 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActiveGAMER: Active GAussian Mapping through Efficient Rendering
Jan 12, 2025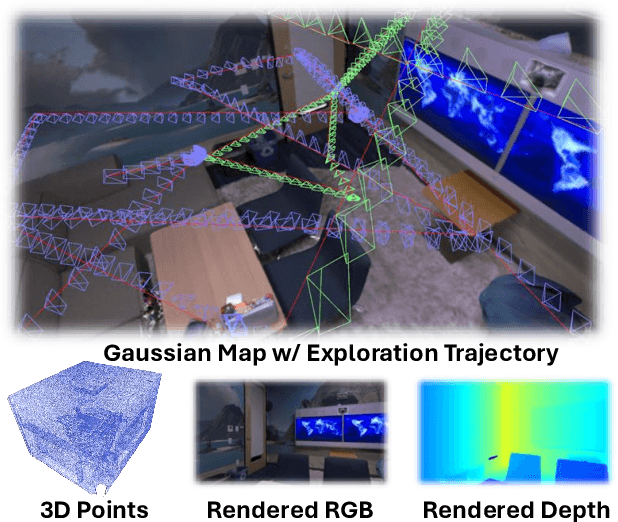
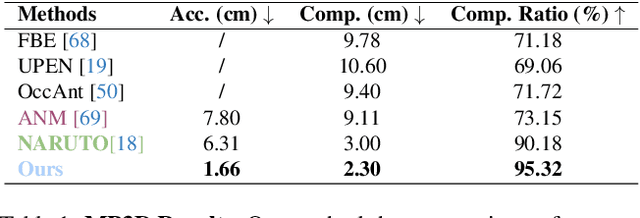

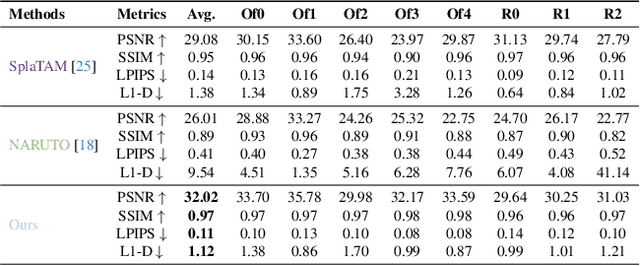
We introduce ActiveGAMER, an active mapping system that utilizes 3D Gaussian Splatting (3DGS) to achieve high-quality, real-time scene mapping and exploration. Unlike traditional NeRF-based methods, which are computationally demanding and restrict active mapping performance, our approach leverages the efficient rendering capabilities of 3DGS, allowing effective and efficient exploration in complex environments. The core of our system is a rendering-based information gain module that dynamically identifies the most informative viewpoints for next-best-view planning, enhancing both geometric and photometric reconstruction accuracy. ActiveGAMER also integrates a carefully balanced framework, combining coarse-to-fine exploration, post-refinement, and a global-local keyframe selection strategy to maximize reconstruction completeness and fidelity. Our system autonomously explores and reconstructs environments with state-of-the-art geometric and photometric accuracy and completeness, significantly surpassing existing approaches in both aspects. Extensive evaluations on benchmark datasets such as Replica and MP3D highlight ActiveGAMER's effectiveness in active mapping tasks.
NARUTO: Neural Active Reconstruction from Uncertain Target Observations
Feb 29, 2024We present NARUTO, a neural active reconstruction system that combines a hybrid neural representation with uncertainty learning, enabling high-fidelity surface reconstruction. Our approach leverages a multi-resolution hash-grid as the mapping backbone, chosen for its exceptional convergence speed and capacity to capture high-frequency local features.The centerpiece of our work is the incorporation of an uncertainty learning module that dynamically quantifies reconstruction uncertainty while actively reconstructing the environment. By harnessing learned uncertainty, we propose a novel uncertainty aggregation strategy for goal searching and efficient path planning. Our system autonomously explores by targeting uncertain observations and reconstructs environments with remarkable completeness and fidelity. We also demonstrate the utility of this uncertainty-aware approach by enhancing SOTA neural SLAM systems through an active ray sampling strategy. Extensive evaluations of NARUTO in various environments, using an indoor scene simulator, confirm its superior performance and state-of-the-art status in active reconstruction, as evidenced by its impressive results on benchmark datasets like Replica and MP3D.
PlanarNeRF: Online Learning of Planar Primitives with Neural Radiance Fields
Dec 30, 2023Identifying spatially complete planar primitives from visual data is a crucial task in computer vision. Prior methods are largely restricted to either 2D segment recovery or simplifying 3D structures, even with extensive plane annotations. We present PlanarNeRF, a novel framework capable of detecting dense 3D planes through online learning. Drawing upon the neural field representation, PlanarNeRF brings three major contributions. First, it enhances 3D plane detection with concurrent appearance and geometry knowledge. Second, a lightweight plane fitting module is proposed to estimate plane parameters. Third, a novel global memory bank structure with an update mechanism is introduced, ensuring consistent cross-frame correspondence. The flexible architecture of PlanarNeRF allows it to function in both 2D-supervised and self-supervised solutions, in each of which it can effectively learn from sparse training signals, significantly improving training efficiency. Through extensive experiments, we demonstrate the effectiveness of PlanarNeRF in various scenarios and remarkable improvement over existing works.
Dynamic Voxel Grid Optimization for High-Fidelity RGB-D Supervised Surface Reconstruction
Apr 12, 2023Direct optimization of interpolated features on multi-resolution voxel grids has emerged as a more efficient alternative to MLP-like modules. However, this approach is constrained by higher memory expenses and limited representation capabilities. In this paper, we introduce a novel dynamic grid optimization method for high-fidelity 3D surface reconstruction that incorporates both RGB and depth observations. Rather than treating each voxel equally, we optimize the process by dynamically modifying the grid and assigning more finer-scale voxels to regions with higher complexity, allowing us to capture more intricate details. Furthermore, we develop a scheme to quantify the dynamic subdivision of voxel grid during optimization without requiring any priors. The proposed approach is able to generate high-quality 3D reconstructions with fine details on both synthetic and real-world data, while maintaining computational efficiency, which is substantially faster than the baseline method NeuralRGBD.
CLIP-FLow: Contrastive Learning by semi-supervised Iterative Pseudo labeling for Optical Flow Estimation
Nov 01, 2022
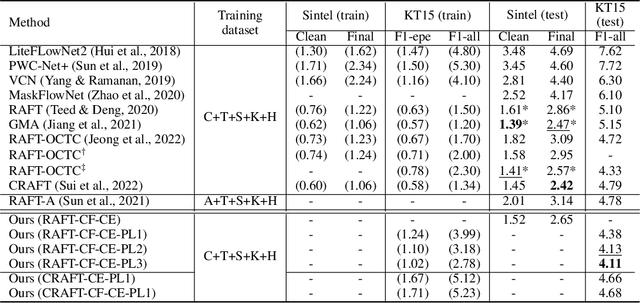
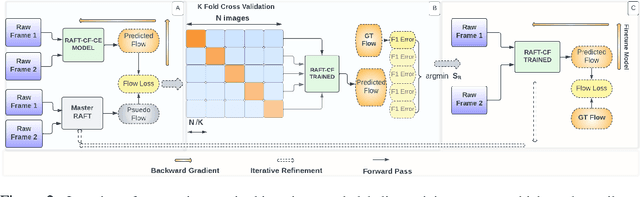
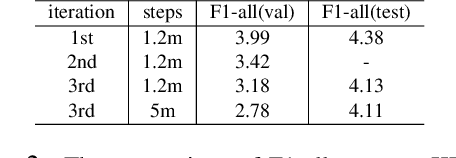
Synthetic datasets are often used to pretrain end-to-end optical flow networks, due to the lack of a large amount of labeled, real-scene data. But major drops in accuracy occur when moving from synthetic to real scenes. How do we better transfer the knowledge learned from synthetic to real domains? To this end, we propose CLIP-FLow, a semi-supervised iterative pseudo-labeling framework to transfer the pretraining knowledge to the target real domain. We leverage large-scale, unlabeled real data to facilitate transfer learning with the supervision of iteratively updated pseudo-ground truth labels, bridging the domain gap between the synthetic and the real. In addition, we propose a contrastive flow loss on reference features and the warped features by pseudo ground truth flows, to further boost the accurate matching and dampen the mismatching due to motion, occlusion, or noisy pseudo labels. We adopt RAFT as the backbone and obtain an F1-all error of 4.11%, i.e. a 19% error reduction from RAFT (5.10%) and ranking 2$^{nd}$ place at submission on the KITTI 2015 benchmark. Our framework can also be extended to other models, e.g. CRAFT, reducing the F1-all error from 4.79% to 4.66% on KITTI 2015 benchmark.
RIAV-MVS: Recurrent-Indexing an Asymmetric Volume for Multi-View Stereo
May 28, 2022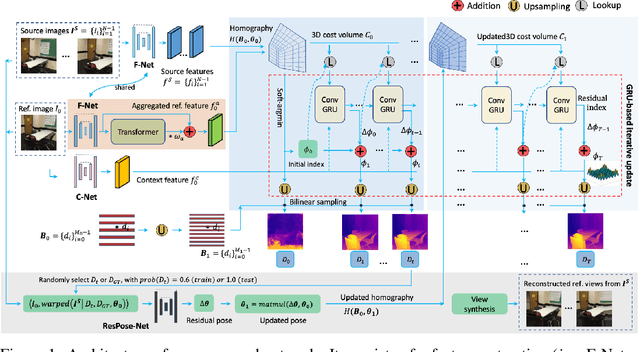
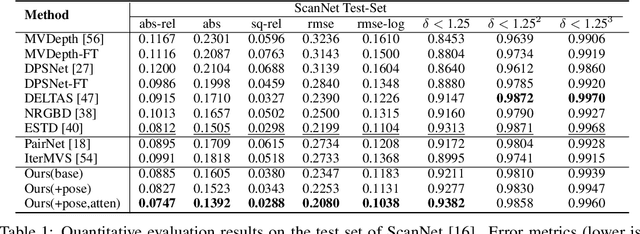
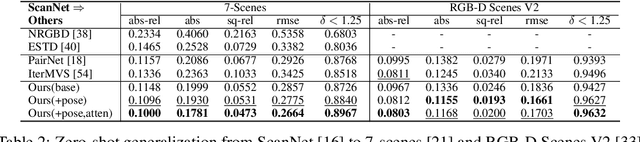

In this paper, we present a learning-based approach for multi-view stereo (MVS), i.e., estimate the depth map of a reference frame using posed multi-view images. Our core idea lies in leveraging a "learning-to-optimize" paradigm to iteratively index a plane-sweeping cost volume and regress the depth map via a convolutional Gated Recurrent Unit (GRU). Since the cost volume plays a paramount role in encoding the multi-view geometry, we aim to improve its construction both in pixel- and frame- levels. In the pixel level, we propose to break the symmetry of the Siamese network (which is typically used in MVS to extract image features) by introducing a transformer block to the reference image (but not to the source images). Such an asymmetric volume allows the network to extract global features from the reference image to predict its depth map. In view of the inaccuracy of poses between reference and source images, we propose to incorporate a residual pose network to make corrections to the relative poses, which essentially rectifies the cost volume in the frame-level. We conduct extensive experiments on real-world MVS datasets and show that our method achieves state-of-the-art performance in terms of both within-dataset evaluation and cross-dataset generalization.
PlaneMVS: 3D Plane Reconstruction from Multi-View Stereo
Mar 28, 2022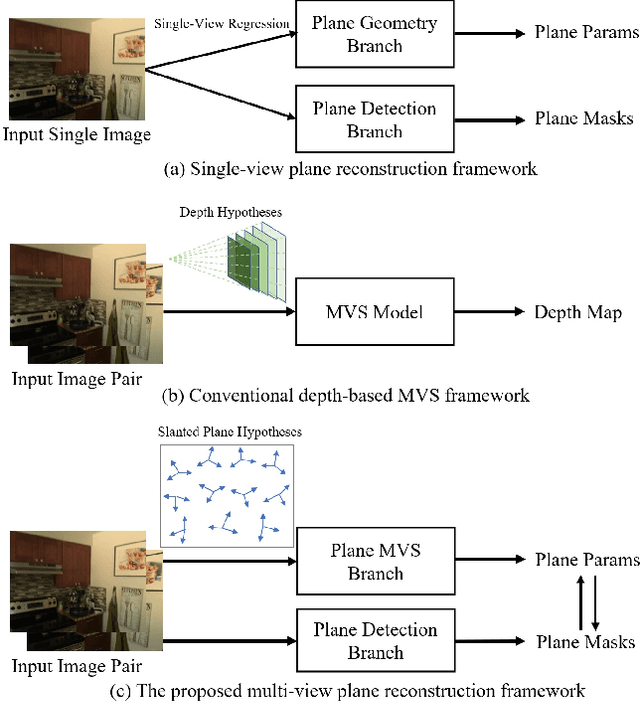

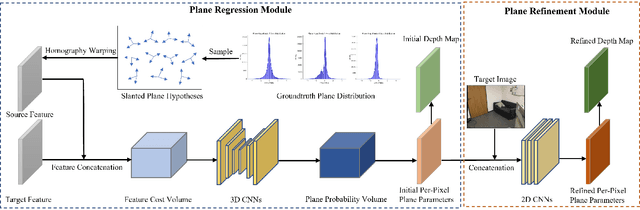
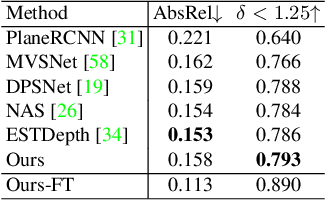
We present a novel framework named PlaneMVS for 3D plane reconstruction from multiple input views with known camera poses. Most previous learning-based plane reconstruction methods reconstruct 3D planes from single images, which highly rely on single-view regression and suffer from depth scale ambiguity. In contrast, we reconstruct 3D planes with a multi-view-stereo (MVS) pipeline that takes advantage of multi-view geometry. We decouple plane reconstruction into a semantic plane detection branch and a plane MVS branch. The semantic plane detection branch is based on a single-view plane detection framework but with differences. The plane MVS branch adopts a set of slanted plane hypotheses to replace conventional depth hypotheses to perform plane sweeping strategy and finally learns pixel-level plane parameters and its planar depth map. We present how the two branches are learned in a balanced way, and propose a soft-pooling loss to associate the outputs of the two branches and make them benefit from each other. Extensive experiments on various indoor datasets show that PlaneMVS significantly outperforms state-of-the-art (SOTA) single-view plane reconstruction methods on both plane detection and 3D geometry metrics. Our method even outperforms a set of SOTA learning-based MVS methods thanks to the learned plane priors. To the best of our knowledge, this is the first work on 3D plane reconstruction within an end-to-end MVS framework.
Do End-to-end Stereo Algorithms Under-utilize Information?
Oct 14, 2020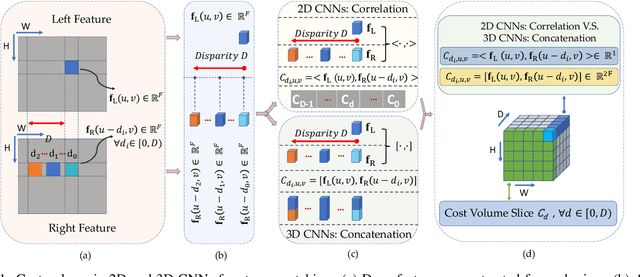
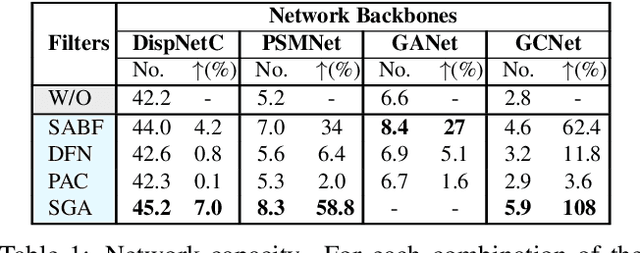
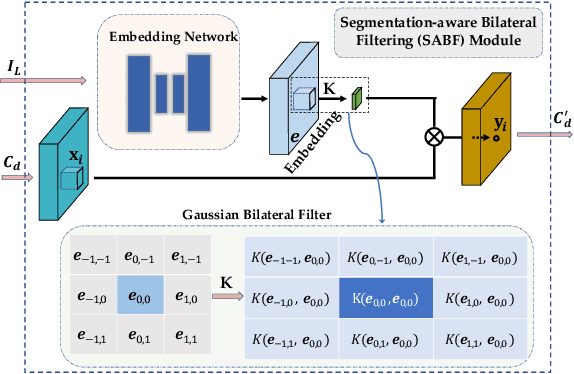
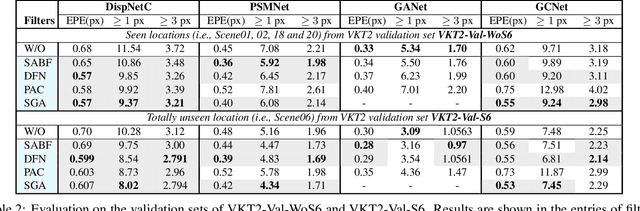
Deep networks for stereo matching typically leverage 2D or 3D convolutional encoder-decoder architectures to aggregate cost and regularize the cost volume for accurate disparity estimation. Due to content-insensitive convolutions and down-sampling and up-sampling operations, these cost aggregation mechanisms do not take full advantage of the information available in the images. Disparity maps suffer from over-smoothing near occlusion boundaries, and erroneous predictions in thin structures. In this paper, we show how deep adaptive filtering and differentiable semi-global aggregation can be integrated in existing 2D and 3D convolutional networks for end-to-end stereo matching, leading to improved accuracy. The improvements are due to utilizing RGB information from the images as a signal to dynamically guide the matching process, in addition to being the signal we attempt to match across the images. We show extensive experimental results on the KITTI 2015 and Virtual KITTI 2 datasets comparing four stereo networks (DispNetC, GCNet, PSMNet and GANet) after integrating four adaptive filters (segmentation-aware bilateral filtering, dynamic filtering networks, pixel adaptive convolution and semi-global aggregation) into their architectures. Our code is available at https://github.com/ccj5351/DAFStereoNets.
Matching-space Stereo Networks for Cross-domain Generalization
Oct 14, 2020
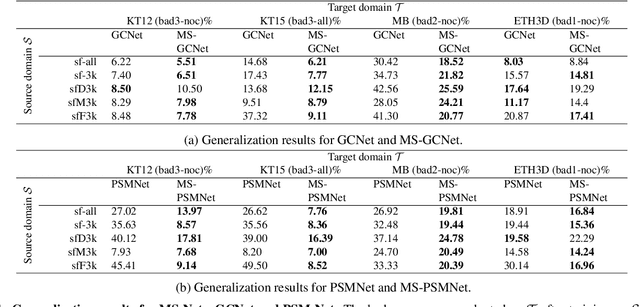
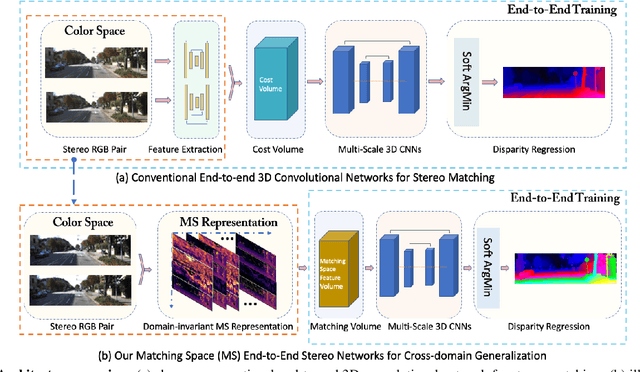

End-to-end deep networks represent the state of the art for stereo matching. While excelling on images framing environments similar to the training set, major drops in accuracy occur in unseen domains (e.g., when moving from synthetic to real scenes). In this paper we introduce a novel family of architectures, namely Matching-Space Networks (MS-Nets), with improved generalization properties. By replacing learning-based feature extraction from image RGB values with matching functions and confidence measures from conventional wisdom, we move the learning process from the color space to the Matching Space, avoiding over-specialization to domain specific features. Extensive experimental results on four real datasets highlight that our proposal leads to superior generalization to unseen environments over conventional deep architectures, keeping accuracy on the source domain almost unaltered. Our code is available at https://github.com/ccj5351/MS-Nets.
Towards Robust RGB-D Human Mesh Recovery
Nov 18, 2019
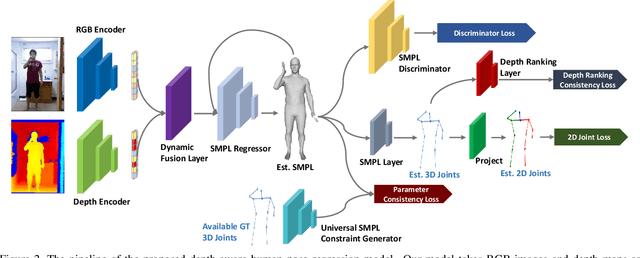
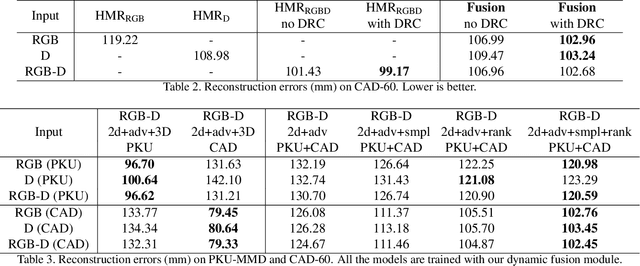
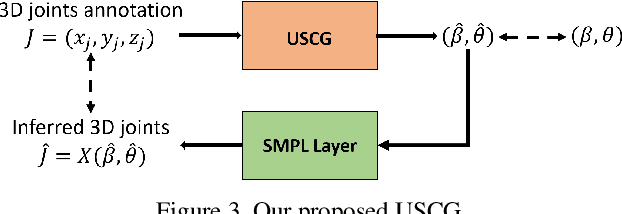
We consider the problem of human pose estimation. While much recent work has focused on the RGB domain, these techniques are inherently under-constrained since there can be many 3D configurations that explain the same 2D projection. To this end, we propose a new method that uses RGB-D data to estimate a parametric human mesh model. Our key innovations include (a) the design of a new dynamic data fusion module that facilitates learning with a combination of RGB-only and RGB-D datasets, (b) a new constraint generator module that provides SMPL supervisory signals when explicit SMPL annotations are not available, and (c) the design of a new depth ranking learning objective, all of which enable principled model training with RGB-D data. We conduct extensive experiments on a variety of RGB-D datasets to demonstrate efficacy.