 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEGG: Replay via Maximally Extreme GGscore in Incremental Learning for Neural Recommendation Models
Sep 09, 2025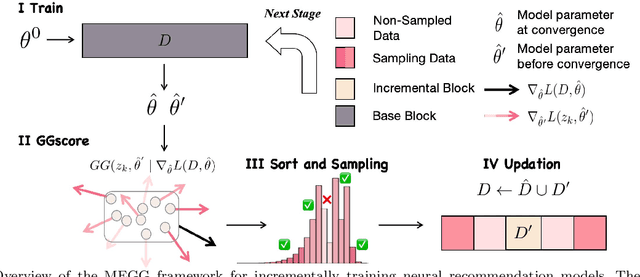
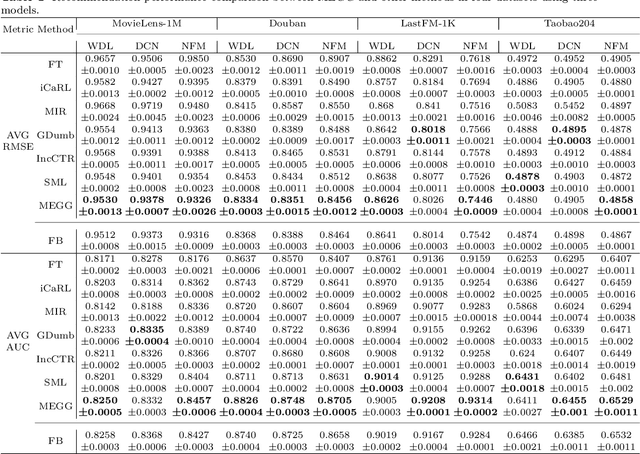
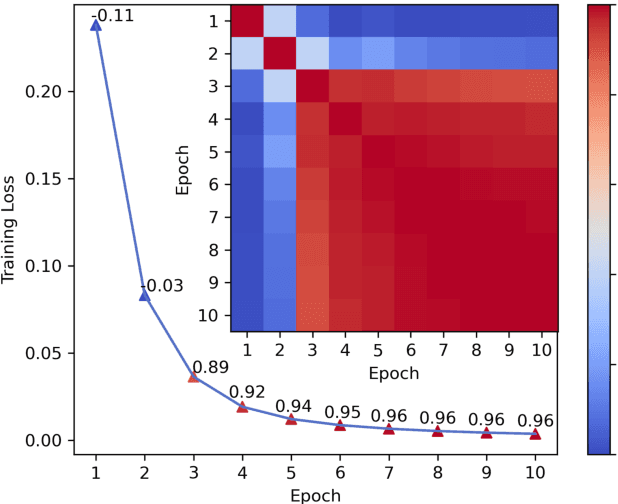
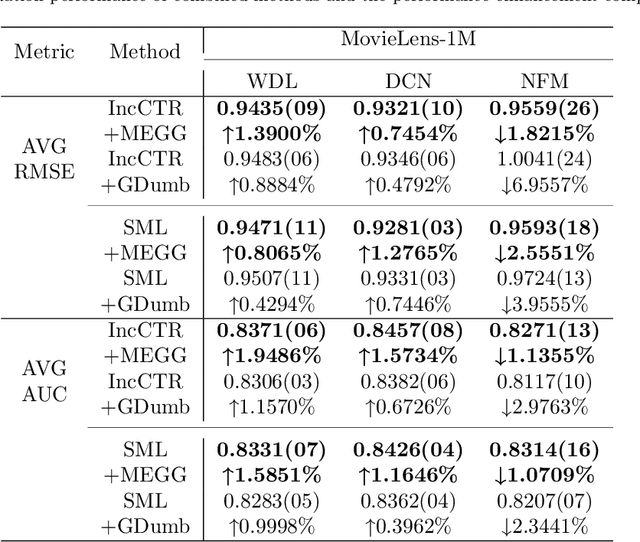
Neural Collaborative Filtering models are widely used in recommender systems but are typically trained under static settings, assuming fixed data distributions. This limits their applicability in dynamic environments where user preferences evolve. Incremental learning offers a promising solution, yet conventional methods from computer vision or NLP face challenges in recommendation tasks due to data sparsity and distinct task paradigms. Existing approaches for neural recommenders remain limited and often lack generalizability. To address this, we propose MEGG, Replay Samples with Maximally Extreme GGscore, an experience replay based incremental learning framework. MEGG introduces GGscore, a novel metric that quantifies sample influence, enabling the selective replay of highly influential samples to mitigate catastrophic forgetting. Being model-agnostic, MEGG integrates seamlessly across architectures and frameworks. Experiments on three neural models and four benchmark datasets show superior performance over state-of-the-art baselines, with strong scalability, efficiency, and robustness. Implementation will be released publicly upon acceptance.
Mitigating Knowledge Discrepancies among Multiple Datasets for Task-agnostic Unified Face Alignment
Mar 28, 2025


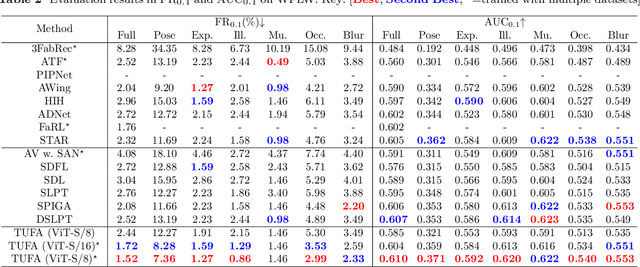
Despite the similar structures of human faces, existing face alignment methods cannot learn unified knowledge from multiple datasets with different landmark annotations. The limited training samples in a single dataset commonly result in fragile robustness in this field. To mitigate knowledge discrepancies among different datasets and train a task-agnostic unified face alignment (TUFA) framework, this paper presents a strategy to unify knowledge from multiple datasets. Specifically, we calculate a mean face shape for each dataset. To explicitly align these mean shapes on an interpretable plane based on their semantics, each shape is then incorporated with a group of semantic alignment embeddings. The 2D coordinates of these aligned shapes can be viewed as the anchors of the plane. By encoding them into structure prompts and further regressing the corresponding facial landmarks using image features, a mapping from the plane to the target faces is finally established, which unifies the learning target of different datasets. Consequently, multiple datasets can be utilized to boost the generalization ability of the model. The successful mitigation of discrepancies also enhances the efficiency of knowledge transferring to a novel dataset, significantly boosts the performance of few-shot face alignment. Additionally, the interpretable plane endows TUFA with a task-agnostic characteristic, enabling it to locate landmarks unseen during training in a zero-shot manner. Extensive experiments are carried on seven benchmarks and the results demonstrate an impressive improvement in face alignment brought by knowledge discrepancies mitigation.
A Learnable Agent Collaboration Network Framework for Personalized Multimodal AI Search Engine
Sep 01, 2024



Large language models (LLMs) and retrieval-augmented generation (RAG) techniques have revolutionized traditional information access, enabling AI agent to search and summarize information on behalf of users during dynamic dialogues. Despite their potential, current AI search engines exhibit considerable room for improvement in several critical areas. These areas include the support for multimodal information, the delivery of personalized responses, the capability to logically answer complex questions, and the facilitation of more flexible interactions. This paper proposes a novel AI Search Engine framework called the Agent Collaboration Network (ACN). The ACN framework consists of multiple specialized agents working collaboratively, each with distinct roles such as Account Manager, Solution Strategist, Information Manager, and Content Creator. This framework integrates mechanisms for picture content understanding, user profile tracking, and online evolution, enhancing the AI search engine's response quality, personalization, and interactivity. A highlight of the ACN is the introduction of a Reflective Forward Optimization method (RFO), which supports the online synergistic adjustment among agents. This feature endows the ACN with online learning capabilities, ensuring that the system has strong interactive flexibility and can promptly adapt to user feedback. This learning method may also serve as an optimization approach for agent-based systems, potentially influencing other domains of agent applications.
Beyond KAN: Introducing KarSein for Adaptive High-Order Feature Interaction Modeling in CTR Prediction
Aug 16, 2024


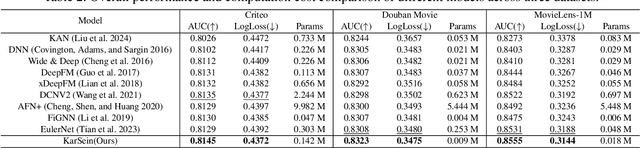
Modeling feature interactions is crucial for click-through rate (CTR) prediction, particularly when it comes to high-order explicit interactions. Traditional methods struggle with this task because they often predefine a maximum interaction order, which relies heavily on prior knowledge and can limit the model's effectiveness. Additionally, modeling high-order interactions typically leads to increased computational costs. Therefore, the challenge lies in adaptively modeling high-order feature interactions while maintaining efficiency. To address this issue, we introduce Kolmogorov-Arnold Represented Sparse Efficient Interaction Network (KarSein), designed to optimize both predictive accuracy and computational efficiency. We firstly identify limitations of directly applying Kolmogorov-Arnold Networks (KAN) to CTR and then introduce KarSein to overcome these issues. It features a novel architecture that reduces the computational costs of KAN and supports embedding vectors as feature inputs. Additionally, KarSein employs guided symbolic regression to address the challenge of KAN in spontaneously learning multiplicative relationships. Extensive experiments demonstrate KarSein's superior performance, achieving significant predictive accuracy with minimal computational overhead. Furthermore, KarSein maintains strong global explainability while enabling the removal of redundant features, resulting in a sparse network structure. These advantages also position KarSein as a promising method for efficient inference.
Unsupervised Part Discovery via Dual Representation Alignment
Aug 15, 2024



Object parts serve as crucial intermediate representations in various downstream tasks, but part-level representation learning still has not received as much attention as other vision tasks. Previous research has established that Vision Transformer can learn instance-level attention without labels, extracting high-quality instance-level representations for boosting downstream tasks. In this paper, we achieve unsupervised part-specific attention learning using a novel paradigm and further employ the part representations to improve part discovery performance. Specifically, paired images are generated from the same image with different geometric transformations, and multiple part representations are extracted from these paired images using a novel module, named PartFormer. These part representations from the paired images are then exchanged to improve geometric transformation invariance. Subsequently, the part representations are aligned with the feature map extracted by a feature map encoder, achieving high similarity with the pixel representations of the corresponding part regions and low similarity in irrelevant regions. Finally, the geometric and semantic constraints are applied to the part representations through the intermediate results in alignment for part-specific attention learning, encouraging the PartFormer to focus locally and the part representations to explicitly include the information of the corresponding parts. Moreover, the aligned part representations can further serve as a series of reliable detectors in the testing phase, predicting pixel masks for part discovery. Extensive experiments are carried out on four widely used datasets, and our results demonstrate that the proposed method achieves competitive performance and robustness due to its part-specific attention.
Enhancing Retrieval and Managing Retrieval: A Four-Module Synergy for Improved Quality and Efficiency in RAG Systems
Jul 15, 2024
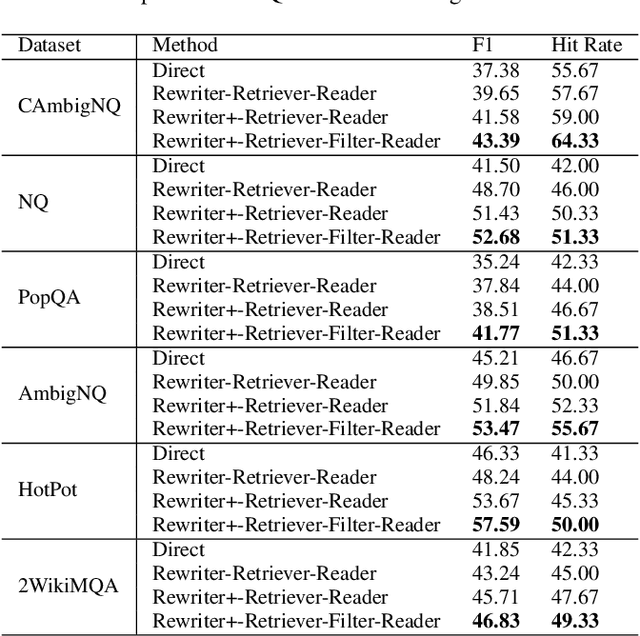


Retrieval-augmented generation (RAG) techniques leverage the in-context learning capabilities of large language models (LLMs) to produce more accurate and relevant responses. Originating from the simple 'retrieve-then-read' approach, the RAG framework has evolved into a highly flexible and modular paradigm. A critical component, the Query Rewriter module, enhances knowledge retrieval by generating a search-friendly query. This method aligns input questions more closely with the knowledge base. Our research identifies opportunities to enhance the Query Rewriter module to Query Rewriter+ by generating multiple queries to overcome the Information Plateaus associated with a single query and by rewriting questions to eliminate Ambiguity, thereby clarifying the underlying intent. We also find that current RAG systems exhibit issues with Irrelevant Knowledge; to overcome this, we propose the Knowledge Filter. These two modules are both based on the instruction-tuned Gemma-2B model, which together enhance response quality. The final identified issue is Redundant Retrieval; we introduce the Memory Knowledge Reservoir and the Retriever Trigger to solve this. The former supports the dynamic expansion of the RAG system's knowledge base in a parameter-free manner, while the latter optimizes the cost for accessing external knowledge, thereby improving resource utilization and response efficiency. These four RAG modules synergistically improve the response quality and efficiency of the RAG system. The effectiveness of these modules has been validated through experiments and ablation studies across six common QA datasets. The source code can be accessed at https://github.com/Ancientshi/ERM4.
Differential Encoding for Improved Representation Learning over Graphs
Jul 03, 2024



Combining the message-passing paradigm with the global attention mechanism has emerged as an effective framework for learning over graphs. The message-passing paradigm and the global attention mechanism fundamentally generate node embeddings based on information aggregated from a node's local neighborhood or from the whole graph. The most basic and commonly used aggregation approach is to take the sum of information from a node's local neighbourhood or from the whole graph. However, it is unknown if the dominant information is from a node itself or from the node's neighbours (or the rest of the graph nodes). Therefore, there exists information lost at each layer of embedding generation, and this information lost could be accumulated and become more serious when more layers are used in the model. In this paper, we present a differential encoding method to address the issue of information lost. The idea of our method is to encode the differential representation between the information from a node's neighbours (or the rest of the graph nodes) and that from the node itself. The obtained differential encoding is then combined with the original aggregated local or global representation to generate the updated node embedding. By integrating differential encodings, the representational ability of generated node embeddings is improved. The differential encoding method is empirically evaluated on different graph tasks on seven benchmark datasets. The results show that it is a general method that improves the message-passing update and the global attention update, advancing the state-of-the-art performance for graph representation learning on these datasets.
Conditional Local Feature Encoding for Graph Neural Networks
May 08, 2024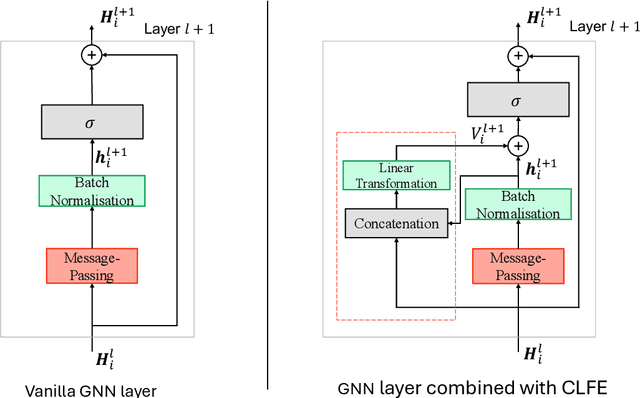
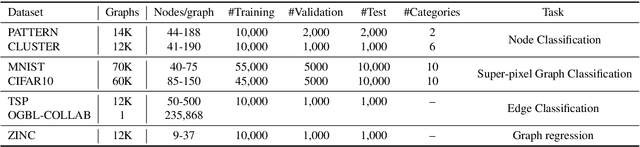
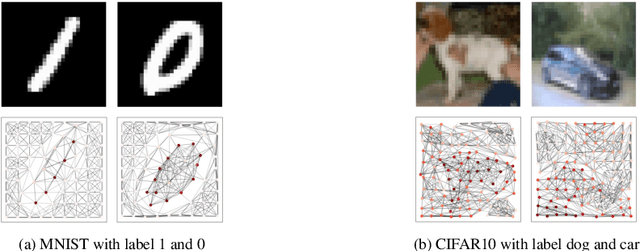

Graph neural networks (GNNs) have shown great success in learning from graph-based data. The key mechanism of current GNNs is message passing, where a node's feature is updated based on the information passing from its local neighbourhood. A limitation of this mechanism is that node features become increasingly dominated by the information aggregated from the neighbourhood as we use more rounds of message passing. Consequently, as the GNN layers become deeper, adjacent node features tends to be similar, making it more difficult for GNNs to distinguish adjacent nodes, thereby, limiting the performance of GNNs. In this paper, we propose conditional local feature encoding (CLFE) to help prevent the problem of node features being dominated by the information from local neighbourhood. The idea of our method is to extract the node hidden state embedding from message passing process and concatenate it with the nodes feature from previous stage, then we utilise linear transformation to form a CLFE based on the concatenated vector. The CLFE will form the layer output to better preserve node-specific information, thus help to improve the performance of GNN models. To verify the feasibility of our method, we conducted extensive experiments on seven benchmark datasets for four graph domain tasks: super-pixel graph classification, node classification, link prediction, and graph regression. The experimental results consistently demonstrate that our method improves model performance across a variety of baseline GNN models for all four tasks.
ERAGent: Enhancing Retrieval-Augmented Language Models with Improved Accuracy, Efficiency, and Personalization
May 06, 2024



Retrieval-augmented generation (RAG) for language models significantly improves language understanding systems. The basic retrieval-then-read pipeline of response generation has evolved into a more extended process due to the integration of various components, sometimes even forming loop structures. Despite its advancements in improving response accuracy, challenges like poor retrieval quality for complex questions that require the search of multifaceted semantic information, inefficiencies in knowledge re-retrieval during long-term serving, and lack of personalized responses persist. Motivated by transcending these limitations, we introduce ERAGent, a cutting-edge framework that embodies an advancement in the RAG area. Our contribution is the introduction of the synergistically operated module: Enhanced Question Rewriter and Knowledge Filter, for better retrieval quality. Retrieval Trigger is incorporated to curtail extraneous external knowledge retrieval without sacrificing response quality. ERAGent also personalizes responses by incorporating a learned user profile. The efficiency and personalization characteristics of ERAGent are supported by the Experiential Learner module which makes the AI assistant being capable of expanding its knowledge and modeling user profile incrementally. Rigorous evaluations across six datasets and three question-answering tasks prove ERAGent's superior accuracy, efficiency, and personalization, emphasizing its potential to advance the RAG field and its applicability in practical systems.
Neighbour-level Message Interaction Encoding for Improved Representation Learning on Graphs
Apr 15, 2024Message passing has become the dominant framework in graph representation learning. The essential idea of the message-passing framework is to update node embeddings based on the information aggregated from local neighbours. However, most existing aggregation methods have not encoded neighbour-level message interactions into the aggregated message, resulting in an information lost in embedding generation. And this information lost could be accumulated and become more serious as more layers are added to the graph network model. To address this issue, we propose a neighbour-level message interaction information encoding method for improving graph representation learning. For messages that are aggregated at a node, we explicitly generate an encoding between each message and the rest messages using an encoding function. Then we aggregate these learned encodings and take the sum of the aggregated encoding and the aggregated message to update the embedding for the node. By this way, neighbour-level message interaction information is integrated into the generated node embeddings. The proposed encoding method is a generic method which can be integrated into message-passing graph convolutional networks. Extensive experiments are conducted on six popular benchmark datasets across four highly-demanded tasks. The results show that integrating neighbour-level message interactions achieves improved performance of the base models, advancing the state of the art results for representation learning over graphs.