 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR-Pro: Counterfactual Explanations for Anomaly Repair with Formal Properties
Oct 31, 2024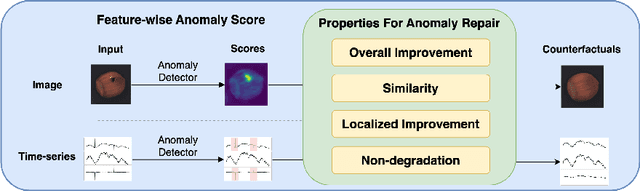
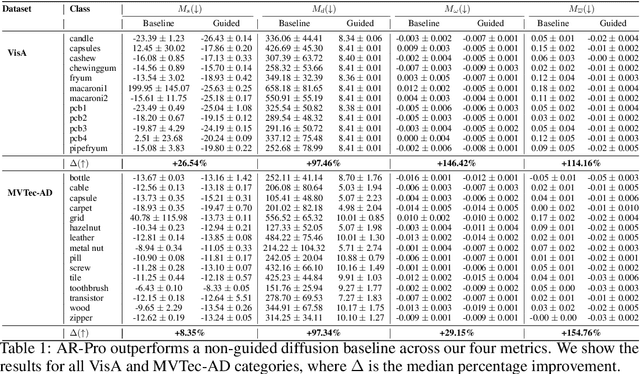
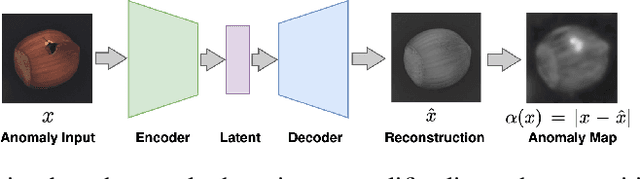
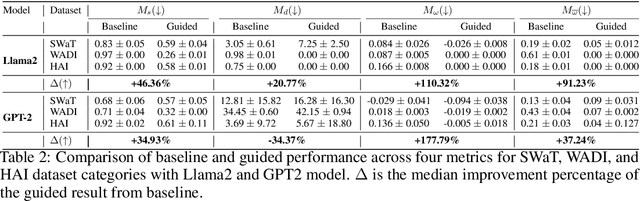
Anomaly detection is widely used for identifying critical errors and suspicious behaviors, but current methods lack interpretability. We leverage common properties of existing methods and recent advances in generative models to introduce counterfactual explanations for anomaly detection. Given an input, we generate its counterfactual as a diffusion-based repair that shows what a non-anomalous version should have looked like. A key advantage of this approach is that it enables a domain-independent formal specification of explainability desiderata, offering a unified framework for generating and evaluating explanations. We demonstrate the effectiveness of our anomaly explainability framework, AR-Pro, on vision (MVTec, VisA) and time-series (SWaT, WADI, HAI) anomaly datasets. The code used for the experiments is accessible at: https://github.com/xjiae/arpro.
Using Semantic Information for Defining and Detecting OOD Inputs
Feb 21, 2023



As machine learning models continue to achieve impressive performance across different tasks, the importance of effective anomaly detection for such models has increased as well. It is common knowledge that even well-trained models lose their ability to function effectively on out-of-distribution inputs. Thus, out-of-distribution (OOD) detection has received some attention recently. In the vast majority of cases, it uses the distribution estimated by the training dataset for OOD detection. We demonstrate that the current detectors inherit the biases in the training dataset, unfortunately. This is a serious impediment, and can potentially restrict the utility of the trained model. This can render the current OOD detectors impermeable to inputs lying outside the training distribution but with the same semantic information (e.g. training class labels). To remedy this situation, we begin by defining what should ideally be treated as an OOD, by connecting inputs with their semantic information content. We perform OOD detection on semantic information extracted from the training data of MNIST and COCO datasets and show that it not only reduces false alarms but also significantly improves the detection of OOD inputs with spurious features from the training data.
PAC-Wrap: Semi-Supervised PAC Anomaly Detection
May 22, 2022
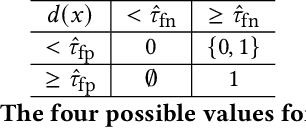


Anomaly detection is essential for preventing hazardous outcomes for safety-critical applications like autonomous driving. Given their safety-criticality, these applications benefit from provable bounds on various errors in anomaly detection. To achieve this goal in the semi-supervised setting, we propose to provide Probably Approximately Correct (PAC) guarantees on the false negative and false positive detection rates for anomaly detection algorithms. Our method (PAC-Wrap) can wrap around virtually any existing semi-supervised and unsupervised anomaly detection method, endowing it with rigorous guarantees. Our experiments with various anomaly detectors and datasets indicate that PAC-Wrap is broadly effective.
Towards PAC Multi-Object Detection and Tracking
Apr 15, 2022
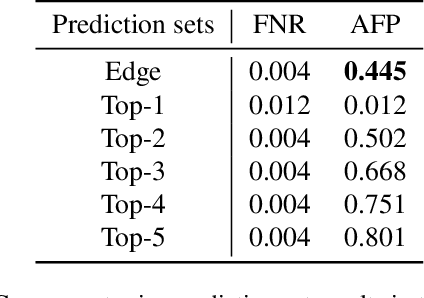

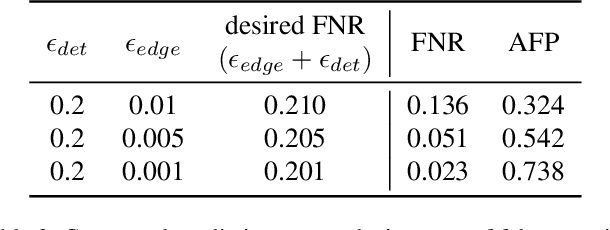
Accurately detecting and tracking multi-objects is important for safety-critical applications such as autonomous navigation. However, it remains challenging to provide guarantees on the performance of state-of-the-art techniques based on deep learning. We consider a strategy known as conformal prediction, which predicts sets of labels instead of a single label; in the classification and regression settings, these algorithms can guarantee that the true label lies within the prediction set with high probability. Building on these ideas, we propose multi-object detection and tracking algorithms that come with probably approximately correct (PAC) guarantees. They do so by constructing both a prediction set around each object detection as well as around the set of edge transitions; given an object, the detection prediction set contains its true bounding box with high probability, and the edge prediction set contains its true transition across frames with high probability. We empirically demonstrate that our method can detect and track objects with PAC guarantees on the COCO and MOT-17 datasets.