 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODG: Occupancy Prediction Using Dual Gaussians
Jun 12, 2025Occupancy prediction infers fine-grained 3D geometry and semantics from camera images of the surrounding environment, making it a critical perception task for autonomous driving. Existing methods either adopt dense grids as scene representation, which is difficult to scale to high resolution, or learn the entire scene using a single set of sparse queries, which is insufficient to handle the various object characteristics. In this paper, we present ODG, a hierarchical dual sparse Gaussian representation to effectively capture complex scene dynamics. Building upon the observation that driving scenes can be universally decomposed into static and dynamic counterparts, we define dual Gaussian queries to better model the diverse scene objects. We utilize a hierarchical Gaussian transformer to predict the occupied voxel centers and semantic classes along with the Gaussian parameters. Leveraging the real-time rendering capability of 3D Gaussian Splatting, we also impose rendering supervision with available depth and semantic map annotations injecting pixel-level alignment to boost occupancy learning. Extensive experiments on the Occ3D-nuScenes and Occ3D-Waymo benchmarks demonstrate our proposed method sets new state-of-the-art results while maintaining low inference cost.
BePo: Leveraging Birds Eye View and Sparse Points for Efficient and Accurate 3D Occupancy Prediction
Jun 08, 20253D occupancy provides fine-grained 3D geometry and semantics for scene understanding which is critical for autonomous driving. Most existing methods, however, carry high compute costs, requiring dense 3D feature volume and cross-attention to effectively aggregate information. More recent works have adopted Bird's Eye View (BEV) or sparse points as scene representation with much reduced cost, but still suffer from their respective shortcomings. More concretely, BEV struggles with small objects that often experience significant information loss after being projected to the ground plane. On the other hand, points can flexibly model little objects in 3D, but is inefficient at capturing flat surfaces or large objects. To address these challenges, in this paper, we present a novel 3D occupancy prediction approach, BePo, which combines BEV and sparse points based representations. We propose a dual-branch design: a query-based sparse points branch and a BEV branch. The 3D information learned in the sparse points branch is shared with the BEV stream via cross-attention, which enriches the weakened signals of difficult objects on the BEV plane. The outputs of both branches are finally fused to generate predicted 3D occupancy. We conduct extensive experiments on the Occ3D-nuScenes and Occ3D-Waymo benchmarks that demonstrate the superiority of our proposed BePo. Moreover, BePo also delivers competitive inference speed when compared to the latest efficient approaches.
H3O: Hyper-Efficient 3D Occupancy Prediction with Heterogeneous Supervision
Mar 06, 20253D occupancy prediction has recently emerged as a new paradigm for holistic 3D scene understanding and provides valuable information for downstream planning in autonomous driving. Most existing methods, however, are computationally expensive, requiring costly attention-based 2D-3D transformation and 3D feature processing. In this paper, we present a novel 3D occupancy prediction approach, H3O, which features highly efficient architecture designs that incur a significantly lower computational cost as compared to the current state-of-the-art methods. In addition, to compensate for the ambiguity in ground-truth 3D occupancy labels, we advocate leveraging auxiliary tasks to complement the direct 3D supervision. In particular, we integrate multi-camera depth estimation, semantic segmentation, and surface normal estimation via differentiable volume rendering, supervised by corresponding 2D labels that introduces rich and heterogeneous supervision signals. We conduct extensive experiments on the Occ3D-nuScenes and SemanticKITTI benchmarks that demonstrate the superiority of our proposed H3O.
EGA-Depth: Efficient Guided Attention for Self-Supervised Multi-Camera Depth Estimation
Apr 06, 2023The ubiquitous multi-camera setup on modern autonomous vehicles provides an opportunity to construct surround-view depth. Existing methods, however, either perform independent monocular depth estimations on each camera or rely on computationally heavy self attention mechanisms. In this paper, we propose a novel guided attention architecture, EGA-Depth, which can improve both the efficiency and accuracy of self-supervised multi-camera depth estimation. More specifically, for each camera, we use its perspective view as the query to cross-reference its neighboring views to derive informative features for this camera view. This allows the model to perform attention only across views with considerable overlaps and avoid the costly computations of standard self-attention. Given its efficiency, EGA-Depth enables us to exploit higher-resolution visual features, leading to improved accuracy. Furthermore, EGA-Depth can incorporate more frames from previous time steps as it scales linearly w.r.t. the number of views and frames. Extensive experiments on two challenging autonomous driving benchmarks nuScenes and DDAD demonstrate the efficacy of our proposed EGA-Depth and show that it achieves the new state-of-the-art in self-supervised multi-camera depth estimation.
X-Distill: Improving Self-Supervised Monocular Depth via Cross-Task Distillation
Oct 24, 2021
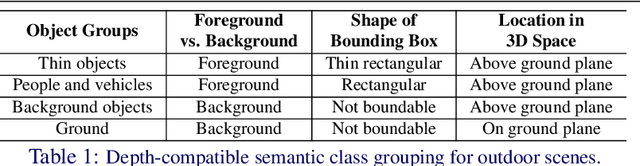

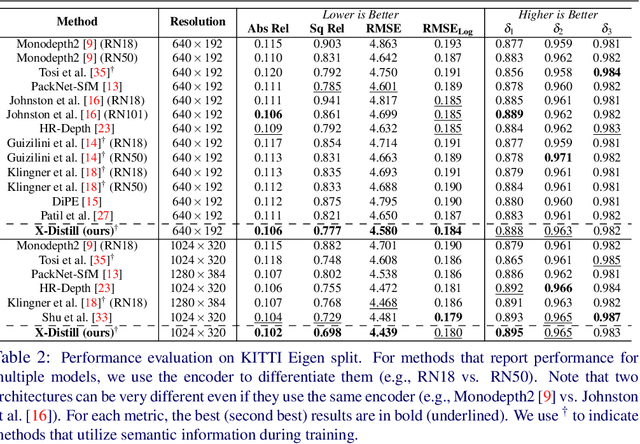
In this paper, we propose a novel method, X-Distill, to improve the self-supervised training of monocular depth via cross-task knowledge distillation from semantic segmentation to depth estimation. More specifically, during training, we utilize a pretrained semantic segmentation teacher network and transfer its semantic knowledge to the depth network. In order to enable such knowledge distillation across two different visual tasks, we introduce a small, trainable network that translates the predicted depth map to a semantic segmentation map, which can then be supervised by the teacher network. In this way, this small network enables the backpropagation from the semantic segmentation teacher's supervision to the depth network during training. In addition, since the commonly used object classes in semantic segmentation are not directly transferable to depth, we study the visual and geometric characteristics of the objects and design a new way of grouping them that can be shared by both tasks. It is noteworthy that our approach only modifies the training process and does not incur additional computation during inference. We extensively evaluate the efficacy of our proposed approach on the standard KITTI benchmark and compare it with the latest state of the art. We further test the generalizability of our approach on Make3D. Overall, the results show that our approach significantly improves the depth estimation accuracy and outperforms the state of the art.