 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Weak Label Generation for Data Programming with Clinicians in the Loop
Jul 10, 2024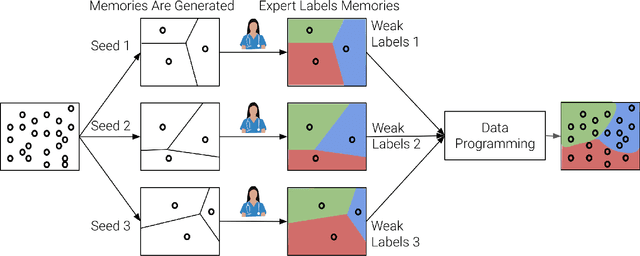
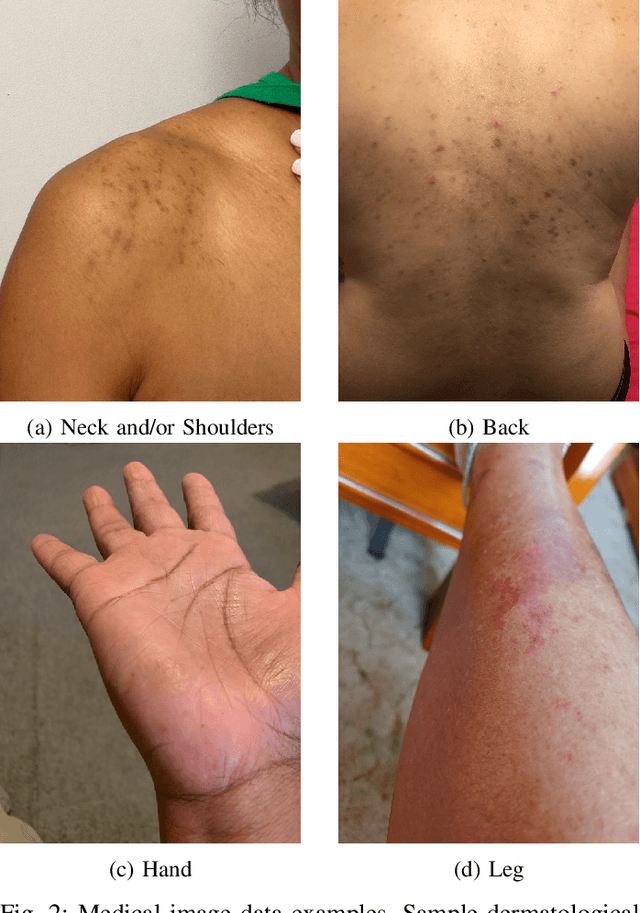
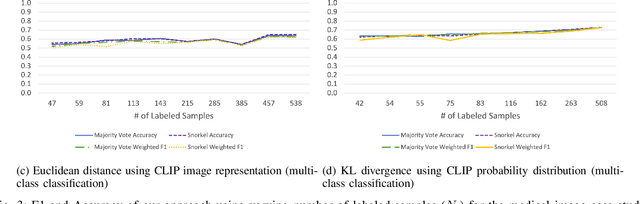
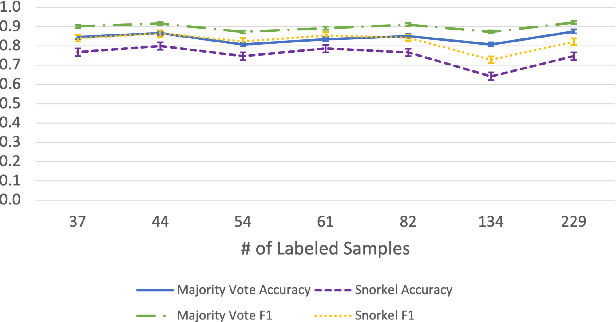
Large Deep Neural Networks (DNNs) are often data hungry and need high-quality labeled data in copious amounts for learning to converge. This is a challenge in the field of medicine since high quality labeled data is often scarce. Data programming has been the ray of hope in this regard, since it allows us to label unlabeled data using multiple weak labeling functions. Such functions are often supplied by a domain expert. Data-programming can combine multiple weak labeling functions and suggest labels better than simple majority voting over the different functions. However, it is not straightforward to express such weak labeling functions, especially in high-dimensional settings such as images and time-series data. What we propose in this paper is a way to bypass this issue, using distance functions. In high-dimensional spaces, it is easier to find meaningful distance metrics which can generalize across different labeling tasks. We propose an algorithm that queries an expert for labels of a few representative samples of the dataset. These samples are carefully chosen by the algorithm to capture the distribution of the dataset. The labels assigned by the expert on the representative subset induce a labeling on the full dataset, thereby generating weak labels to be used in the data programming pipeline. In our medical time series case study, labeling a subset of 50 to 130 out of 3,265 samples showed 17-28% improvement in accuracy and 13-28% improvement in F1 over the baseline using clinician-defined labeling functions. In our medical image case study, labeling a subset of about 50 to 120 images from 6,293 unlabeled medical images using our approach showed significant improvement over the baseline method, Snuba, with an increase of approximately 5-15% in accuracy and 12-19% in F1 score.
Using Semantic Information for Defining and Detecting OOD Inputs
Feb 21, 2023



As machine learning models continue to achieve impressive performance across different tasks, the importance of effective anomaly detection for such models has increased as well. It is common knowledge that even well-trained models lose their ability to function effectively on out-of-distribution inputs. Thus, out-of-distribution (OOD) detection has received some attention recently. In the vast majority of cases, it uses the distribution estimated by the training dataset for OOD detection. We demonstrate that the current detectors inherit the biases in the training dataset, unfortunately. This is a serious impediment, and can potentially restrict the utility of the trained model. This can render the current OOD detectors impermeable to inputs lying outside the training distribution but with the same semantic information (e.g. training class labels). To remedy this situation, we begin by defining what should ideally be treated as an OOD, by connecting inputs with their semantic information content. We perform OOD detection on semantic information extracted from the training data of MNIST and COCO datasets and show that it not only reduces false alarms but also significantly improves the detection of OOD inputs with spurious features from the training data.
Memory Classifiers: Two-stage Classification for Robustness in Machine Learning
Jun 10, 2022



The performance of machine learning models can significantly degrade under distribution shifts of the data. We propose a new method for classification which can improve robustness to distribution shifts, by combining expert knowledge about the ``high-level" structure of the data with standard classifiers. Specifically, we introduce two-stage classifiers called \textit{memory classifiers}. First, these identify prototypical data points -- \textit{memories} -- to cluster the training data. This step is based on features designed with expert guidance; for instance, for image data they can be extracted using digital image processing algorithms. Then, within each cluster, we learn local classifiers based on finer discriminating features, via standard models like deep neural networks. We establish generalization bounds for memory classifiers. We illustrate in experiments that they can improve generalization and robustness to distribution shifts on image datasets. We show improvements which push beyond standard data augmentation techniques.
Single-Camera 3D Head Fitting for Mixed Reality Clinical Applications
Sep 06, 2021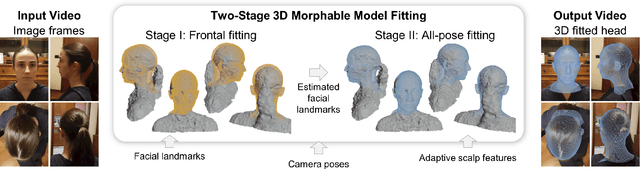
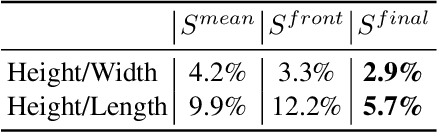


We address the problem of estimating the shape of a person's head, defined as the geometry of the complete head surface, from a video taken with a single moving camera, and determining the alignment of the fitted 3D head for all video frames, irrespective of the person's pose. 3D head reconstructions commonly tend to focus on perfecting the face reconstruction, leaving the scalp to a statistical approximation. Our goal is to reconstruct the head model of each person to enable future mixed reality applications. To do this, we recover a dense 3D reconstruction and camera information via structure-from-motion and multi-view stereo. These are then used in a new two-stage fitting process to recover the 3D head shape by iteratively fitting a 3D morphable model of the head with the dense reconstruction in canonical space and fitting it to each person's head, using both traditional facial landmarks and scalp features extracted from the head's segmentation mask. Our approach recovers consistent geometry for varying head shapes, from videos taken by different people, with different smartphones, and in a variety of environments from living rooms to outdoor spaces.