 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Out-of-Distribution Detection to Hallucination Detection: A Geometric View
Feb 06, 2026Detecting hallucinations in large language models is a critical open problem with significant implications for safety and reliability. While existing hallucination detection methods achieve strong performance in question-answering tasks, they remain less effective on tasks requiring reasoning. In this work, we revisit hallucination detection through the lens of out-of-distribution (OOD) detection, a well-studied problem in areas like computer vision. Treating next-token prediction in language models as a classification task allows us to apply OOD techniques, provided appropriate modifications are made to account for the structural differences in large language models. We show that OOD-based approaches yield training-free, single-sample-based detectors, achieving strong accuracy in hallucination detection for reasoning tasks. Overall, our work suggests that reframing hallucination detection as OOD detection provides a promising and scalable pathway toward language model safety.
Generative Scenario Rollouts for End-to-End Autonomous Driving
Jan 16, 2026Vision-Language-Action (VLA) models are emerging as highly effective planning models for end-to-end autonomous driving systems. However, current works mostly rely on imitation learning from sparse trajectory annotations and under-utilize their potential as generative models. We propose Generative Scenario Rollouts (GeRo), a plug-and-play framework for VLA models that jointly performs planning and generation of language-grounded future traffic scenes through an autoregressive rollout strategy. First, a VLA model is trained to encode ego vehicle and agent dynamics into latent tokens under supervision from planning, motion, and language tasks, facilitating text-aligned generation. Next, GeRo performs language-conditioned autoregressive generation. Given multi-view images, a scenario description, and ego-action questions, it generates future latent tokens and textual responses to guide long-horizon rollouts. A rollout-consistency loss stabilizes predictions using ground truth or pseudo-labels, mitigating drift and preserving text-action alignment. This design enables GeRo to perform temporally consistent, language-grounded rollouts that support long-horizon reasoning and multi-agent planning. On Bench2Drive, GeRo improves driving score and success rate by +15.7 and +26.2, respectively. By integrating reinforcement learning with generative rollouts, GeRo achieves state-of-the-art closed-loop and open-loop performance, demonstrating strong zero-shot robustness. These results highlight the promise of generative, language-conditioned reasoning as a foundation for safer and more interpretable end-to-end autonomous driving.
RoCA: Robust Cross-Domain End-to-End Autonomous Driving
Jun 11, 2025End-to-end (E2E) autonomous driving has recently emerged as a new paradigm, offering significant potential. However, few studies have looked into the practical challenge of deployment across domains (e.g., cities). Although several works have incorporated Large Language Models (LLMs) to leverage their open-world knowledge, LLMs do not guarantee cross-domain driving performance and may incur prohibitive retraining costs during domain adaptation. In this paper, we propose RoCA, a novel framework for robust cross-domain E2E autonomous driving. RoCA formulates the joint probabilistic distribution over the tokens that encode ego and surrounding vehicle information in the E2E pipeline. Instantiating with a Gaussian process (GP), RoCA learns a set of basis tokens with corresponding trajectories, which span diverse driving scenarios. Then, given any driving scene, it is able to probabilistically infer the future trajectory. By using RoCA together with a base E2E model in source-domain training, we improve the generalizability of the base model, without requiring extra inference computation. In addition, RoCA enables robust adaptation on new target domains, significantly outperforming direct finetuning. We extensively evaluate RoCA on various cross-domain scenarios and show that it achieves strong domain generalization and adaptation performance.
Distilling Multi-modal Large Language Models for Autonomous Driving
Jan 16, 2025
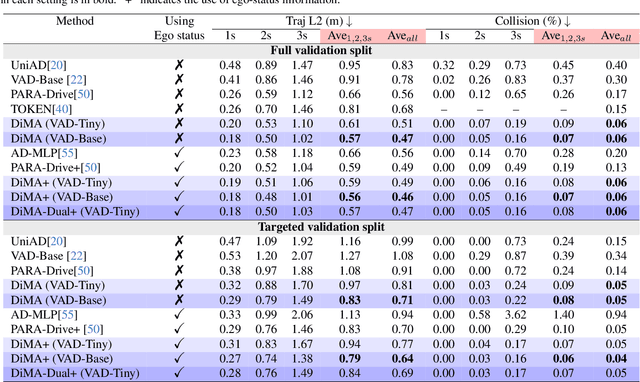

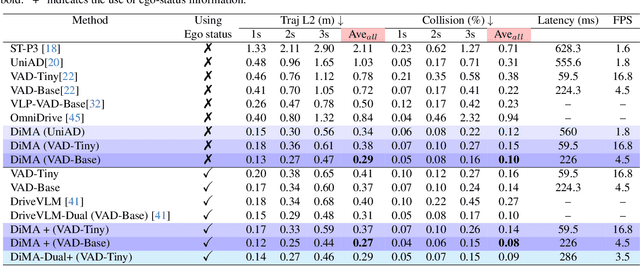
Autonomous driving demands safe motion planning, especially in critical "long-tail" scenarios. Recent end-to-end autonomous driving systems leverage large language models (LLMs) as planners to improve generalizability to rare events. However, using LLMs at test time introduces high computational costs. To address this, we propose DiMA, an end-to-end autonomous driving system that maintains the efficiency of an LLM-free (or vision-based) planner while leveraging the world knowledge of an LLM. DiMA distills the information from a multi-modal LLM to a vision-based end-to-end planner through a set of specially designed surrogate tasks. Under a joint training strategy, a scene encoder common to both networks produces structured representations that are semantically grounded as well as aligned to the final planning objective. Notably, the LLM is optional at inference, enabling robust planning without compromising on efficiency. Training with DiMA results in a 37% reduction in the L2 trajectory error and an 80% reduction in the collision rate of the vision-based planner, as well as a 44% trajectory error reduction in longtail scenarios. DiMA also achieves state-of-the-art performance on the nuScenes planning benchmark.
Fast Decision Boundary based Out-of-Distribution Detector
Dec 15, 2023Efficient and effective Out-of-Distribution (OOD) detection is essential for the safe deployment of AI in latency-critical applications. Recently, studies have revealed that detecting OOD based on feature space information can be highly effective. Despite their effectiveness, however, exiting feature space OOD methods may incur non-negligible computational overhead, given their reliance on auxiliary models built from training features. In this paper, we aim to obviate auxiliary models to optimize computational efficiency while leveraging the rich information embedded in the feature space. We investigate from the novel perspective of decision boundaries and propose to detect OOD using the feature distance to decision boundaries. To minimize the cost of measuring the distance, we introduce an efficient closed-form estimation, analytically proven to tightly lower bound the distance. We observe that ID features tend to reside further from the decision boundaries than OOD features. Our observation aligns with the intuition that models tend to be more decisive on ID samples, considering that distance to decision boundaries quantifies model uncertainty. From our understanding, we propose a hyperparameter-free, auxiliary model-free OOD detector. Our OOD detector matches or surpasses the effectiveness of state-of-the-art methods across extensive experiments. Meanwhile, our OOD detector incurs practically negligible overhead in inference latency. Overall, we significantly enhance the efficiency-effectiveness trade-off in OOD detection.
Detecting Out-of-Distribution Through the Lens of Neural Collapse
Nov 07, 2023Out-of-distribution (OOD) detection is essential for the safe deployment of AI. Particularly, OOD detectors should generalize effectively across diverse scenarios. To improve upon the generalizability of existing OOD detectors, we introduce a highly versatile OOD detector, called Neural Collapse inspired OOD detector (NC-OOD). We extend the prevalent observation that in-distribution (ID) features tend to form clusters, whereas OOD features are far away. Particularly, based on the recent observation, Neural Collapse, we further demonstrate that ID features tend to cluster in proximity to weight vectors. From our extended observation, we propose to detect OOD based on feature proximity to weight vectors. To further rule out OOD samples, we leverage the observation that OOD features tend to reside closer to the origin than ID features. Extensive experiments show that our approach enhances the generalizability of existing work and can consistently achieve state-of-the-art OOD detection performance across a wide range of OOD Benchmarks over different classification tasks, training losses, and model architectures.
A Coding Theory Perspective on Multiplexed Molecular Profiling of Biological Tissues
Feb 02, 2021


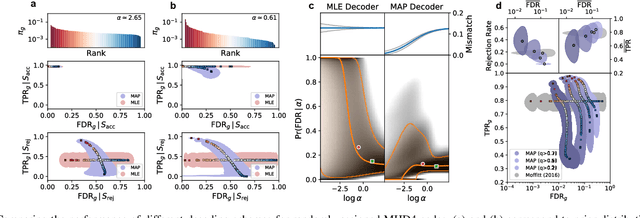
High-throughput and quantitative experimental technologies are experiencing rapid advances in the biological sciences. One important recent technique is multiplexed fluorescence in situ hybridization (mFISH), which enables the identification and localization of large numbers of individual strands of RNA within single cells. Core to that technology is a coding problem: with each RNA sequence of interest being a codeword, how to design a codebook of probes, and how to decode the resulting noisy measurements? Published work has relied on assumptions of uniformly distributed codewords and binary symmetric channels for decoding and to a lesser degree for code construction. Here we establish that both of these assumptions are inappropriate in the context of mFISH experiments and substantial decoding performance gains can be obtained by using more appropriate, less classical, assumptions. We propose a more appropriate asymmetric channel model that can be readily parameterized from data and use it to develop a maximum a posteriori (MAP) decoders. We show that false discovery rate for rare RNAs, which is the key experimental metric, is vastly improved with MAP decoders even when employed with the existing sub-optimal codebook. Using an evolutionary optimization methodology, we further show that by permuting the codebook to better align with the prior, which is an experimentally straightforward procedure, significant further improvements are possible.