 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantics-Preserving Evasion of LLM Vulnerability Detectors
Jan 30, 2026LLM-based vulnerability detectors are increasingly deployed in security-critical code review, yet their resilience to evasion under behavior-preserving edits remains poorly understood. We evaluate detection-time integrity under a semantics-preserving threat model by instantiating diverse behavior-preserving code transformations on a unified C/C++ benchmark (N=5000), and introduce a metric of joint robustness across different attack methods/carriers. Across models, we observe a systemic failure of semantic invariant adversarial transformations: even state-of-the-art vulnerability detectors perform well on clean inputs while predictions flip under behavior-equivalent edits. Universal adversarial strings optimized on a single surrogate model remain effective when transferred to black-box APIs, and gradient access can further amplify evasion success. These results show that even high-performing detectors are vulnerable to low-cost, semantics-preserving evasion. Our carrier-based metrics provide practical diagnostics for evaluating LLM-based code detectors.
T-FIX: Text-Based Explanations with Features Interpretable to eXperts
Nov 06, 2025As LLMs are deployed in knowledge-intensive settings (e.g., surgery, astronomy, therapy), users expect not just answers, but also meaningful explanations for those answers. In these settings, users are often domain experts (e.g., doctors, astrophysicists, psychologists) who require explanations that reflect expert-level reasoning. However, current evaluation schemes primarily emphasize plausibility or internal faithfulness of the explanation, which fail to capture whether the content of the explanation truly aligns with expert intuition. We formalize expert alignment as a criterion for evaluating explanations with T-FIX, a benchmark spanning seven knowledge-intensive domains. In collaboration with domain experts, we develop novel metrics to measure the alignment of LLM explanations with expert judgment.
Once Upon an Input: Reasoning via Per-Instance Program Synthesis
Oct 26, 2025Large language models (LLMs) excel at zero-shot inference but continue to struggle with complex, multi-step reasoning. Recent methods that augment LLMs with intermediate reasoning steps such as Chain of Thought (CoT) and Program of Thought (PoT) improve performance but often produce undesirable solutions, especially in algorithmic domains. We introduce Per-Instance Program Synthesis (PIPS), a method that generates and refines programs at the instance-level using structural feedback without relying on task-specific guidance or explicit test cases. To further improve performance, PIPS incorporates a confidence metric that dynamically chooses between direct inference and program synthesis on a per-instance basis. Experiments across three frontier LLMs and 30 benchmarks including all tasks of Big Bench Extra Hard (BBEH), visual question answering tasks, relational reasoning tasks, and mathematical reasoning tasks show that PIPS improves the absolute harmonic mean accuracy by up to 8.6% and 9.4% compared to PoT and CoT respectively, and reduces undesirable program generations by 65.1% on the algorithmic tasks compared to PoT with Gemini-2.0-Flash.
Stable Prediction of Adverse Events in Medical Time-Series Data
Oct 16, 2025
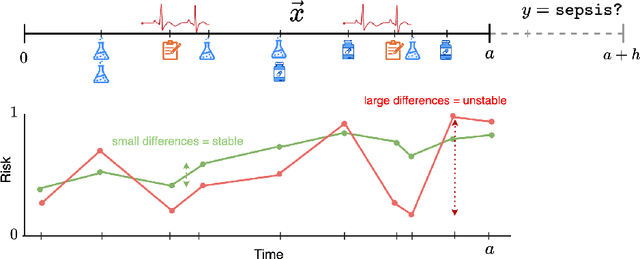
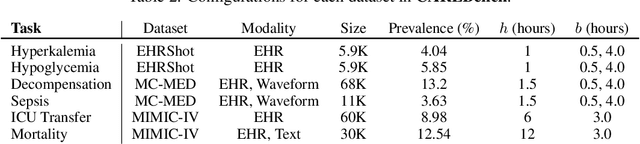
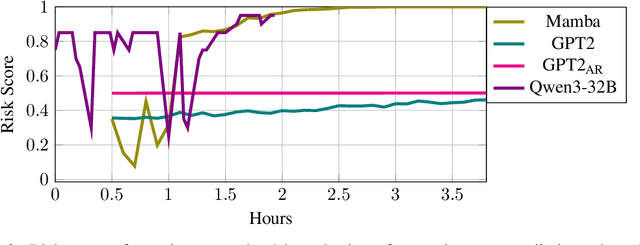
Early event prediction (EEP) systems continuously estimate a patient's imminent risk to support clinical decision-making. For bedside trust, risk trajectories must be accurate and temporally stable, shifting only with new, relevant evidence. However, current benchmarks (a) ignore stability of risk scores and (b) evaluate mainly on tabular inputs, leaving trajectory behavior untested. To address this gap, we introduce CAREBench, an EEP benchmark that evaluates deployability using multi-modal inputs-tabular EHR, ECG waveforms, and clinical text-and assesses temporal stability alongside predictive accuracy. We propose a stability metric that quantifies short-term variability in per-patient risk and penalizes abrupt oscillations based on local-Lipschitz constants. CAREBench spans six prediction tasks such as sepsis onset and compares classical learners, deep sequence models, and zero-shot LLMs. Across tasks, existing methods, especially LLMs, struggle to jointly optimize accuracy and stability, with notably poor recall at high-precision operating points. These results highlight the need for models that produce evidence-aligned, stable trajectories to earn clinician trust in continuous monitoring settings. (Code: https://github.com/SeewonChoi/CAREBench.)
Instruction Following by Boosting Attention of Large Language Models
Jun 16, 2025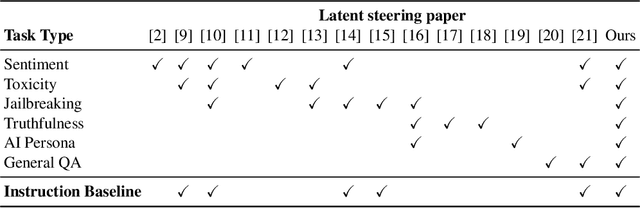
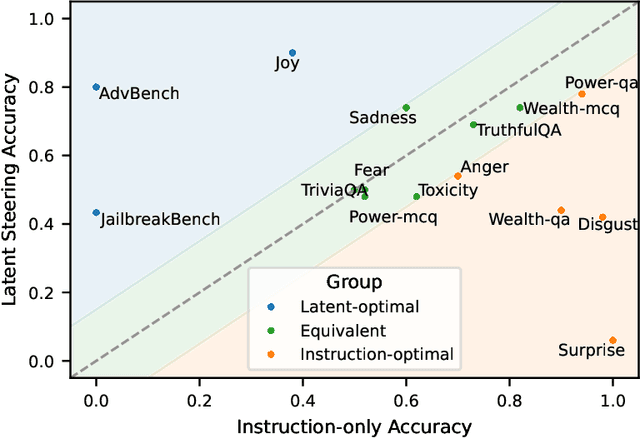
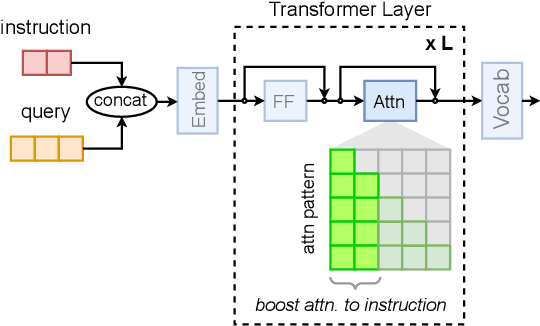

Controlling the generation of large language models (LLMs) remains a central challenge to ensure their safe and reliable deployment. While prompt engineering and finetuning are common approaches, recent work has explored latent steering, a lightweight technique that alters LLM internal activations to guide generation. However, subsequent studies revealed latent steering's effectiveness to be limited, often underperforming simple instruction prompting. To address this limitation, we first establish a benchmark across diverse behaviors for standardized evaluation of steering techniques. Building on insights from this benchmark, we introduce Instruction Attention Boosting (InstABoost), a latent steering method that boosts the strength of instruction prompting by altering the model's attention during generation. InstABoost combines the strengths of existing approaches and is theoretically supported by prior work that suggests that in-context rule following in transformer-based models can be controlled by manipulating attention on instructions. Empirically, InstABoost demonstrates superior control success compared to both traditional prompting and latent steering.
Benchmarking Misuse Mitigation Against Covert Adversaries
Jun 06, 2025Existing language model safety evaluations focus on overt attacks and low-stakes tasks. Realistic attackers can subvert current safeguards by requesting help on small, benign-seeming tasks across many independent queries. Because individual queries do not appear harmful, the attack is hard to {detect}. However, when combined, these fragments uplift misuse by helping the attacker complete hard and dangerous tasks. Toward identifying defenses against such strategies, we develop Benchmarks for Stateful Defenses (BSD), a data generation pipeline that automates evaluations of covert attacks and corresponding defenses. Using this pipeline, we curate two new datasets that are consistently refused by frontier models and are too difficult for weaker open-weight models. Our evaluations indicate that decomposition attacks are effective misuse enablers, and highlight stateful defenses as a countermeasure.
The Road to Generalizable Neuro-Symbolic Learning Should be Paved with Foundation Models
May 30, 2025Neuro-symbolic learning was proposed to address challenges with training neural networks for complex reasoning tasks with the added benefits of interpretability, reliability, and efficiency. Neuro-symbolic learning methods traditionally train neural models in conjunction with symbolic programs, but they face significant challenges that limit them to simplistic problems. On the other hand, purely-neural foundation models now reach state-of-the-art performance through prompting rather than training, but they are often unreliable and lack interpretability. Supplementing foundation models with symbolic programs, which we call neuro-symbolic prompting, provides a way to use these models for complex reasoning tasks. Doing so raises the question: What role does specialized model training as part of neuro-symbolic learning have in the age of foundation models? To explore this question, we highlight three pitfalls of traditional neuro-symbolic learning with respect to the compute, data, and programs leading to generalization problems. This position paper argues that foundation models enable generalizable neuro-symbolic solutions, offering a path towards achieving the original goals of neuro-symbolic learning without the downsides of training from scratch.
Probabilistic Stability Guarantees for Feature Attributions
Apr 18, 2025Stability guarantees are an emerging tool for evaluating feature attributions, but existing certification methods rely on smoothed classifiers and often yield conservative guarantees. To address these limitations, we introduce soft stability and propose a simple, model-agnostic, and sample-efficient stability certification algorithm (SCA) that provides non-trivial and interpretable guarantees for any attribution. Moreover, we show that mild smoothing enables a graceful tradeoff between accuracy and stability, in contrast to prior certification methods that require a more aggressive compromise. Using Boolean function analysis, we give a novel characterization of stability under smoothing. We evaluate SCA on vision and language tasks, and demonstrate the effectiveness of soft stability in measuring the robustness of explanation methods.
CTSketch: Compositional Tensor Sketching for Scalable Neurosymbolic Learning
Mar 31, 2025Many computational tasks benefit from being formulated as the composition of neural networks followed by a discrete symbolic program. The goal of neurosymbolic learning is to train the neural networks using only end-to-end input-output labels of the composite. We introduce CTSketch, a novel, scalable neurosymbolic learning algorithm. CTSketch uses two techniques to improve the scalability of neurosymbolic inference: decompose the symbolic program into sub-programs and summarize each sub-program with a sketched tensor. This strategy allows us to approximate the output distribution of the program with simple tensor operations over the input distributions and summaries. We provide theoretical insight into the maximum error of the approximation. Furthermore, we evaluate CTSketch on many benchmarks from the neurosymbolic literature, including some designed for evaluating scalability. Our results show that CTSketch pushes neurosymbolic learning to new scales that have previously been unattainable by obtaining high accuracy on tasks involving over one thousand inputs.
NSF-SciFy: Mining the NSF Awards Database for Scientific Claims
Mar 11, 2025



We present NSF-SciFy, a large-scale dataset for scientific claim extraction derived from the National Science Foundation (NSF) awards database, comprising over 400K grant abstracts spanning five decades. While previous datasets relied on published literature, we leverage grant abstracts which offer a unique advantage: they capture claims at an earlier stage in the research lifecycle before publication takes effect. We also introduce a new task to distinguish between existing scientific claims and aspirational research intentions in proposals.Using zero-shot prompting with frontier large language models, we jointly extract 114K scientific claims and 145K investigation proposals from 16K grant abstracts in the materials science domain to create a focused subset called NSF-SciFy-MatSci. We use this dataset to evaluate 3 three key tasks: (1) technical to non-technical abstract generation, where models achieve high BERTScore (0.85+ F1); (2) scientific claim extraction, where fine-tuned models outperform base models by 100% relative improvement; and (3) investigation proposal extraction, showing 90%+ improvement with fine-tuning. We introduce novel LLM-based evaluation metrics for robust assessment of claim/proposal extraction quality. As the largest scientific claim dataset to date -- with an estimated 2.8 million claims across all STEM disciplines funded by the NSF -- NSF-SciFy enables new opportunities for claim verification and meta-scientific research. We publicly release all datasets, trained models, and evaluation code to facilitate further research.