 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Distill: Improving Self-Supervised Monocular Depth via Cross-Task Distillation
Paper and Code
Oct 24, 2021
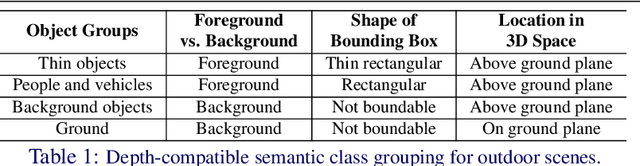

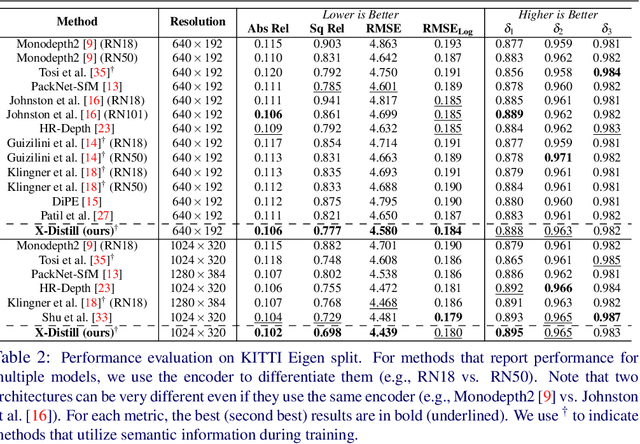
In this paper, we propose a novel method, X-Distill, to improve the self-supervised training of monocular depth via cross-task knowledge distillation from semantic segmentation to depth estimation. More specifically, during training, we utilize a pretrained semantic segmentation teacher network and transfer its semantic knowledge to the depth network. In order to enable such knowledge distillation across two different visual tasks, we introduce a small, trainable network that translates the predicted depth map to a semantic segmentation map, which can then be supervised by the teacher network. In this way, this small network enables the backpropagation from the semantic segmentation teacher's supervision to the depth network during training. In addition, since the commonly used object classes in semantic segmentation are not directly transferable to depth, we study the visual and geometric characteristics of the objects and design a new way of grouping them that can be shared by both tasks. It is noteworthy that our approach only modifies the training process and does not incur additional computation during inference. We extensively evaluate the efficacy of our proposed approach on the standard KITTI benchmark and compare it with the latest state of the art. We further test the generalizability of our approach on Make3D. Overall, the results show that our approach significantly improves the depth estimation accuracy and outperforms the state of the art.