 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnglish is Not All You Need: Systematically Exploring the Role of Multilinguality in LLM Post-Training
Apr 14, 2026Despite the widespread multilingual deployment of large language models, post-training pipelines remain predominantly English-centric, contributing to performance disparities across languages. We present a systematic, controlled study of the interplay between training language coverage, model scale, and task domain, based on 220 supervised fine-tuning runs on parallel translated multilingual data mixtures spanning mathematical reasoning and API calling tasks, with models up to 8B parameters. We find that increasing language coverage during post-training is largely beneficial across tasks and model scales, with low-resource languages benefiting the most and high-resource languages plateauing rather than degrading. Even minimal multilinguality helps: incorporating a single non-English language improves both English performance and cross-lingual generalization, making English-only post-training largely suboptimal. Moreover, at sufficient language diversity, zero-shot cross-lingual transfer can match or exceed the effects of direct language inclusion in a low-diversity setting, although gains remain limited for typologically distant, low-resource languages.
ExpressEdit: Fast Editing of Stylized Facial Expressions with Diffusion Models in Photoshop
Apr 03, 2026Facial expressions of characters are a vital component of visual storytelling. While current AI image editing models hold promise for assisting artists in the task of stylized expression editing, these models introduce global noise and pixel drift into the edited image, preventing the integration of these models into professional image editing software and workflows. To bridge this gap, we introduce ExpressEdit, a fully open-source Photoshop plugin that is free from common artifacts of proprietary image editing models and robustly synergizes with native Photoshop operations such as Liquify. ExpressEdit seamlessly edits an expression within 3 seconds on a single consumer-grade GPU, significantly faster than popular proprietary models. Moreover, to support the generation of diverse expressions according to different narrative needs, we compile a comprehensive expression database of 135 expression tags enriched with example stories and images designed for retrieval-augmented generation. We open source the code and dataset to facilitate future research and artistic exploration.
Banana100: Breaking NR-IQA Metrics by 100 Iterative Image Replications with Nano Banana Pro
Apr 03, 2026The multi-step, iterative image editing capabilities of multi-modal agentic systems have transformed digital content creation. Although latest image editing models faithfully follow instructions and generate high-quality images in single-turn edits, we identify a critical weakness in multi-turn editing, which is the iterative degradation of image quality. As images are repeatedly edited, minor artifacts accumulate, rapidly leading to a severe accumulation of visible noise and a failure to follow simple editing instructions. To systematically study these failures, we introduce Banana100, a comprehensive dataset of 28,000 degraded images generated through 100 iterative editing steps, including diverse textures and image content. Alarmingly, image quality evaluators fail to detect the degradation. Among 21 popular no-reference image quality assessment (NR-IQA) metrics, none of them consistently assign lower scores to heavily degraded images than to clean ones. The dual failures of generators and evaluators may threaten the stability of future model training and the safety of deployed agentic systems, if the low-quality synthetic data generated by multi-turn edits escape quality filters. We release the full code and data to facilitate the development of more robust models, helping to mitigate the fragility of multi-modal agentic systems.
BloClaw: An Omniscient, Multi-Modal Agentic Workspace for Next-Generation Scientific Discovery
Apr 01, 2026The integration of Large Language Models (LLMs) into life sciences has catalyzed the development of "AI Scientists." However, translating these theoretical capabilities into deployment-ready research environments exposes profound infrastructural vulnerabilities. Current frameworks are bottlenecked by fragile JSON-based tool-calling protocols, easily disrupted execution sandboxes that lose graphical outputs, and rigid conversational interfaces inherently ill-suited for high-dimensional scientific data.We introduce BloClaw, a unified, multi-modal operating system designed for Artificial Intelligence for Science (AI4S). BloClaw reconstructs the Agent-Computer Interaction (ACI) paradigm through three architectural innovations: (1) An XML-Regex Dual-Track Routing Protocol that statistically eliminates serialization failures (0.2% error rate vs. 17.6% in JSON); (2) A Runtime State Interception Sandbox that utilizes Python monkey-patching to autonomously capture and compile dynamic data visualizations (Plotly/Matplotlib), circumventing browser CORS policies; and (3) A State-Driven Dynamic Viewport UI that morphs seamlessly between a minimalist command deck and an interactive spatial rendering engine. We comprehensively benchmark BloClaw across cheminformatics (RDKit), de novo 3D protein folding via ESMFold, molecular docking, and autonomous Retrieval-Augmented Generation (RAG), establishing a highly robust, self-evolving paradigm for computational research assistants. The open-source repository is available at https://github.com/qinheming/BloClaw.
From Out-of-Distribution Detection to Hallucination Detection: A Geometric View
Feb 06, 2026Detecting hallucinations in large language models is a critical open problem with significant implications for safety and reliability. While existing hallucination detection methods achieve strong performance in question-answering tasks, they remain less effective on tasks requiring reasoning. In this work, we revisit hallucination detection through the lens of out-of-distribution (OOD) detection, a well-studied problem in areas like computer vision. Treating next-token prediction in language models as a classification task allows us to apply OOD techniques, provided appropriate modifications are made to account for the structural differences in large language models. We show that OOD-based approaches yield training-free, single-sample-based detectors, achieving strong accuracy in hallucination detection for reasoning tasks. Overall, our work suggests that reframing hallucination detection as OOD detection provides a promising and scalable pathway toward language model safety.
MetaboNet: The Largest Publicly Available Consolidated Dataset for Type 1 Diabetes Management
Jan 16, 2026Progress in Type 1 Diabetes (T1D) algorithm development is limited by the fragmentation and lack of standardization across existing T1D management datasets. Current datasets differ substantially in structure and are time-consuming to access and process, which impedes data integration and reduces the comparability and generalizability of algorithmic developments. This work aims to establish a unified and accessible data resource for T1D algorithm development. Multiple publicly available T1D datasets were consolidated into a unified resource, termed the MetaboNet dataset. Inclusion required the availability of both continuous glucose monitoring (CGM) data and corresponding insulin pump dosing records. Additionally, auxiliary information such as reported carbohydrate intake and physical activity was retained when present. The MetaboNet dataset comprises 3135 subjects and 1228 patient-years of overlapping CGM and insulin data, making it substantially larger than existing standalone benchmark datasets. The resource is distributed as a fully public subset available for immediate download at https://metabo-net.org/ , and with a Data Use Agreement (DUA)-restricted subset accessible through their respective application processes. For the datasets in the latter subset, processing pipelines are provided to automatically convert the data into the standardized MetaboNet format. A consolidated public dataset for T1D research is presented, and the access pathways for both its unrestricted and DUA-governed components are described. The resulting dataset covers a broad range of glycemic profiles and demographics and thus can yield more generalizable algorithmic performance than individual datasets.
Zero-Training Task-Specific Model Synthesis for Few-Shot Medical Image Classification
Nov 18, 2025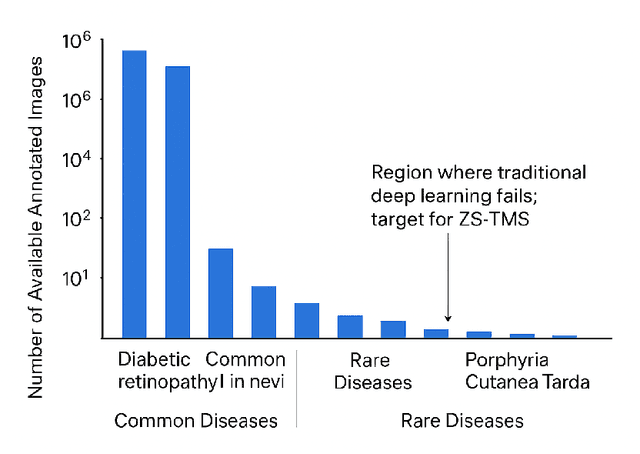



Deep learning models have achieved remarkable success in medical image analysis but are fundamentally constrained by the requirement for large-scale, meticulously annotated datasets. This dependency on "big data" is a critical bottleneck in the medical domain, where patient data is inherently difficult to acquire and expert annotation is expensive, particularly for rare diseases where samples are scarce by definition. To overcome this fundamental challenge, we propose a novel paradigm: Zero-Training Task-Specific Model Synthesis (ZS-TMS). Instead of adapting a pre-existing model or training a new one, our approach leverages a large-scale, pre-trained generative engine to directly synthesize the entire set of parameters for a task-specific classifier. Our framework, the Semantic-Guided Parameter Synthesizer (SGPS), takes as input minimal, multi-modal task information as little as a single example image (1-shot) and a corresponding clinical text description to directly synthesize the entire set of parameters for a task-specific classifier. The generative engine interprets these inputs to generate the weights for a lightweight, efficient classifier (e.g., an EfficientNet-V2), which can be deployed for inference immediately without any task-specific training or fine-tuning. We conduct extensive evaluations on challenging few-shot classification benchmarks derived from the ISIC 2018 skin lesion dataset and a custom rare disease dataset. Our results demonstrate that SGPS establishes a new state-of-the-art, significantly outperforming advanced few-shot and zero-shot learning methods, especially in the ultra-low data regimes of 1-shot and 5-shot classification. This work paves the way for the rapid development and deployment of AI-powered diagnostic tools, particularly for the long tail of rare diseases where data is critically limited.
Retrieval-Augmented Code Generation: A Survey with Focus on Repository-Level Approaches
Oct 06, 2025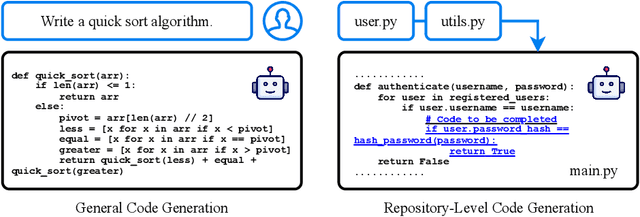

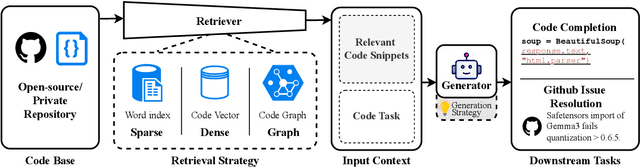
Recent advancements in large language models (LLMs) have substantially improved automated code generation. While function-level and file-level generation have achieved promising results, real-world software development typically requires reasoning across entire repositories. This gives rise to the challenging task of Repository-Level Code Generation (RLCG), where models must capture long-range dependencies, ensure global semantic consistency, and generate coherent code spanning multiple files or modules. To address these challenges, Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm that integrates external retrieval mechanisms with LLMs, enhancing context-awareness and scalability. In this survey, we provide a comprehensive review of research on Retrieval-Augmented Code Generation (RACG), with an emphasis on repository-level approaches. We categorize existing work along several dimensions, including generation strategies, retrieval modalities, model architectures, training paradigms, and evaluation protocols. Furthermore, we summarize widely used datasets and benchmarks, analyze current limitations, and outline key challenges and opportunities for future research. Our goal is to establish a unified analytical framework for understanding this rapidly evolving field and to inspire continued progress in AI-powered software engineering.
DIY-MKG: An LLM-Based Polyglot Language Learning System
Jul 02, 2025Existing language learning tools, even those powered by Large Language Models (LLMs), often lack support for polyglot learners to build linguistic connections across vocabularies in multiple languages, provide limited customization for individual learning paces or needs, and suffer from detrimental cognitive offloading. To address these limitations, we design Do-It-Yourself Multilingual Knowledge Graph (DIY-MKG), an open-source system that supports polyglot language learning. DIY-MKG allows the user to build personalized vocabulary knowledge graphs, which are constructed by selective expansion with related words suggested by an LLM. The system further enhances learning through rich annotation capabilities and an adaptive review module that leverages LLMs for dynamic, personalized quiz generation. In addition, DIY-MKG allows users to flag incorrect quiz questions, simultaneously increasing user engagement and providing a feedback loop for prompt refinement. Our evaluation of LLM-based components in DIY-MKG shows that vocabulary expansion is reliable and fair across multiple languages, and that the generated quizzes are highly accurate, validating the robustness of DIY-MKG.
Bridging Distribution Shift and AI Safety: Conceptual and Methodological Synergies
May 28, 2025This paper bridges distribution shift and AI safety through a comprehensive analysis of their conceptual and methodological synergies. While prior discussions often focus on narrow cases or informal analogies, we establish two types connections between specific causes of distribution shift and fine-grained AI safety issues: (1) methods addressing a specific shift type can help achieve corresponding safety goals, or (2) certain shifts and safety issues can be formally reduced to each other, enabling mutual adaptation of their methods. Our findings provide a unified perspective that encourages fundamental integration between distribution shift and AI safety research.