 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPLE: Latent Multi-Agent Play for End-to-End Autonomous Driving
May 13, 2026Vision-language-action (VLA) models are effective as end-to-end motion planners, but can be brittle when evaluated in closed-loop settings due to being trained under traditional imitation learning framework. Existing closed-loop supervision approaches lack scalability and fail to completely model a reactive environment. We propose MAPLE, a novel framework for reactive, multi-agent rollout of a dynamic driving scenario in the latent space of the VLA model. The ego vehicle and nearby traffic agents are independently controlled over multi-step horizons, while being reactive to other agents in the scene, enabling closed-loop training. MAPLE consists of two training stages: (1) supervised fine-tuning on the latent rollouts based on ground-truth trajectories, followed by (2) reinforcement learning with global and agent -specific rewards that encourage safety, progress, and interaction realism. We further propose diversity rewards that encourage the model to generate planning behaviors that may not be present in logged driving data. Notably, our closed-loop training framework is scalable and does not require external simulators, which can be computationally expensive to run and have limited visual fidelity to the real-world. MAPLE achieves state-of-the-art driving performance on Bench2Drive and demonstrates scalable, closed-loop multi-agent play for robust E2E autonomous driving systems.
AgentSelect: Benchmark for Narrative Query-to-Agent Recommendation
Mar 04, 2026LLM agents are rapidly becoming the practical interface for task automation, yet the ecosystem lacks a principled way to choose among an exploding space of deployable configurations. Existing LLM leaderboards and tool/agent benchmarks evaluate components in isolation and remain fragmented across tasks, metrics, and candidate pools, leaving a critical research gap: there is little query-conditioned supervision for learning to recommend end-to-end agent configurations that couple a backbone model with a toolkit. We address this gap with AgentSelect, a benchmark that reframes agent selection as narrative query-to-agent recommendation over capability profiles and systematically converts heterogeneous evaluation artifacts into unified, positive-only interaction data. AgentSelectcomprises 111,179 queries, 107,721 deployable agents, and 251,103 interaction records aggregated from 40+ sources, spanning LLM-only, toolkit-only, and compositional agents. Our analyses reveal a regime shift from dense head reuse to long-tail, near one-off supervision, where popularity-based CF/GNN methods become fragile and content-aware capability matching is essential. We further show that Part~III synthesized compositional interactions are learnable, induce capability-sensitive behavior under controlled counterfactual edits, and improve coverage over realistic compositions; models trained on AgentSelect also transfer to a public agent marketplace (MuleRun), yielding consistent gains on an unseen catalog. Overall, AgentSelect provides the first unified data and evaluation infrastructure for agent recommendation, which establishes a reproducible foundation to study and accelerate the emerging agent ecosystem.
Generative Scenario Rollouts for End-to-End Autonomous Driving
Jan 16, 2026Vision-Language-Action (VLA) models are emerging as highly effective planning models for end-to-end autonomous driving systems. However, current works mostly rely on imitation learning from sparse trajectory annotations and under-utilize their potential as generative models. We propose Generative Scenario Rollouts (GeRo), a plug-and-play framework for VLA models that jointly performs planning and generation of language-grounded future traffic scenes through an autoregressive rollout strategy. First, a VLA model is trained to encode ego vehicle and agent dynamics into latent tokens under supervision from planning, motion, and language tasks, facilitating text-aligned generation. Next, GeRo performs language-conditioned autoregressive generation. Given multi-view images, a scenario description, and ego-action questions, it generates future latent tokens and textual responses to guide long-horizon rollouts. A rollout-consistency loss stabilizes predictions using ground truth or pseudo-labels, mitigating drift and preserving text-action alignment. This design enables GeRo to perform temporally consistent, language-grounded rollouts that support long-horizon reasoning and multi-agent planning. On Bench2Drive, GeRo improves driving score and success rate by +15.7 and +26.2, respectively. By integrating reinforcement learning with generative rollouts, GeRo achieves state-of-the-art closed-loop and open-loop performance, demonstrating strong zero-shot robustness. These results highlight the promise of generative, language-conditioned reasoning as a foundation for safer and more interpretable end-to-end autonomous driving.
Accumulative SGD Influence Estimation for Data Attribution
Oct 30, 2025Modern data-centric AI needs precise per-sample influence. Standard SGD-IE approximates leave-one-out effects by summing per-epoch surrogates and ignores cross-epoch compounding, which misranks critical examples. We propose ACC-SGD-IE, a trajectory-aware estimator that propagates the leave-one-out perturbation across training and updates an accumulative influence state at each step. In smooth strongly convex settings it achieves geometric error contraction and, in smooth non-convex regimes, it tightens error bounds; larger mini-batches further reduce constants. Empirically, on Adult, 20 Newsgroups, and MNIST under clean and corrupted data and both convex and non-convex training, ACC-SGD-IE yields more accurate influence estimates, especially over long epochs. For downstream data cleansing it more reliably flags noisy samples, producing models trained on ACC-SGD-IE cleaned data that outperform those cleaned with SGD-IE.
MEGG: Replay via Maximally Extreme GGscore in Incremental Learning for Neural Recommendation Models
Sep 09, 2025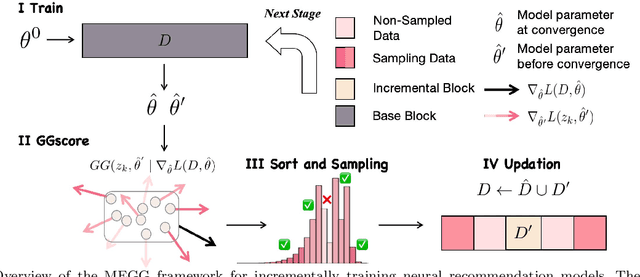
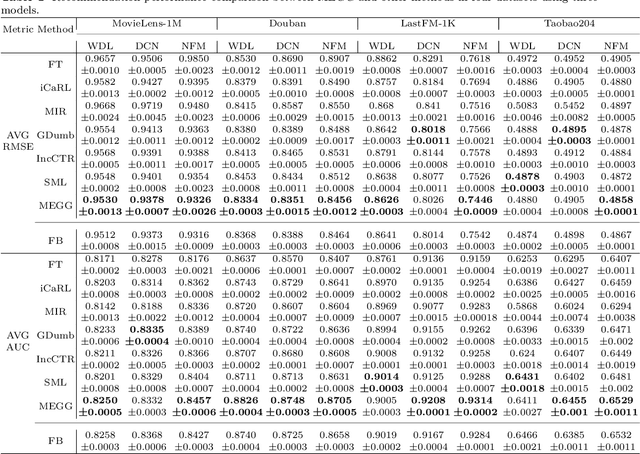
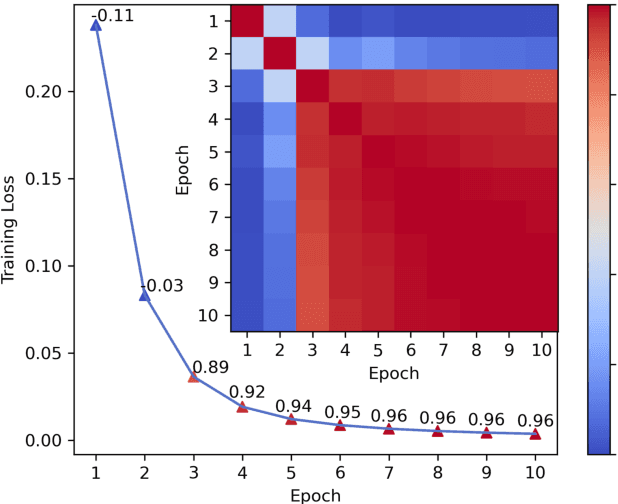
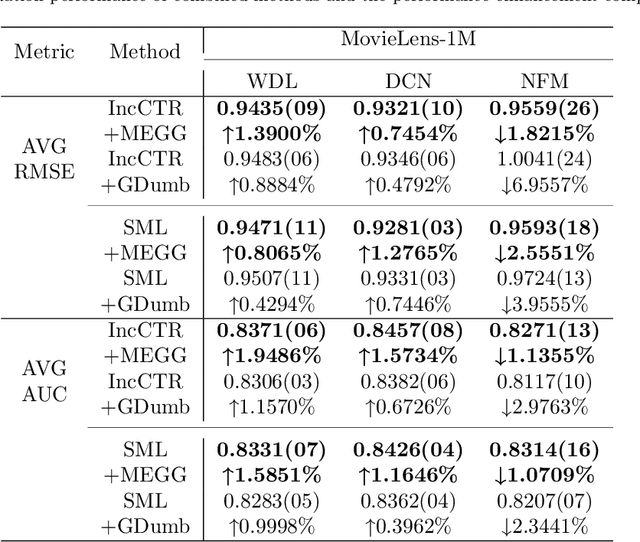
Neural Collaborative Filtering models are widely used in recommender systems but are typically trained under static settings, assuming fixed data distributions. This limits their applicability in dynamic environments where user preferences evolve. Incremental learning offers a promising solution, yet conventional methods from computer vision or NLP face challenges in recommendation tasks due to data sparsity and distinct task paradigms. Existing approaches for neural recommenders remain limited and often lack generalizability. To address this, we propose MEGG, Replay Samples with Maximally Extreme GGscore, an experience replay based incremental learning framework. MEGG introduces GGscore, a novel metric that quantifies sample influence, enabling the selective replay of highly influential samples to mitigate catastrophic forgetting. Being model-agnostic, MEGG integrates seamlessly across architectures and frameworks. Experiments on three neural models and four benchmark datasets show superior performance over state-of-the-art baselines, with strong scalability, efficiency, and robustness. Implementation will be released publicly upon acceptance.
sam-llm: interpretable lane change trajectoryprediction via parametric finetuning
Sep 03, 2025This work introduces SAM-LLM, a novel hybrid architecture that bridges the gap between the contextual reasoning of Large Language Models (LLMs) and the physical precision of kinematic lane change models for autonomous driving. The system is designed for interpretable lane change trajectory prediction by finetuning an LLM to output the core physical parameters of a trajectory model instead of raw coordinates. For lane-keeping scenarios, the model predicts discrete coordinates, but for lane change maneuvers, it generates the parameters for an enhanced Sinusoidal Acceleration Model (SAM), including lateral displacement, maneuver duration, initial lateral velocity, and longitudinal velocity change. This parametric approach yields a complete, continuous, and physically plausible trajectory model that is inherently interpretable and computationally efficient, achieving an 80% reduction in output size compared to coordinate-based methods. The SAM-LLM achieves a state-of-the-art overall intention prediction accuracy of 98.73%, demonstrating performance equivalent to traditional LLM predictors while offering significant advantages in explainability and resource efficiency.
RSVLM-QA: A Benchmark Dataset for Remote Sensing Vision Language Model-based Question Answering
Aug 11, 2025Visual Question Answering (VQA) in remote sensing (RS) is pivotal for interpreting Earth observation data. However, existing RS VQA datasets are constrained by limitations in annotation richness, question diversity, and the assessment of specific reasoning capabilities. This paper introduces RSVLM-QA dataset, a new large-scale, content-rich VQA dataset for the RS domain. RSVLM-QA is constructed by integrating data from several prominent RS segmentation and detection datasets: WHU, LoveDA, INRIA, and iSAID. We employ an innovative dual-track annotation generation pipeline. Firstly, we leverage Large Language Models (LLMs), specifically GPT-4.1, with meticulously designed prompts to automatically generate a suite of detailed annotations including image captions, spatial relations, and semantic tags, alongside complex caption-based VQA pairs. Secondly, to address the challenging task of object counting in RS imagery, we have developed a specialized automated process that extracts object counts directly from the original segmentation data; GPT-4.1 then formulates natural language answers from these counts, which are paired with preset question templates to create counting QA pairs. RSVLM-QA comprises 13,820 images and 162,373 VQA pairs, featuring extensive annotations and diverse question types. We provide a detailed statistical analysis of the dataset and a comparison with existing RS VQA benchmarks, highlighting the superior depth and breadth of RSVLM-QA's annotations. Furthermore, we conduct benchmark experiments on Six mainstream Vision Language Models (VLMs), demonstrating that RSVLM-QA effectively evaluates and challenges the understanding and reasoning abilities of current VLMs in the RS domain. We believe RSVLM-QA will serve as a pivotal resource for the RS VQA and VLM research communities, poised to catalyze advancements in the field.
ODG: Occupancy Prediction Using Dual Gaussians
Jun 12, 2025Occupancy prediction infers fine-grained 3D geometry and semantics from camera images of the surrounding environment, making it a critical perception task for autonomous driving. Existing methods either adopt dense grids as scene representation, which is difficult to scale to high resolution, or learn the entire scene using a single set of sparse queries, which is insufficient to handle the various object characteristics. In this paper, we present ODG, a hierarchical dual sparse Gaussian representation to effectively capture complex scene dynamics. Building upon the observation that driving scenes can be universally decomposed into static and dynamic counterparts, we define dual Gaussian queries to better model the diverse scene objects. We utilize a hierarchical Gaussian transformer to predict the occupied voxel centers and semantic classes along with the Gaussian parameters. Leveraging the real-time rendering capability of 3D Gaussian Splatting, we also impose rendering supervision with available depth and semantic map annotations injecting pixel-level alignment to boost occupancy learning. Extensive experiments on the Occ3D-nuScenes and Occ3D-Waymo benchmarks demonstrate our proposed method sets new state-of-the-art results while maintaining low inference cost.
RoCA: Robust Cross-Domain End-to-End Autonomous Driving
Jun 11, 2025End-to-end (E2E) autonomous driving has recently emerged as a new paradigm, offering significant potential. However, few studies have looked into the practical challenge of deployment across domains (e.g., cities). Although several works have incorporated Large Language Models (LLMs) to leverage their open-world knowledge, LLMs do not guarantee cross-domain driving performance and may incur prohibitive retraining costs during domain adaptation. In this paper, we propose RoCA, a novel framework for robust cross-domain E2E autonomous driving. RoCA formulates the joint probabilistic distribution over the tokens that encode ego and surrounding vehicle information in the E2E pipeline. Instantiating with a Gaussian process (GP), RoCA learns a set of basis tokens with corresponding trajectories, which span diverse driving scenarios. Then, given any driving scene, it is able to probabilistically infer the future trajectory. By using RoCA together with a base E2E model in source-domain training, we improve the generalizability of the base model, without requiring extra inference computation. In addition, RoCA enables robust adaptation on new target domains, significantly outperforming direct finetuning. We extensively evaluate RoCA on various cross-domain scenarios and show that it achieves strong domain generalization and adaptation performance.
BePo: Leveraging Birds Eye View and Sparse Points for Efficient and Accurate 3D Occupancy Prediction
Jun 08, 20253D occupancy provides fine-grained 3D geometry and semantics for scene understanding which is critical for autonomous driving. Most existing methods, however, carry high compute costs, requiring dense 3D feature volume and cross-attention to effectively aggregate information. More recent works have adopted Bird's Eye View (BEV) or sparse points as scene representation with much reduced cost, but still suffer from their respective shortcomings. More concretely, BEV struggles with small objects that often experience significant information loss after being projected to the ground plane. On the other hand, points can flexibly model little objects in 3D, but is inefficient at capturing flat surfaces or large objects. To address these challenges, in this paper, we present a novel 3D occupancy prediction approach, BePo, which combines BEV and sparse points based representations. We propose a dual-branch design: a query-based sparse points branch and a BEV branch. The 3D information learned in the sparse points branch is shared with the BEV stream via cross-attention, which enriches the weakened signals of difficult objects on the BEV plane. The outputs of both branches are finally fused to generate predicted 3D occupancy. We conduct extensive experiments on the Occ3D-nuScenes and Occ3D-Waymo benchmarks that demonstrate the superiority of our proposed BePo. Moreover, BePo also delivers competitive inference speed when compared to the latest efficient approaches.