 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Monitoring for Learning-Enabled Cyber-Physical Systems in Out-of-Distribution Scenarios
Apr 18, 2025The safety of learning-enabled cyber-physical systems is compromised by the well-known vulnerabilities of deep neural networks to out-of-distribution (OOD) inputs. Existing literature has sought to monitor the safety of such systems by detecting OOD data. However, such approaches have limited utility, as the presence of an OOD input does not necessarily imply the violation of a desired safety property. We instead propose to directly monitor safety in a manner that is itself robust to OOD data. To this end, we predict violations of signal temporal logic safety specifications based on predicted future trajectories. Our safety monitor additionally uses a novel combination of adaptive conformal prediction and incremental learning. The former obtains probabilistic prediction guarantees even on OOD data, and the latter prevents overly conservative predictions. We evaluate the efficacy of the proposed approach in two case studies on safety monitoring: 1) predicting collisions of an F1Tenth car with static obstacles, and 2) predicting collisions of a race car with multiple dynamic obstacles. We find that adaptive conformal prediction obtains theoretical guarantees where other uncertainty quantification methods fail to do so. Additionally, combining adaptive conformal prediction and incremental learning for safety monitoring achieves high recall and timeliness while reducing loss in precision. We achieve these results even in OOD settings and outperform alternative methods.
REGENT: A Retrieval-Augmented Generalist Agent That Can Act In-Context in New Environments
Dec 06, 2024Building generalist agents that can rapidly adapt to new environments is a key challenge for deploying AI in the digital and real worlds. Is scaling current agent architectures the most effective way to build generalist agents? We propose a novel approach to pre-train relatively small policies on relatively small datasets and adapt them to unseen environments via in-context learning, without any finetuning. Our key idea is that retrieval offers a powerful bias for fast adaptation. Indeed, we demonstrate that even a simple retrieval-based 1-nearest neighbor agent offers a surprisingly strong baseline for today's state-of-the-art generalist agents. From this starting point, we construct a semi-parametric agent, REGENT, that trains a transformer-based policy on sequences of queries and retrieved neighbors. REGENT can generalize to unseen robotics and game-playing environments via retrieval augmentation and in-context learning, achieving this with up to 3x fewer parameters and up to an order-of-magnitude fewer pre-training datapoints, significantly outperforming today's state-of-the-art generalist agents. Website: https://kaustubhsridhar.github.io/regent-research
Automating Weak Label Generation for Data Programming with Clinicians in the Loop
Jul 10, 2024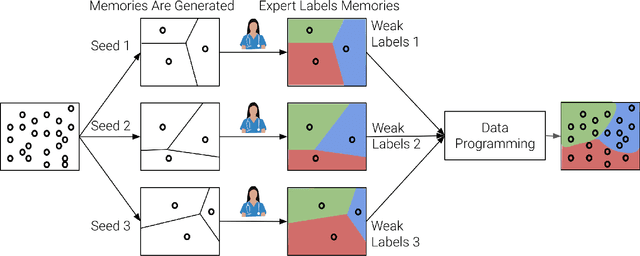
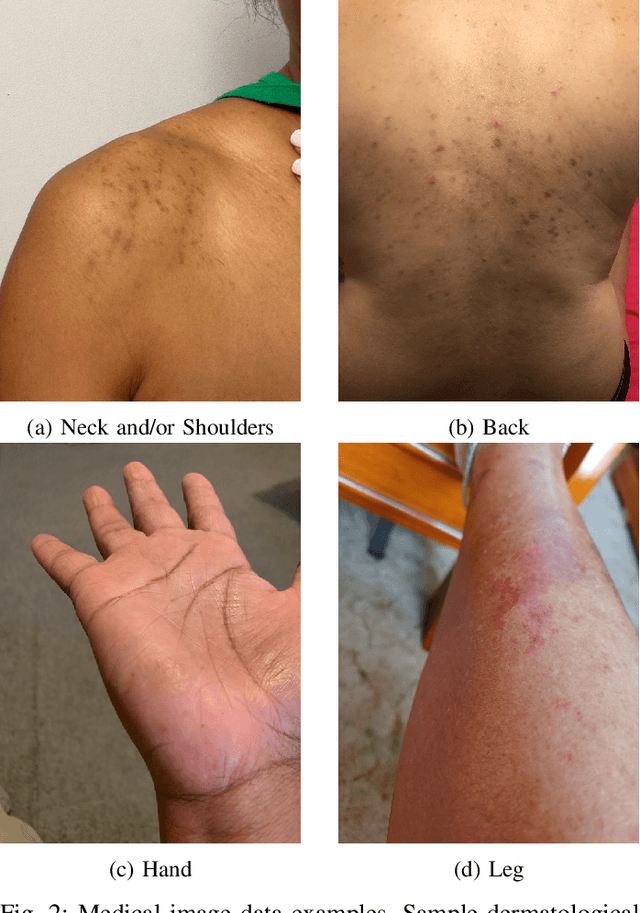
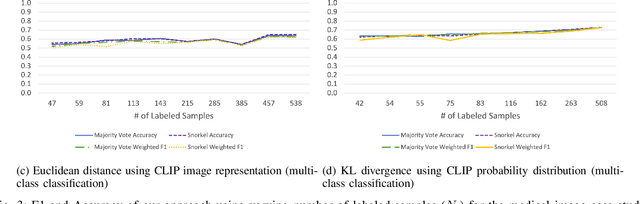
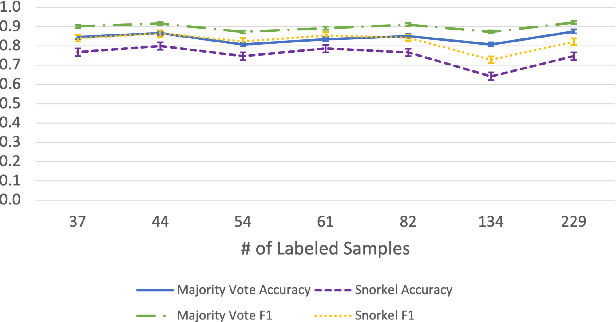
Large Deep Neural Networks (DNNs) are often data hungry and need high-quality labeled data in copious amounts for learning to converge. This is a challenge in the field of medicine since high quality labeled data is often scarce. Data programming has been the ray of hope in this regard, since it allows us to label unlabeled data using multiple weak labeling functions. Such functions are often supplied by a domain expert. Data-programming can combine multiple weak labeling functions and suggest labels better than simple majority voting over the different functions. However, it is not straightforward to express such weak labeling functions, especially in high-dimensional settings such as images and time-series data. What we propose in this paper is a way to bypass this issue, using distance functions. In high-dimensional spaces, it is easier to find meaningful distance metrics which can generalize across different labeling tasks. We propose an algorithm that queries an expert for labels of a few representative samples of the dataset. These samples are carefully chosen by the algorithm to capture the distribution of the dataset. The labels assigned by the expert on the representative subset induce a labeling on the full dataset, thereby generating weak labels to be used in the data programming pipeline. In our medical time series case study, labeling a subset of 50 to 130 out of 3,265 samples showed 17-28% improvement in accuracy and 13-28% improvement in F1 over the baseline using clinician-defined labeling functions. In our medical image case study, labeling a subset of about 50 to 120 images from 6,293 unlabeled medical images using our approach showed significant improvement over the baseline method, Snuba, with an increase of approximately 5-15% in accuracy and 12-19% in F1 score.
Bridging Dimensions: Confident Reachability for High-Dimensional Controllers
Nov 08, 2023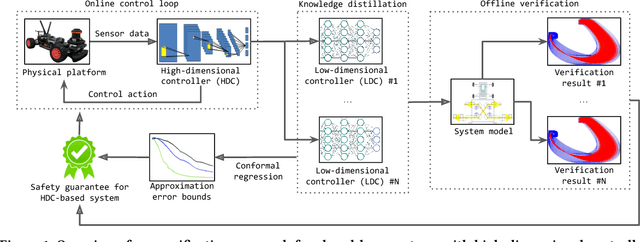
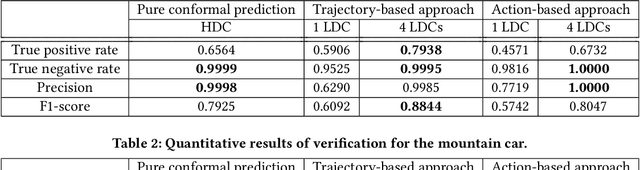
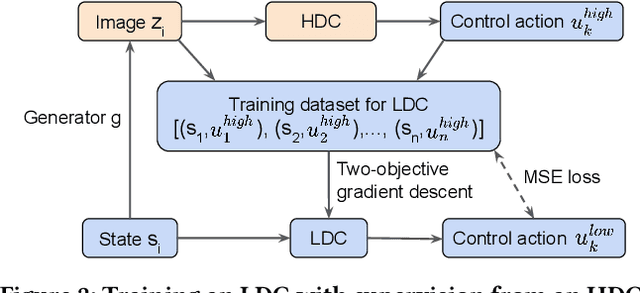
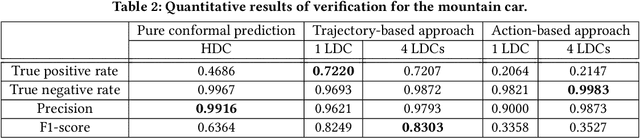
Autonomous systems are increasingly implemented using end-end-end trained controllers. Such controllers make decisions that are executed on the real system with images as one of the primary sensing modalities. Deep neural networks form a fundamental building block of such controllers. Unfortunately, the existing neural-network verification tools do not scale to inputs with thousands of dimensions. Especially when the individual inputs (such as pixels) are devoid of clear physical meaning. This paper takes a step towards connecting exhaustive closed-loop verification with high-dimensional controllers. Our key insight is that the behavior of a high-dimensional controller can be approximated with several low-dimensional controllers in different regions of the state space. To balance approximation and verifiability, we leverage the latest verification-aware knowledge distillation. Then, if low-dimensional reachability results are inflated with statistical approximation errors, they yield a high-confidence reachability guarantee for the high-dimensional controller. We investigate two inflation techniques -- based on trajectories and actions -- both of which show convincing performance in two OpenAI gym benchmarks.
Memory-Consistent Neural Networks for Imitation Learning
Oct 09, 2023Imitation learning considerably simplifies policy synthesis compared to alternative approaches by exploiting access to expert demonstrations. For such imitation policies, errors away from the training samples are particularly critical. Even rare slip-ups in the policy action outputs can compound quickly over time, since they lead to unfamiliar future states where the policy is still more likely to err, eventually causing task failures. We revisit simple supervised ``behavior cloning'' for conveniently training the policy from nothing more than pre-recorded demonstrations, but carefully design the model class to counter the compounding error phenomenon. Our ``memory-consistent neural network'' (MCNN) outputs are hard-constrained to stay within clearly specified permissible regions anchored to prototypical ``memory'' training samples. We provide a guaranteed upper bound for the sub-optimality gap induced by MCNN policies. Using MCNNs on 9 imitation learning tasks, with MLP, Transformer, and Diffusion backbones, spanning dexterous robotic manipulation and driving, proprioceptive inputs and visual inputs, and varying sizes and types of demonstration data, we find large and consistent gains in performance, validating that MCNNs are better-suited than vanilla deep neural networks for imitation learning applications. Website: https://sites.google.com/view/mcnn-imitation
Distributionally Robust Statistical Verification with Imprecise Neural Networks
Aug 30, 2023



A particularly challenging problem in AI safety is providing guarantees on the behavior of high-dimensional autonomous systems. Verification approaches centered around reachability analysis fail to scale, and purely statistical approaches are constrained by the distributional assumptions about the sampling process. Instead, we pose a distributionally robust version of the statistical verification problem for black-box systems, where our performance guarantees hold over a large family of distributions. This paper proposes a novel approach based on a combination of active learning, uncertainty quantification, and neural network verification. A central piece of our approach is an ensemble technique called Imprecise Neural Networks, which provides the uncertainty to guide active learning. The active learning uses an exhaustive neural-network verification tool Sherlock to collect samples. An evaluation on multiple physical simulators in the openAI gym Mujoco environments with reinforcement-learned controllers demonstrates that our approach can provide useful and scalable guarantees for high-dimensional systems.
Take Me Home: Reversing Distribution Shifts using Reinforcement Learning
Feb 24, 2023



Deep neural networks have repeatedly been shown to be non-robust to the uncertainties of the real world. Even subtle adversarial attacks and naturally occurring distribution shifts wreak havoc on systems relying on deep neural networks. In response to this, current state-of-the-art techniques use data-augmentation to enrich the training distribution of the model and consequently improve robustness to natural distribution shifts. We propose an alternative approach that allows the system to recover from distribution shifts online. Specifically, our method applies a sequence of semantic-preserving transformations to bring the shifted data closer in distribution to the training set, as measured by the Wasserstein distance. We formulate the problem of sequence selection as an MDP, which we solve using reinforcement learning. To aid in our estimates of Wasserstein distance, we employ dimensionality reduction through orthonormal projection. We provide both theoretical and empirical evidence that orthonormal projection preserves characteristics of the data at the distributional level. Finally, we apply our distribution shift recovery approach to the ImageNet-C benchmark for distribution shifts, targeting shifts due to additive noise and image histogram modifications. We demonstrate an improvement in average accuracy up to 14.21% across a variety of state-of-the-art ImageNet classifiers.
Using Semantic Information for Defining and Detecting OOD Inputs
Feb 21, 2023



As machine learning models continue to achieve impressive performance across different tasks, the importance of effective anomaly detection for such models has increased as well. It is common knowledge that even well-trained models lose their ability to function effectively on out-of-distribution inputs. Thus, out-of-distribution (OOD) detection has received some attention recently. In the vast majority of cases, it uses the distribution estimated by the training dataset for OOD detection. We demonstrate that the current detectors inherit the biases in the training dataset, unfortunately. This is a serious impediment, and can potentially restrict the utility of the trained model. This can render the current OOD detectors impermeable to inputs lying outside the training distribution but with the same semantic information (e.g. training class labels). To remedy this situation, we begin by defining what should ideally be treated as an OOD, by connecting inputs with their semantic information content. We perform OOD detection on semantic information extracted from the training data of MNIST and COCO datasets and show that it not only reduces false alarms but also significantly improves the detection of OOD inputs with spurious features from the training data.
Imprecise Bayesian Neural Networks
Feb 19, 2023



Uncertainty quantification and robustness to distribution shifts are important goals in machine learning and artificial intelligence. Although Bayesian neural networks (BNNs) allow for uncertainty in the predictions to be assessed, different sources of uncertainty are indistinguishable. We present imprecise Bayesian neural networks (IBNNs); they generalize and overcome some of the drawbacks of standard BNNs. These latter are trained using a single prior and likelihood distributions, whereas IBNNs are trained using credal prior and likelihood sets. They allow to distinguish between aleatoric and epistemic uncertainties, and to quantify them. In addition, IBNNs are robust in the sense of Bayesian sensitivity analysis, and are more robust than BNNs to distribution shift. They can also be used to compute sets of outcomes that enjoy PAC-like properties. We apply IBNNs to two case studies. One, to model blood glucose and insulin dynamics for artificial pancreas control, and two, for motion prediction in autonomous driving scenarios. We show that IBNNs performs better when compared to an ensemble of BNNs benchmark.
Guaranteed Conformance of Neurosymbolic Models to Natural Constraints
Dec 09, 2022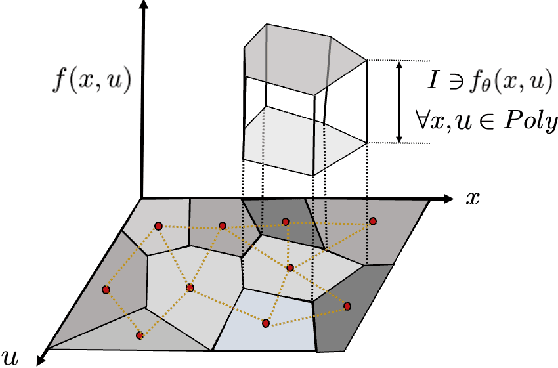
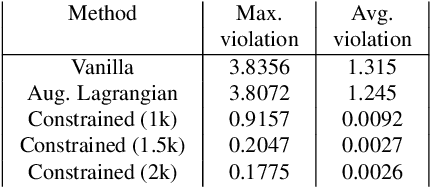
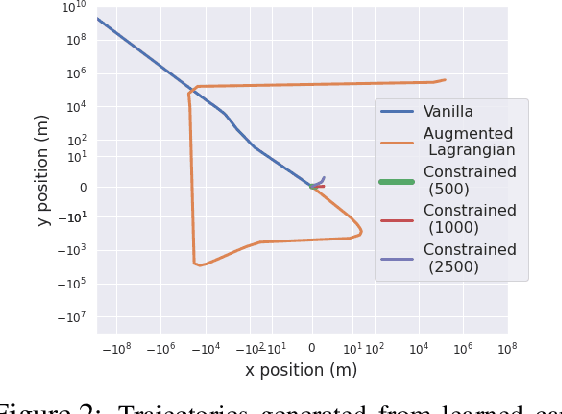
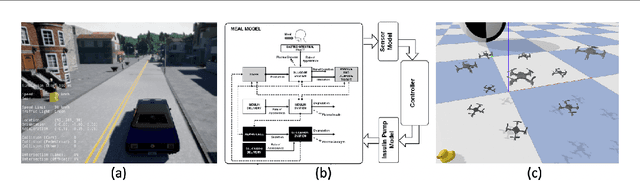
Deep neural networks have emerged as the workhorse for a large section of robotics and control applications, especially as models for dynamical systems. Such data-driven models are in turn used for designing and verifying autonomous systems. This is particularly useful in modeling medical systems where data can be leveraged to individualize treatment. In safety-critical applications, it is important that the data-driven model is conformant to established knowledge from the natural sciences. Such knowledge is often available or can often be distilled into a (possibly black-box) model $M$. For instance, the unicycle model for an F1 racing car. In this light, we consider the following problem - given a model $M$ and state transition dataset, we wish to best approximate the system model while being bounded distance away from $M$. We propose a method to guarantee this conformance. Our first step is to distill the dataset into few representative samples called memories, using the idea of a growing neural gas. Next, using these memories we partition the state space into disjoint subsets and compute bounds that should be respected by the neural network, when the input is drawn from a particular subset. This serves as a symbolic wrapper for guaranteed conformance. We argue theoretically that this only leads to bounded increase in approximation error; which can be controlled by increasing the number of memories. We experimentally show that on three case studies (Car Model, Drones, and Artificial Pancreas), our constrained neurosymbolic models conform to specified $M$ models (each encoding various constraints) with order-of-magnitude improvements compared to the augmented Lagrangian and vanilla training methods.