 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring, Localizing, and Ablating Alignment Signatures in LLMs
May 28, 2026Aligned language models often exhibit a recognizable AI-like style, yet its connection to post-training and internal representations remains poorly understood. In this work, we study whether post-training introduces or amplifies AI-like stylistic regularities and whether these regularities have a localized internal signature. To this end, we compare human text, base-model generations, and aligned-model generations under matched human-source prefixes. Aligned generations show lower human-corpus affinity and higher AI-detection rates than base generations, suggesting that post-training shifts generated text away from human-corpus style and toward detector-visible AI-like text. We then introduce PASTA (Post-training Alignment Signature Targeted Ablation), a training-free method that estimates a post-training alignment signature from aligned-base residual contrasts and ablates the corresponding direction during decoding. Across 11 aligned models and 6 AI detectors, PASTA lowers the detection rate for most aligned models; this effect transfers well across detectors and is not reproduced by random directions. Qualitative analysis suggests that PASTA generations remain relevant and coherent while exhibiting greater stylistic variation. Together, these results show that AI-like stylistic effects of post-training can be measured, localized, and causally tested through activation ablation.
Do LLMs Encode Functional Importance of Reasoning Tokens?
Jan 06, 2026Large language models solve complex tasks by generating long reasoning chains, achieving higher accuracy at the cost of increased computational cost and reduced ability to isolate functionally relevant reasoning. Prior work on compact reasoning shortens such chains through probabilistic sampling, heuristics, or supervision from frontier models, but offers limited insight into whether models internally encode token-level functional importance for answer generation. We address this gap diagnostically and propose greedy pruning, a likelihood-preserving deletion procedure that iteratively removes reasoning tokens whose removal minimally degrades model likelihood under a specified objective, yielding length-controlled reasoning chains. We evaluate pruned reasoning in a distillation framework and show that students trained on pruned chains outperform a frontier-model-supervised compression baseline at matched reasoning lengths. Finally, our analysis reveals systematic pruning patterns and shows that attention scores can predict greedy pruning ranks, further suggesting that models encode a nontrivial functional importance structure over reasoning tokens.
PIPA: A Unified Evaluation Protocol for Diagnosing Interactive Planning Agents
May 02, 2025


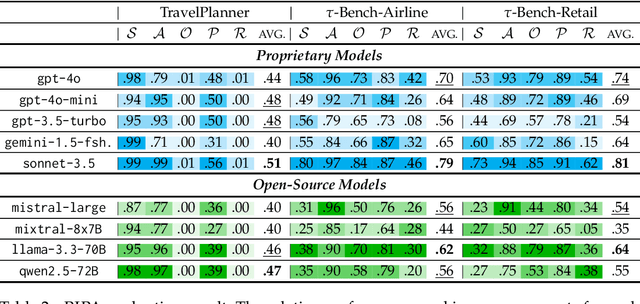
The growing capabilities of large language models (LLMs) in instruction-following and context-understanding lead to the era of agents with numerous applications. Among these, task planning agents have become especially prominent in realistic scenarios involving complex internal pipelines, such as context understanding, tool management, and response generation. However, existing benchmarks predominantly evaluate agent performance based on task completion as a proxy for overall effectiveness. We hypothesize that merely improving task completion is misaligned with maximizing user satisfaction, as users interact with the entire agentic process and not only the end result. To address this gap, we propose PIPA, a unified evaluation protocol that conceptualizes the behavioral process of interactive task planning agents within a partially observable Markov Decision Process (POMDP) paradigm. The proposed protocol offers a comprehensive assessment of agent performance through a set of atomic evaluation criteria, allowing researchers and practitioners to diagnose specific strengths and weaknesses within the agent's decision-making pipeline. Our analyses show that agents excel in different behavioral stages, with user satisfaction shaped by both outcomes and intermediate behaviors. We also highlight future directions, including systems that leverage multiple agents and the limitations of user simulators in task planning.
Forgotten Knowledge: Examining the Citational Amnesia in NLP
May 29, 2023



Citing papers is the primary method through which modern scientific writing discusses and builds on past work. Collectively, citing a diverse set of papers (in time and area of study) is an indicator of how widely the community is reading. Yet, there is little work looking at broad temporal patterns of citation. This work systematically and empirically examines: How far back in time do we tend to go to cite papers? How has that changed over time, and what factors correlate with this citational attention/amnesia? We chose NLP as our domain of interest and analyzed approximately 71.5K papers to show and quantify several key trends in citation. Notably, around 62% of cited papers are from the immediate five years prior to publication, whereas only about 17% are more than ten years old. Furthermore, we show that the median age and age diversity of cited papers were steadily increasing from 1990 to 2014, but since then, the trend has reversed, and current NLP papers have an all-time low temporal citation diversity. Finally, we show that unlike the 1990s, the highly cited papers in the last decade were also papers with the least citation diversity, likely contributing to the intense (and arguably harmful) recency focus. Code, data, and a demo are available on the project homepage.
Enhancing Textbooks with Visuals from the Web for Improved Learning
Apr 18, 2023



Textbooks are the primary vehicle for delivering quality education to students. It has been shown that explanatory or illustrative visuals play a key role in the retention, comprehension and the general transfer of knowledge. However, many textbooks, especially in the developing world, are low quality and lack interesting visuals to support student learning. In this paper, we investigate the effectiveness of vision-language models to automatically enhance textbooks with images from the web. Specifically, we collect a dataset of e-textbooks from one of the largest free online publishers in the world. We rigorously analyse the dataset, and use the resulting analysis to motivate a task that involves retrieving and appropriately assigning web images to textbooks, which we frame as a novel optimization problem. Through a crowd-sourced evaluation, we verify that (1) while the original textbook images are rated higher, automatically assigned ones are not far behind, and (2) the choice of the optimization problem matters. We release the dataset of textbooks with an associated image bank to spur further research in this area.
Geographic Citation Gaps in NLP Research
Oct 26, 2022



In a fair world, people have equitable opportunities to education, to conduct scientific research, to publish, and to get credit for their work, regardless of where they live. However, it is common knowledge among researchers that a vast number of papers accepted at top NLP venues come from a handful of western countries and (lately) China; whereas, very few papers from Africa and South America get published. Similar disparities are also believed to exist for paper citation counts. In the spirit of "what we do not measure, we cannot improve", this work asks a series of questions on the relationship between geographical location and publication success (acceptance in top NLP venues and citation impact). We first created a dataset of 70,000 papers from the ACL Anthology, extracted their meta-information, and generated their citation network. We then show that not only are there substantial geographical disparities in paper acceptance and citation but also that these disparities persist even when controlling for a number of variables such as venue of publication and sub-field of NLP. Further, despite some steps taken by the NLP community to improve geographical diversity, we show that the disparity in publication metrics across locations is still on an increasing trend since the early 2000s. We release our code and dataset here: https://github.com/iamjanvijay/acl-cite-net
Frustratingly Simple Entity Tracking with Effective Use of Multi-Task Learning Models
Oct 12, 2022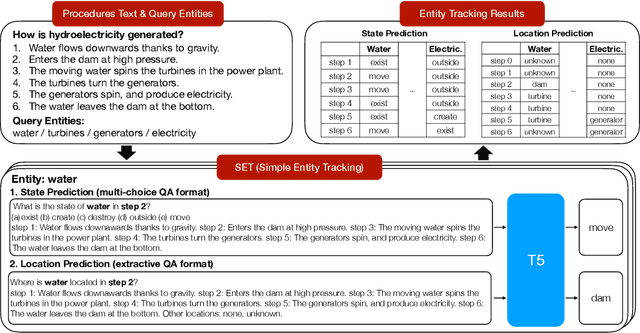
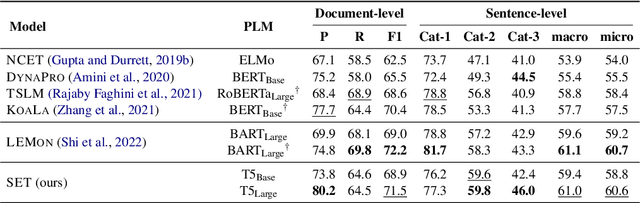
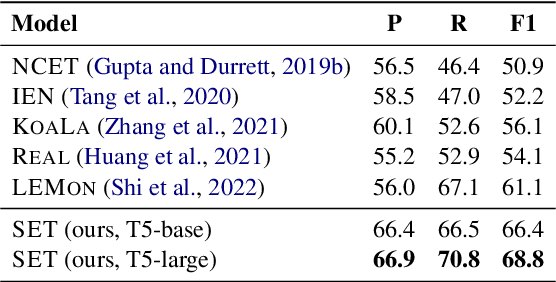
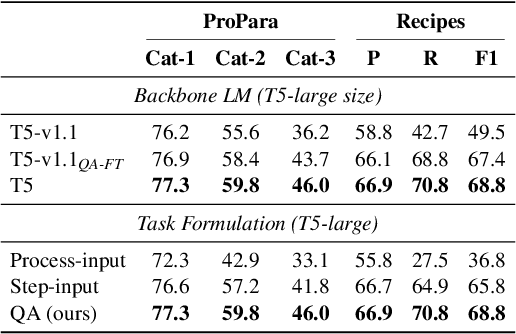
We present SET, a frustratingly Simple-yet-effective approach for Entity Tracking in procedural text. Compared with state-of-the-art entity tracking models that require domain-specific pre-training, SET simply fine-tunes off-the-shelf T5 with customized formats and gets comparable or even better performance on multiple datasets. Concretely, SET tackles the state and location prediction in entity tracking independently and formulates them as multi-choice and extractive QA problems, respectively. Through a series of careful analyses, we show that T5's supervised multi-task learning plays an important role in the success of SET. In addition, we reveal that SET has a strong capability of understanding implicit entity transformations, suggesting that multi-task transfer learning should be further explored in future entity tracking research.
De-STT: De-entaglement of unwanted Nuisances and Biases in Speech to Text System using Adversarial Forgetting
Dec 01, 2020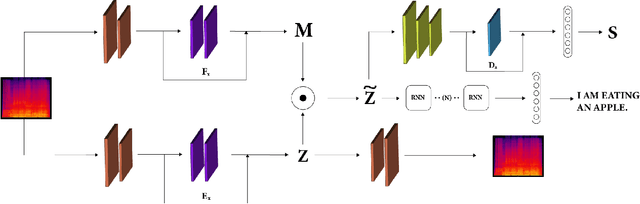

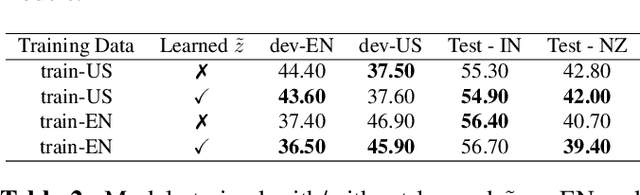
Training robust Speech to Text (STT) system require "tens of thousand" of hours of data. Variability present in the dataset, in the form of unwanted nuisances (noise) and biases (accent, gender or age) is the reason for the need of large datasets to learn general representations, which is unfeasible for low resource languages. A recently proposed deep learning approach to remove these unwanted features, called adversarial forgetting, was able to produce better results on computer vision tasks. Motivated by this, in this paper, we study the effect of de-entangling the accent information from the input speech signal on training STT systems. To this end, we use an information bottleneck architecture based on adversarial forgetting. This training scheme aims to enforce the model to learn general accent invariant speech representations. The trained STT model is tested on two unseen accents in the common voice V1. The results are in favour of STT model trained using the adversarial forgetting scheme.
PublishInCovid19 at WNUT 2020 Shared Task-1: Entity Recognition in Wet Lab Protocols using Structured Learning Ensemble and Contextualised Embeddings
Oct 15, 2020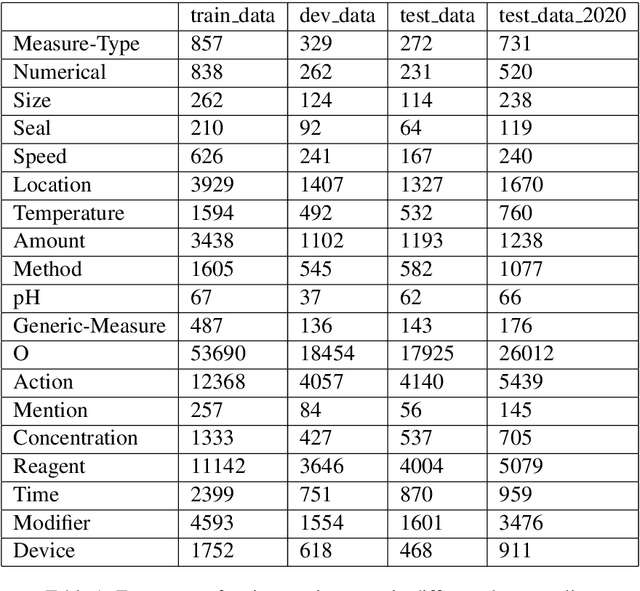
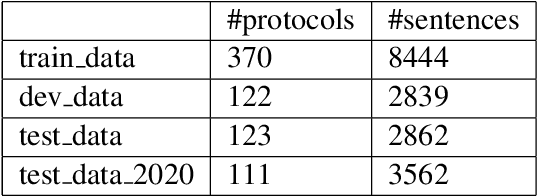
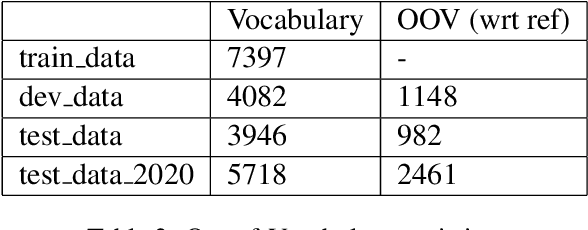
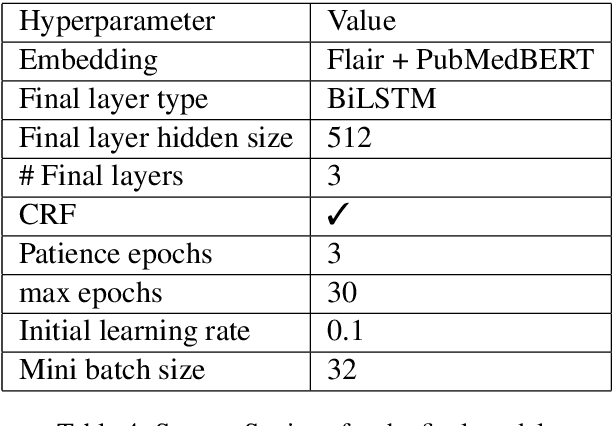
In this paper, we describe the approach that we employed to address the task of Entity Recognition over Wet Lab Protocols -- a shared task in EMNLP WNUT-2020 Workshop. Our approach is composed of two phases. In the first phase, we experiment with various contextualised word embeddings (like Flair, BERT-based) and a BiLSTM-CRF model to arrive at the best-performing architecture. In the second phase, we create an ensemble composed of eleven BiLSTM-CRF models. The individual models are trained on random train-validation splits of the complete dataset. Here, we also experiment with different output merging schemes, including Majority Voting and Structured Learning Ensembling (SLE). Our final submission achieved a micro F1-score of 0.8175 and 0.7757 for the partial and exact match of the entity spans, respectively. We were ranked first and second, in terms of partial and exact match, respectively.