 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping the Catacombs: An Underwater Cave Segment of the Devil's Eye System
Jul 08, 2025



This paper presents a framework for mapping underwater caves. Underwater caves are crucial for fresh water resource management, underwater archaeology, and hydrogeology. Mapping the cave's outline and dimensions, as well as creating photorealistic 3D maps, is critical for enabling a better understanding of this underwater domain. In this paper, we present the mapping of an underwater cave segment (the catacombs) of the Devil's Eye cave system at Ginnie Springs, FL. We utilized a set of inexpensive action cameras in conjunction with a dive computer to estimate the trajectories of the cameras together with a sparse point cloud. The resulting reconstructions are utilized to produce a one-dimensional retract of the cave passages in the form of the average trajectory together with the boundaries (top, bottom, left, and right). The use of the dive computer enables the observability of the z-dimension in addition to the roll and pitch in a visual/inertial framework (SVIn2). In addition, the keyframes generated by SVIn2 together with the estimated camera poses for select areas are used as input to a global optimization (bundle adjustment) framework -- COLMAP -- in order to produce a dense reconstruction of those areas. The same cave segment is manually surveyed using the MNemo V2 instrument, providing an additional set of measurements validating the proposed approach. It is worth noting that with the use of action cameras, the primary components of a cave map can be constructed. Furthermore, with the utilization of a global optimization framework guided by the results of VI-SLAM package SVIn2, photorealistic dense 3D representations of selected areas can be reconstructed.
Radiant Triangle Soup with Soft Connectivity Forces for 3D Reconstruction and Novel View Synthesis
May 29, 2025



In this work, we introduce an inference-time optimization framework utilizing triangles to represent the geometry and appearance of the scene. More specifically, we develop a scene optimization algorithm for triangle soup, a collection of disconnected semi-transparent triangle primitives. Compared to the current most-widely used primitives for 3D scene representation, namely Gaussian splats, triangles allow for more expressive color interpolation, and benefit from a large algorithmic infrastructure for downstream tasks. Triangles, unlike full-rank Gaussian kernels, naturally combine to form surfaces. We formulate connectivity forces between triangles during optimization, encouraging explicit, but soft, surface continuity in 3D. We perform experiments on a representative 3D reconstruction dataset and show competitive photometric and geometric results.
Glissando-Net: Deep sinGLe vIew category level poSe eStimation ANd 3D recOnstruction
Jan 24, 2025



We present a deep learning model, dubbed Glissando-Net, to simultaneously estimate the pose and reconstruct the 3D shape of objects at the category level from a single RGB image. Previous works predominantly focused on either estimating poses(often at the instance level), or reconstructing shapes, but not both. Glissando-Net is composed of two auto-encoders that are jointly trained, one for RGB images and the other for point clouds. We embrace two key design choices in Glissando-Net to achieve a more accurate prediction of the 3D shape and pose of the object given a single RGB image as input. First, we augment the feature maps of the point cloud encoder and decoder with transformed feature maps from the image decoder, enabling effective 2D-3D interaction in both training and prediction. Second, we predict both the 3D shape and pose of the object in the decoder stage. This way, we better utilize the information in the 3D point clouds presented only in the training stage to train the network for more accurate prediction. We jointly train the two encoder-decoders for RGB and point cloud data to learn how to pass latent features to the point cloud decoder during inference. In testing, the encoder of the 3D point cloud is discarded. The design of Glissando-Net is inspired by codeSLAM. Unlike codeSLAM, which targets 3D reconstruction of scenes, we focus on pose estimation and shape reconstruction of objects, and directly predict the object pose and a pose invariant 3D reconstruction without the need of the code optimization step. Extensive experiments, involving both ablation studies and comparison with competing methods, demonstrate the efficacy of our proposed method, and compare favorably with the state-of-the-art.
Stereo-NEC: Enhancing Stereo Visual-Inertial SLAM Initialization with Normal Epipolar Constraints
Mar 12, 2024



We propose an accurate and robust initialization approach for stereo visual-inertial SLAM systems. Unlike the current state-of-the-art method, which heavily relies on the accuracy of a pure visual SLAM system to estimate inertial variables without updating camera poses, potentially compromising accuracy and robustness, our approach offers a different solution. We realize the crucial impact of precise gyroscope bias estimation on rotation accuracy. This, in turn, affects trajectory accuracy due to the accumulation of translation errors. To address this, we first independently estimate the gyroscope bias and use it to formulate a maximum a posteriori problem for further refinement. After this refinement, we proceed to update the rotation estimation by performing IMU integration with gyroscope bias removed from gyroscope measurements. We then leverage robust and accurate rotation estimates to enhance translation estimation via 3-DoF bundle adjustment. Moreover, we introduce a novel approach for determining the success of the initialization by evaluating the residual of the normal epipolar constraint. Extensive evaluations on the EuRoC dataset illustrate that our method excels in accuracy and robustness. It outperforms ORB-SLAM3, the current leading stereo visual-inertial initialization method, in terms of absolute trajectory error and relative rotation error, while maintaining competitive computational speed. Notably, even with 5 keyframes for initialization, our method consistently surpasses the state-of-the-art approach using 10 keyframes in rotation accuracy.
V-FUSE: Volumetric Depth Map Fusion with Long-Range Constraints
Aug 17, 2023



We introduce a learning-based depth map fusion framework that accepts a set of depth and confidence maps generated by a Multi-View Stereo (MVS) algorithm as input and improves them. This is accomplished by integrating volumetric visibility constraints that encode long-range surface relationships across different views into an end-to-end trainable architecture. We also introduce a depth search window estimation sub-network trained jointly with the larger fusion sub-network to reduce the depth hypothesis search space along each ray. Our method learns to model depth consensus and violations of visibility constraints directly from the data; effectively removing the necessity of fine-tuning fusion parameters. Extensive experiments on MVS datasets show substantial improvements in the accuracy of the output fused depth and confidence maps.
EDI: ESKF-based Disjoint Initialization for Visual-Inertial SLAM Systems
Aug 04, 2023



Visual-inertial initialization can be classified into joint and disjoint approaches. Joint approaches tackle both the visual and the inertial parameters together by aligning observations from feature-bearing points based on IMU integration then use a closed-form solution with visual and acceleration observations to find initial velocity and gravity. In contrast, disjoint approaches independently solve the Structure from Motion (SFM) problem and determine inertial parameters from up-to-scale camera poses obtained from pure monocular SLAM. However, previous disjoint methods have limitations, like assuming negligible acceleration bias impact or accurate rotation estimation by pure monocular SLAM. To address these issues, we propose EDI, a novel approach for fast, accurate, and robust visual-inertial initialization. Our method incorporates an Error-state Kalman Filter (ESKF) to estimate gyroscope bias and correct rotation estimates from monocular SLAM, overcoming dependence on pure monocular SLAM for rotation estimation. To estimate the scale factor without prior information, we offer a closed-form solution for initial velocity, scale, gravity, and acceleration bias estimation. To address gravity and acceleration bias coupling, we introduce weights in the linear least-squares equations, ensuring acceleration bias observability and handling outliers. Extensive evaluation on the EuRoC dataset shows that our method achieves an average scale error of 5.8% in less than 3 seconds, outperforming other state-of-the-art disjoint visual-inertial initialization approaches, even in challenging environments and with artificial noise corruption.
Real-Time Dense 3D Mapping of Underwater Environments
Apr 05, 2023



This paper addresses real-time dense 3D reconstruction for a resource-constrained Autonomous Underwater Vehicle (AUV). Underwater vision-guided operations are among the most challenging as they combine 3D motion in the presence of external forces, limited visibility, and absence of global positioning. Obstacle avoidance and effective path planning require online dense reconstructions of the environment. Autonomous operation is central to environmental monitoring, marine archaeology, resource utilization, and underwater cave exploration. To address this problem, we propose to use SVIn2, a robust VIO method, together with a real-time 3D reconstruction pipeline. We provide extensive evaluation on four challenging underwater datasets. Our pipeline produces comparable reconstruction with that of COLMAP, the state-of-the-art offline 3D reconstruction method, at high frame rates on a single CPU.
Learning the Distribution of Errors in Stereo Matching for Joint Disparity and Uncertainty Estimation
Mar 31, 2023



We present a new loss function for joint disparity and uncertainty estimation in deep stereo matching. Our work is motivated by the need for precise uncertainty estimates and the observation that multi-task learning often leads to improved performance in all tasks. We show that this can be achieved by requiring the distribution of uncertainty to match the distribution of disparity errors via a KL divergence term in the network's loss function. A differentiable soft-histogramming technique is used to approximate the distributions so that they can be used in the loss. We experimentally assess the effectiveness of our approach and observe significant improvements in both disparity and uncertainty prediction on large datasets.
Single-Camera 3D Head Fitting for Mixed Reality Clinical Applications
Sep 06, 2021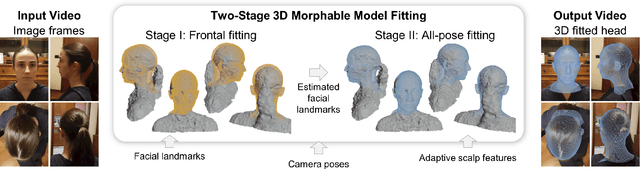
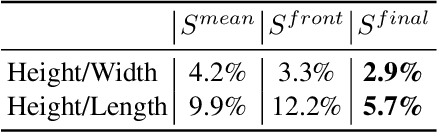


We address the problem of estimating the shape of a person's head, defined as the geometry of the complete head surface, from a video taken with a single moving camera, and determining the alignment of the fitted 3D head for all video frames, irrespective of the person's pose. 3D head reconstructions commonly tend to focus on perfecting the face reconstruction, leaving the scalp to a statistical approximation. Our goal is to reconstruct the head model of each person to enable future mixed reality applications. To do this, we recover a dense 3D reconstruction and camera information via structure-from-motion and multi-view stereo. These are then used in a new two-stage fitting process to recover the 3D head shape by iteratively fitting a 3D morphable model of the head with the dense reconstruction in canonical space and fitting it to each person's head, using both traditional facial landmarks and scalp features extracted from the head's segmentation mask. Our approach recovers consistent geometry for varying head shapes, from videos taken by different people, with different smartphones, and in a variety of environments from living rooms to outdoor spaces.
Do End-to-end Stereo Algorithms Under-utilize Information?
Oct 14, 2020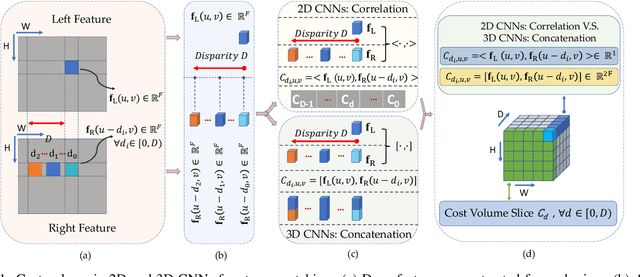
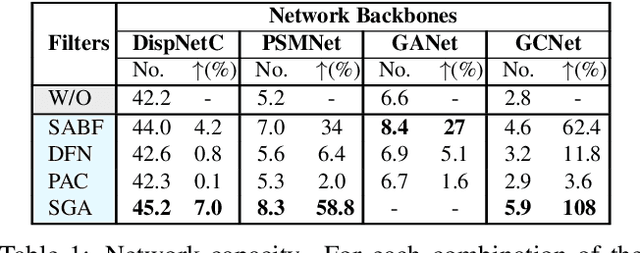
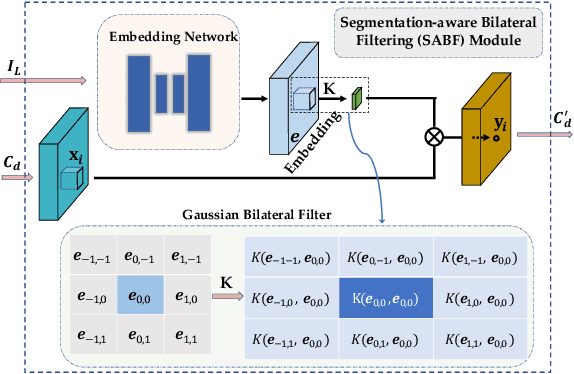
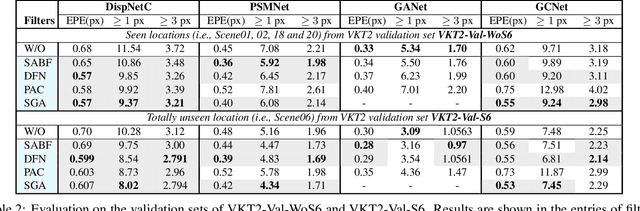
Deep networks for stereo matching typically leverage 2D or 3D convolutional encoder-decoder architectures to aggregate cost and regularize the cost volume for accurate disparity estimation. Due to content-insensitive convolutions and down-sampling and up-sampling operations, these cost aggregation mechanisms do not take full advantage of the information available in the images. Disparity maps suffer from over-smoothing near occlusion boundaries, and erroneous predictions in thin structures. In this paper, we show how deep adaptive filtering and differentiable semi-global aggregation can be integrated in existing 2D and 3D convolutional networks for end-to-end stereo matching, leading to improved accuracy. The improvements are due to utilizing RGB information from the images as a signal to dynamically guide the matching process, in addition to being the signal we attempt to match across the images. We show extensive experimental results on the KITTI 2015 and Virtual KITTI 2 datasets comparing four stereo networks (DispNetC, GCNet, PSMNet and GANet) after integrating four adaptive filters (segmentation-aware bilateral filtering, dynamic filtering networks, pixel adaptive convolution and semi-global aggregation) into their architectures. Our code is available at https://github.com/ccj5351/DAFStereoNets.