. Our approach is composed of two phases. In the first phase, we experiment with various contextualised word embeddings (like Flair, BERT-based) and a BiLSTM-CRF model to arrive at the best-performing architecture. In the second phase, we create an ensemble composed of eleven BiLSTM-CRF models. The individual models are trained on random train-validation splits of the complete dataset. Here, we also experiment with different output merging schemes, including Majority Voting and Structured Learning Ensembling (SLE). Our final submission achieved a micro F1-score of 0.8175 and 0.7757 for the partial and exact match of the entity spans, respectively. We were ranked first and second, in terms of partial and exact match, respectively.