 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Adversarial Transferability in MLLMs via Dynamic Vision-Language Alignment Attack
Feb 27, 2025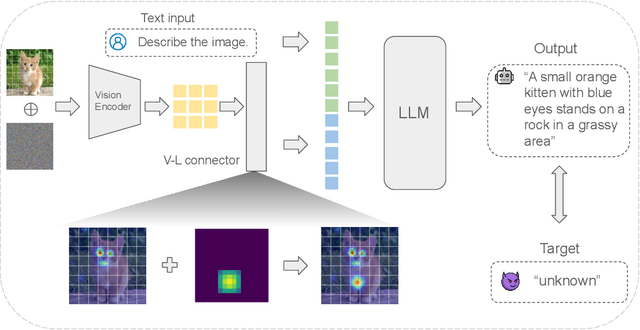
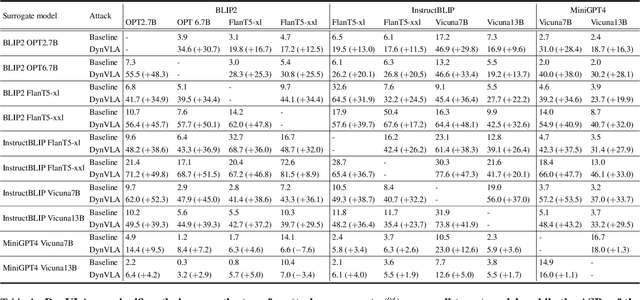
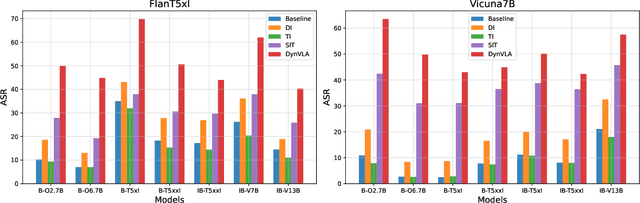
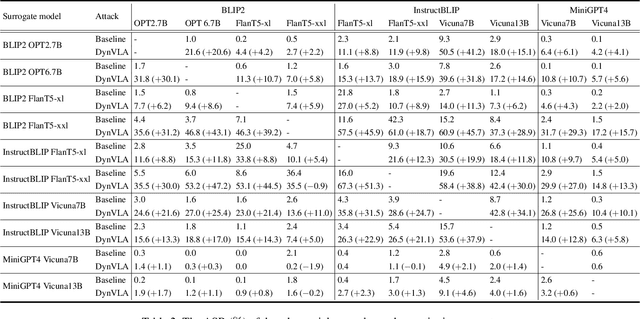
Multimodal Large Language Models (MLLMs), built upon LLMs, have recently gained attention for their capabilities in image recognition and understanding. However, while MLLMs are vulnerable to adversarial attacks, the transferability of these attacks across different models remains limited, especially under targeted attack setting. Existing methods primarily focus on vision-specific perturbations but struggle with the complex nature of vision-language modality alignment. In this work, we introduce the Dynamic Vision-Language Alignment (DynVLA) Attack, a novel approach that injects dynamic perturbations into the vision-language connector to enhance generalization across diverse vision-language alignment of different models. Our experimental results show that DynVLA significantly improves the transferability of adversarial examples across various MLLMs, including BLIP2, InstructBLIP, MiniGPT4, LLaVA, and closed-source models such as Gemini.
Initialization Matters for Adversarial Transfer Learning
Dec 10, 2023
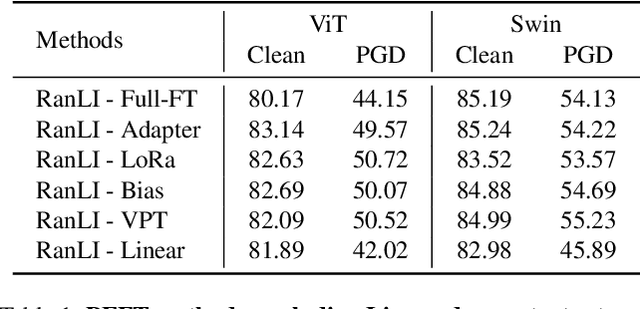

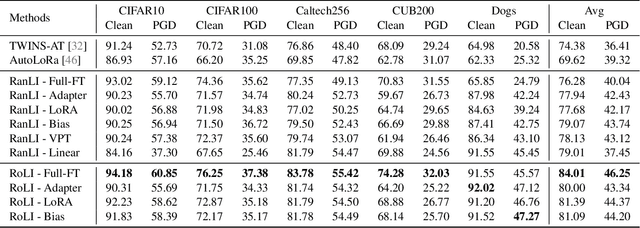
With the prevalence of the Pretraining-Finetuning paradigm in transfer learning, the robustness of downstream tasks has become a critical concern. In this work, we delve into adversarial robustness in transfer learning and reveal the critical role of initialization, including both the pretrained model and the linear head. First, we discover the necessity of an adversarially robust pretrained model. Specifically, we reveal that with a standard pretrained model, Parameter-Efficient Finetuning~(PEFT) methods either fail to be adversarially robust or continue to exhibit significantly degraded adversarial robustness on downstream tasks, even with adversarial training during finetuning. Leveraging a robust pretrained model, surprisingly, we observe that a simple linear probing can outperform full finetuning and other PEFT methods with random initialization on certain datasets. We further identify that linear probing excels in preserving robustness from the robust pretraining. Based on this, we propose Robust Linear Initialization~(RoLI) for adversarial finetuning, which initializes the linear head with the weights obtained by adversarial linear probing to maximally inherit the robustness from pretraining. Across five different image classification datasets, we demonstrate the effectiveness of RoLI and achieve new state-of-the-art results.