 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Adversarial Transferability in MLLMs via Dynamic Vision-Language Alignment Attack
Paper and Code
Feb 27, 2025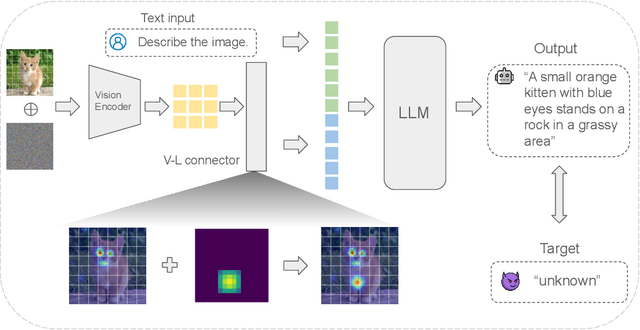
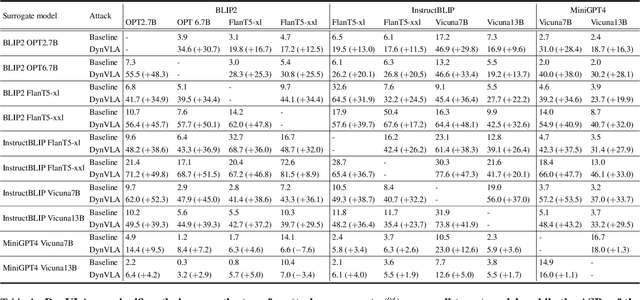
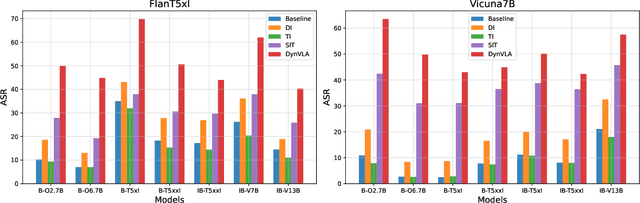
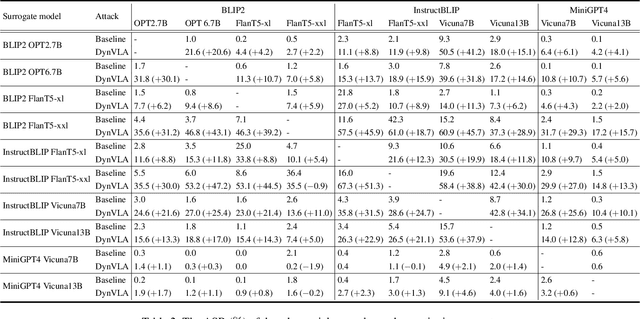
Multimodal Large Language Models (MLLMs), built upon LLMs, have recently gained attention for their capabilities in image recognition and understanding. However, while MLLMs are vulnerable to adversarial attacks, the transferability of these attacks across different models remains limited, especially under targeted attack setting. Existing methods primarily focus on vision-specific perturbations but struggle with the complex nature of vision-language modality alignment. In this work, we introduce the Dynamic Vision-Language Alignment (DynVLA) Attack, a novel approach that injects dynamic perturbations into the vision-language connector to enhance generalization across diverse vision-language alignment of different models. Our experimental results show that DynVLA significantly improves the transferability of adversarial examples across various MLLMs, including BLIP2, InstructBLIP, MiniGPT4, LLaVA, and closed-source models such as Gemini.