 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJOOCI: a Framework for Learning Comprehensive Speech Representations
Oct 14, 2024Information in speech can be divided into two categories: what is being said (content) and how it is expressed (other). Current state-of-the-art (SOTA) techniques model speech at fixed segments, usually 10-25 ms, using a single embedding. Given the orthogonal nature of other and content information, attempting to optimize both within a single embedding results in suboptimal solutions. This approach divides the models capacity, limiting its ability to build complex hierarchical features effectively. In this work, we present an end-to-end speech representation learning framework designed to jointly optimize the other and content information (JOOCI) in speech. By using separate learnable parameters, JOOCI addresses this optimization challenge by modeling other and content information independently. Our results show that JOOCI consistently outperforms other SOTA models of similar size (100 million parameters) and pre-training data used (960 hours) by a significant margin when evaluated on a range of speech downstream tasks in the SUPERB benchmark, as shown in Table 1.
Speech Representation Learning Revisited: The Necessity of Separate Learnable Parameters and Robust Data Augmentation
Aug 20, 2024Speech modeling methods learn one embedding for a fixed segment of speech, typically in between 10-25 ms. The information present in speech can be divided into two categories: "what is being said" (content) and "how it is expressed" (other) and these two are orthogonal in nature causing the optimization algorithm to find a sub-optimal solution if forced to optimize together. This leads to sub-optimal performance in one or all downstream tasks as shown by previous studies. Current self-supervised learning (SSL) methods such as HuBERT are very good at modeling the content information present in speech. Data augmentation improves the performance on tasks which require effective modeling of other information but this leads to a divided capacity of the model. In this work, we conduct a preliminary study to understand the importance of modeling other information using separate learnable parameters. We propose a modified version of HuBERT, termed Other HuBERT (O-HuBERT), to test our hypothesis. Our findings are twofold: first, the O-HuBERT method is able to utilize all layers to build complex features to encode other information; second, a robust data augmentation strategy is essential for learning the information required by tasks that depend on other information and to achieve state-of-the-art (SOTA) performance on the SUPERB benchmark with a similarly sized model (100 million parameters) and pre-training data (960 hours).
MS-HuBERT: Mitigating Pre-training and Inference Mismatch in Masked Language Modelling methods for learning Speech Representations
Jun 09, 2024In recent years, self-supervised pre-training methods have gained significant traction in learning high-level information from raw speech. Among these methods, HuBERT has demonstrated SOTA performance in automatic speech recognition (ASR). However, HuBERT's performance lags behind data2vec due to disparities in pre-training strategies. In this paper, we propose (i) a Swap method to address pre-training and inference mismatch observed in HuBERT and (ii) incorporates Multicluster masked prediction loss for more effective utilization of the models capacity. The resulting method is, MS-HuBERT, an end-to-end self-supervised pre-training method for learning robust speech representations. It beats vanilla HuBERT on the ASR Librispeech benchmark on average by a 5% margin when evaluated on different finetuning splits. Additionally, we demonstrate that the learned embeddings obtained during pre-training encode essential information for improving performance of content based tasks such as ASR.
Partial Rank Similarity Minimization Method for Quality MOS Prediction of Unseen Speech Synthesis Systems in Zero-Shot and Semi-supervised setting
Oct 08, 2023



This paper introduces a novel objective function for quality mean opinion score (MOS) prediction of unseen speech synthesis systems. The proposed function measures the similarity of relative positions of predicted MOS values, in a mini-batch, rather than the actual MOS values. That is the partial rank similarity is measured (PRS) rather than the individual MOS values as with the L1 loss. Our experiments on out-of-domain speech synthesis systems demonstrate that the PRS outperforms L1 loss in zero-shot and semi-supervised settings, exhibiting stronger correlation with ground truth. These findings highlight the importance of considering rank order, as done by PRS, when training MOS prediction models. We also argue that mean squared error and linear correlation coefficient metrics may be unreliable for evaluating MOS prediction models. In conclusion, PRS-trained models provide a robust framework for evaluating speech quality and offer insights for developing high-quality speech synthesis systems. Code and models are available at github.com/nii-yamagishilab/partial_rank_similarity/
Analysing the Masked predictive coding training criterion for pre-training a Speech Representation Model
Mar 13, 2023Recent developments in pre-trained speech representation utilizing self-supervised learning (SSL) have yielded exceptional results on a variety of downstream tasks. One such technique, known as masked predictive coding (MPC), has been employed by some of the most high-performing models. In this study, we investigate the impact of MPC loss on the type of information learnt at various layers in the HuBERT model, using nine probing tasks. Our findings indicate that the amount of content information learned at various layers of the HuBERT model has a positive correlation to the MPC loss. Additionally, it is also observed that any speaker-related information learned at intermediate layers of the model, is an indirect consequence of the learning process, and therefore cannot be controlled using the MPC loss. These findings may serve as inspiration for further research in the speech community, specifically in the development of new pre-training tasks or the exploration of new pre-training criterion's that directly preserves both speaker and content information at various layers of a learnt model.
A Survey of Multilingual Models for Automatic Speech Recognition
Feb 25, 2022Although Automatic Speech Recognition (ASR) systems have achieved human-like performance for a few languages, the majority of the world's languages do not have usable systems due to the lack of large speech datasets to train these models. Cross-lingual transfer is an attractive solution to this problem, because low-resource languages can potentially benefit from higher-resource languages either through transfer learning, or being jointly trained in the same multilingual model. The problem of cross-lingual transfer has been well studied in ASR, however, recent advances in Self Supervised Learning are opening up avenues for unlabeled speech data to be used in multilingual ASR models, which can pave the way for improved performance on low-resource languages. In this paper, we survey the state of the art in multilingual ASR models that are built with cross-lingual transfer in mind. We present best practices for building multilingual models from research across diverse languages and techniques, discuss open questions and provide recommendations for future work.
Intent Classification Using Pre-Trained Embeddings For Low Resource Languages
Oct 18, 2021
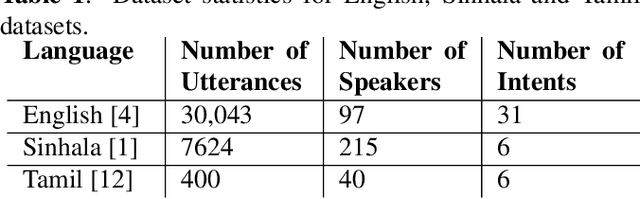

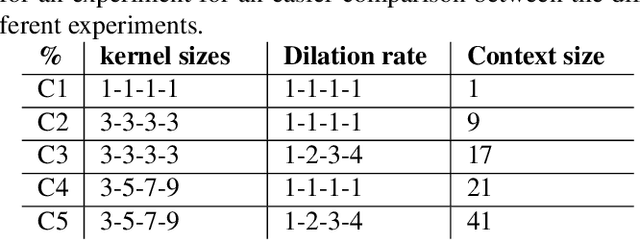
Building Spoken Language Understanding (SLU) systems that do not rely on language specific Automatic Speech Recognition (ASR) is an important yet less explored problem in language processing. In this paper, we present a comparative study aimed at employing a pre-trained acoustic model to perform SLU in low resource scenarios. Specifically, we use three different embeddings extracted using Allosaurus, a pre-trained universal phone decoder: (1) Phone (2) Panphone, and (3) Allo embeddings. These embeddings are then used in identifying the spoken intent. We perform experiments across three different languages: English, Sinhala, and Tamil each with different data sizes to simulate high, medium, and low resource scenarios. Our system improves on the state-of-the-art (SOTA) intent classification accuracy by approximately 2.11% for Sinhala and 7.00% for Tamil and achieves competitive results on English. Furthermore, we present a quantitative analysis of how the performance scales with the number of training examples used per intent.
Cisco at AAAI-CAD21 shared task: Predicting Emphasis in Presentation Slides using Contextualized Embeddings
Feb 09, 2021
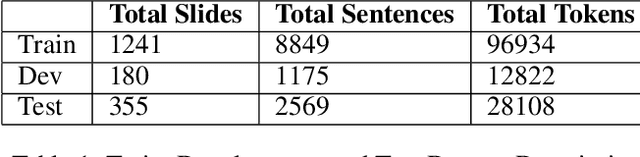
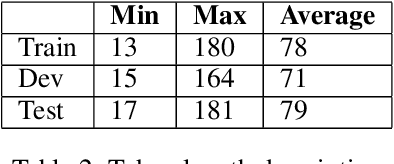
This paper describes our proposed system for the AAAI-CAD21 shared task: Predicting Emphasis in Presentation Slides. In this specific task, given the contents of a slide we are asked to predict the degree of emphasis to be laid on each word in the slide. We propose 2 approaches to this problem including a BiLSTM-ELMo approach and a transformers based approach based on RoBERTa and XLNet architectures. We achieve a score of 0.518 on the evaluation leaderboard which ranks us 3rd and 0.543 on the post-evaluation leaderboard which ranks us 1st at the time of writing the paper.
De-STT: De-entaglement of unwanted Nuisances and Biases in Speech to Text System using Adversarial Forgetting
Dec 01, 2020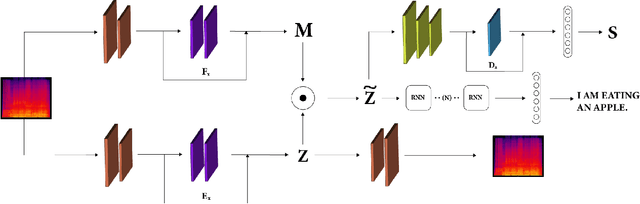

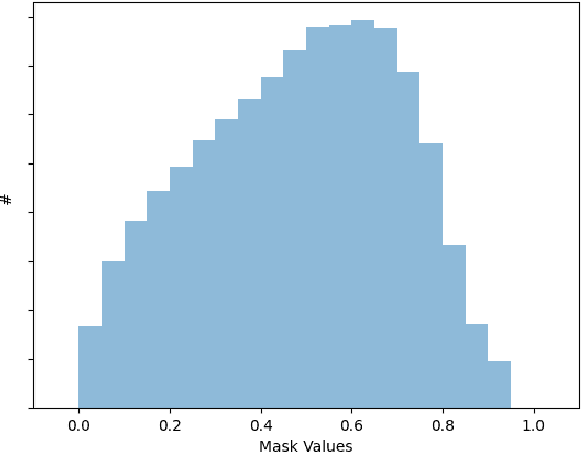
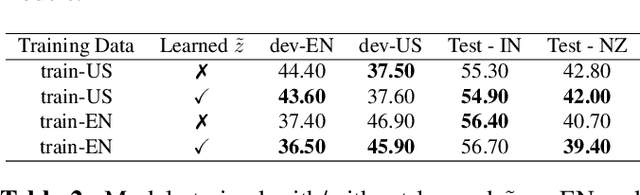
Training robust Speech to Text (STT) system require "tens of thousand" of hours of data. Variability present in the dataset, in the form of unwanted nuisances (noise) and biases (accent, gender or age) is the reason for the need of large datasets to learn general representations, which is unfeasible for low resource languages. A recently proposed deep learning approach to remove these unwanted features, called adversarial forgetting, was able to produce better results on computer vision tasks. Motivated by this, in this paper, we study the effect of de-entangling the accent information from the input speech signal on training STT systems. To this end, we use an information bottleneck architecture based on adversarial forgetting. This training scheme aims to enforce the model to learn general accent invariant speech representations. The trained STT model is tested on two unseen accents in the common voice V1. The results are in favour of STT model trained using the adversarial forgetting scheme.
MIDAS at SemEval-2020 Task 10: Emphasis Selection using Label Distribution Learning and Contextual Embeddings
Sep 06, 2020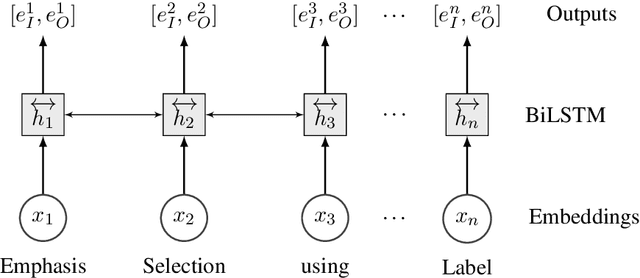
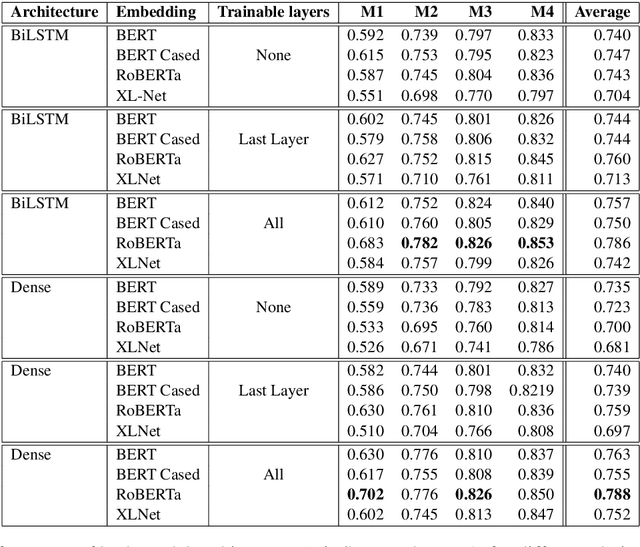


This paper presents our submission to the SemEval 2020 - Task 10 on emphasis selection in written text. We approach this emphasis selection problem as a sequence labeling task where we represent the underlying text with various contextual embedding models. We also employ label distribution learning to account for annotator disagreements. We experiment with the choice of model architectures, trainability of layers, and different contextual embeddings. Our best performing architecture is an ensemble of different models, which achieved an overall matching score of 0.783, placing us 15th out of 31 participating teams. Lastly, we analyze the results in terms of parts of speech tags, sentence lengths, and word ordering.