 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason via Mixture-of-Thought for Logical Reasoning
May 21, 2025Human beings naturally utilize multiple reasoning modalities to learn and solve logical problems, i.e., different representational formats such as natural language, code, and symbolic logic. In contrast, most existing LLM-based approaches operate with a single reasoning modality during training, typically natural language. Although some methods explored modality selection or augmentation at inference time, the training process remains modality-blind, limiting synergy among modalities. To fill in this gap, we propose Mixture-of-Thought (MoT), a framework that enables LLMs to reason across three complementary modalities: natural language, code, and a newly introduced symbolic modality, truth-table, which systematically enumerates logical cases and partially mitigates key failure modes in natural language reasoning. MoT adopts a two-phase design: (1) self-evolving MoT training, which jointly learns from filtered, self-generated rationales across modalities; and (2) MoT inference, which fully leverages the synergy of three modalities to produce better predictions. Experiments on logical reasoning benchmarks including FOLIO and ProofWriter demonstrate that our MoT framework consistently and significantly outperforms strong LLM baselines with single-modality chain-of-thought approaches, achieving up to +11.7pp average accuracy gain. Further analyses show that our MoT framework benefits both training and inference stages; that it is particularly effective on harder logical reasoning problems; and that different modalities contribute complementary strengths, with truth-table reasoning helping to overcome key bottlenecks in natural language inference.
Creativity or Brute Force? Using Brainteasers as a Window into the Problem-Solving Abilities of Large Language Models
May 16, 2025
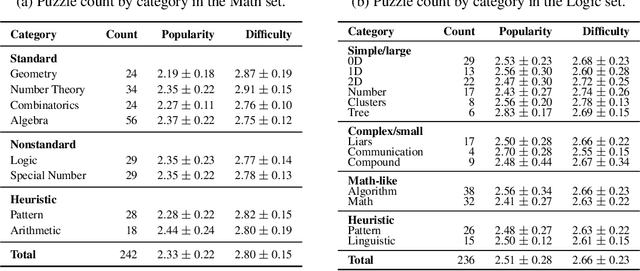

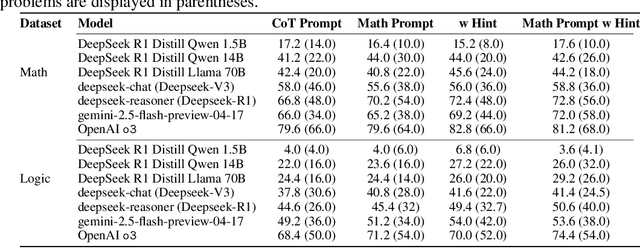
Accuracy remains a standard metric for evaluating AI systems, but it offers limited insight into how models arrive at their solutions. In this work, we introduce a benchmark based on brainteasers written in long narrative form to probe more deeply into the types of reasoning strategies that models use. Brainteasers are well-suited for this goal because they can be solved with multiple approaches, such as a few-step solution that uses a creative insight or a longer solution that uses more brute force. We investigate large language models (LLMs) across multiple layers of reasoning, focusing not only on correctness but also on the quality and creativity of their solutions. We investigate many aspects of the reasoning process: (1) semantic parsing of the brainteasers into precise mathematical competition style formats; (2) generating solutions from these mathematical forms; (3) self-correcting solutions based on gold solutions; (4) producing step-by-step sketches of solutions; and (5) making use of hints. We find that LLMs are in many cases able to find creative, insightful solutions to brainteasers, suggesting that they capture some of the capacities needed to solve novel problems in creative ways. Nonetheless, there also remain situations where they rely on brute force despite the availability of more efficient, creative solutions, highlighting a potential direction for improvement in the reasoning abilities of LLMs.
Self-rewarding correction for mathematical reasoning
Feb 26, 2025We study self-rewarding reasoning large language models (LLMs), which can simultaneously generate step-by-step reasoning and evaluate the correctness of their outputs during the inference time-without external feedback. This integrated approach allows a single model to independently guide its reasoning process, offering computational advantages for model deployment. We particularly focus on the representative task of self-correction, where models autonomously detect errors in their responses, revise outputs, and decide when to terminate iterative refinement loops. To enable this, we propose a two-staged algorithmic framework for constructing self-rewarding reasoning models using only self-generated data. In the first stage, we employ sequential rejection sampling to synthesize long chain-of-thought trajectories that incorporate both self-rewarding and self-correction mechanisms. Fine-tuning models on these curated data allows them to learn the patterns of self-rewarding and self-correction. In the second stage, we further enhance the models' ability to assess response accuracy and refine outputs through reinforcement learning with rule-based signals. Experiments with Llama-3 and Qwen-2.5 demonstrate that our approach surpasses intrinsic self-correction capabilities and achieves performance comparable to systems that rely on external reward models.
OmnixR: Evaluating Omni-modality Language Models on Reasoning across Modalities
Oct 16, 2024We introduce OmnixR, an evaluation suite designed to benchmark SoTA Omni-modality Language Models, such as GPT-4o and Gemini. Evaluating OLMs, which integrate multiple modalities such as text, vision, and audio, presents unique challenges. Particularly, the user message might often consist of multiple modalities, such that OLMs have to establish holistic understanding and reasoning across modalities to accomplish the task. Existing benchmarks are limited to single modality or dual-modality tasks, overlooking comprehensive multi-modal assessments of model reasoning. To address this, OmnixR offers two evaluation variants: (1)synthetic subset: a synthetic dataset generated automatically by translating text into multiple modalities--audio, images, video, and hybrids (Omnify). (2)realistic subset: a real-world dataset, manually curated and annotated by experts, for evaluating cross-modal reasoning in natural settings. OmnixR presents a unique evaluation towards assessing OLMs over a diverse mix of modalities, such as a question that involves video, audio, and text, providing a rigorous cross-modal reasoning testbed unlike any existing benchmarks. Our experiments find that all state-of-the-art OLMs struggle with OmnixR questions that require integrating information from multiple modalities to answer. Further analysis highlights differences in reasoning behavior, underscoring the challenges of omni-modal AI alignment.
From Lists to Emojis: How Format Bias Affects Model Alignment
Sep 18, 2024



In this paper, we study format biases in reinforcement learning from human feedback (RLHF). We observe that many widely-used preference models, including human evaluators, GPT-4, and top-ranking models on the RewardBench benchmark, exhibit strong biases towards specific format patterns, such as lists, links, bold text, and emojis. Furthermore, large language models (LLMs) can exploit these biases to achieve higher rankings on popular benchmarks like AlpacaEval and LMSYS Chatbot Arena. One notable example of this is verbosity bias, where current preference models favor longer responses that appear more comprehensive, even when their quality is equal to or lower than shorter, competing responses. However, format biases beyond verbosity remain largely underexplored in the literature. In this work, we extend the study of biases in preference learning beyond the commonly recognized length bias, offering a comprehensive analysis of a wider range of format biases. Additionally, we show that with a small amount of biased data (less than 1%), we can inject significant bias into the reward model. Moreover, these format biases can also be easily exploited by downstream alignment algorithms, such as best-of-n sampling and online iterative DPO, as it is usually easier to manipulate the format than to improve the quality of responses. Our findings emphasize the need to disentangle format and content both for designing alignment algorithms and evaluating models.
OPTune: Efficient Online Preference Tuning
Jun 11, 2024
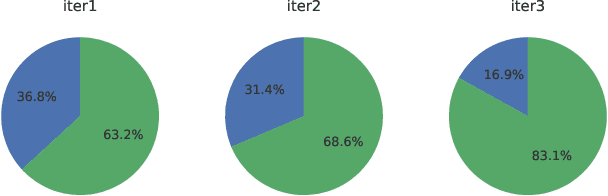

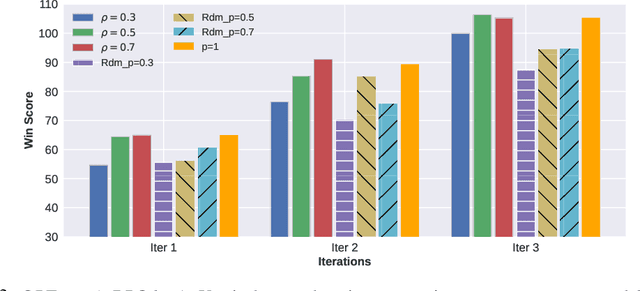
Reinforcement learning with human feedback~(RLHF) is critical for aligning Large Language Models (LLMs) with human preference. Compared to the widely studied offline version of RLHF, \emph{e.g.} direct preference optimization (DPO), recent works have shown that the online variants achieve even better alignment. However, online alignment requires on-the-fly generation of new training data, which is costly, hard to parallelize, and suffers from varying quality and utility. In this paper, we propose a more efficient data exploration strategy for online preference tuning (OPTune), which does not rely on human-curated or pre-collected teacher responses but dynamically samples informative responses for on-policy preference alignment. During data generation, OPTune only selects prompts whose (re)generated responses can potentially provide more informative and higher-quality training signals than the existing responses. In the training objective, OPTune reweights each generated response (pair) by its utility in improving the alignment so that learning can be focused on the most helpful samples. Throughout our evaluations, OPTune'd LLMs maintain the instruction-following benefits provided by standard preference tuning whilst enjoying 1.27-1.56x faster training speed due to the efficient data exploration strategy.
Unveiling the Impact of Coding Data Instruction Fine-Tuning on Large Language Models Reasoning
May 30, 2024



Instruction Fine-Tuning (IFT) significantly enhances the zero-shot capabilities of pretrained Large Language Models (LLMs). While coding data is known to boost reasoning abilities during LLM pretraining, its role in activating internal reasoning capacities during IFT remains understudied. This paper investigates a key question: How does coding data impact LLMs' reasoning capacities during the IFT stage? To explore this, we thoroughly examine the impact of coding data across different coding data proportions, model families, sizes, and reasoning domains, from various perspectives. Specifically, we create three IFT datasets with increasing coding data proportions, fine-tune six LLM backbones across different families and scales on these datasets, evaluate the tuned models' performance across twelve tasks in three reasoning domains, and analyze the outcomes from three broad-to-granular perspectives: overall, domain-level, and task-specific. Our holistic analysis provides valuable insights in each perspective. First, coding data tuning enhances the overall reasoning capabilities of LLMs across different model families and scales. Moreover, the effect of coding data varies among different domains but shows consistent trends across model families and scales within each domain. Additionally, coding data generally yields comparable task-specific benefits across different model families, with the optimal coding data proportions in IFT datasets being task-specific.
Spectrum AUC Difference (SAUCD): Human-aligned 3D Shape Evaluation
Mar 03, 2024



Existing 3D mesh shape evaluation metrics mainly focus on the overall shape but are usually less sensitive to local details. This makes them inconsistent with human evaluation, as human perception cares about both overall and detailed shape. In this paper, we propose an analytic metric named Spectrum Area Under the Curve Difference (SAUCD) that demonstrates better consistency with human evaluation. To compare the difference between two shapes, we first transform the 3D mesh to the spectrum domain using the discrete Laplace-Beltrami operator and Fourier transform. Then, we calculate the Area Under the Curve (AUC) difference between the two spectrums, so that each frequency band that captures either the overall or detailed shape is equitably considered. Taking human sensitivity across frequency bands into account, we further extend our metric by learning suitable weights for each frequency band which better aligns with human perception. To measure the performance of SAUCD, we build a 3D mesh evaluation dataset called Shape Grading, along with manual annotations from more than 800 subjects. By measuring the correlation between our metric and human evaluation, we demonstrate that SAUCD is well aligned with human evaluation, and outperforms previous 3D mesh metrics.
Your Vision-Language Model Itself Is a Strong Filter: Towards High-Quality Instruction Tuning with Data Selection
Feb 19, 2024



Data selection in instruction tuning emerges as a pivotal process for acquiring high-quality data and training instruction-following large language models (LLMs), but it is still a new and unexplored research area for vision-language models (VLMs). Existing data selection approaches on LLMs either rely on single unreliable scores, or use downstream tasks for selection, which is time-consuming and can lead to potential over-fitting on the chosen evaluation datasets. To address this challenge, we introduce a novel dataset selection method, Self-Filter, that utilizes the VLM itself as a filter. This approach is inspired by the observation that VLMs benefit from training with the most challenging instructions. Self-Filter operates in two stages. In the first stage, we devise a scoring network to evaluate the difficulty of training instructions, which is co-trained with the VLM. In the second stage, we use the trained score net to measure the difficulty of each instruction, select the most challenging samples, and penalize similar samples to encourage diversity. Comprehensive experiments on LLaVA and MiniGPT-4 show that Self-Filter can reach better results compared to full data settings with merely about 15% samples, and can achieve superior performance against competitive baselines.
Can LLMs Speak For Diverse People? Tuning LLMs via Debate to Generate Controllable Controversial Statements
Feb 16, 2024Making LLMs speak for different, especially minority groups of people, and generate statements supporting their diverse or even controversial perspectives is critical to creating an inclusive environment. However, existing LLMs lack sufficient controllability to the stance of their generated content, which often contains inconsistent, neutral, or biased statements. In this paper, we improve the controllability of LLMs in generating statements supporting an argument the user defined in the prompt. We find that multi-round debates between two LLMs with opposite stances generate higher-quality and more salient statements for each, which are important training data to improve the controllability of LLMs. Motivated by this, we develop a novel debate & tuning ("DEBATunE") pipeline finetuning LLMs to generate the statements obtained via debate. To examine DEBATunE, we curate the largest dataset of debate topics so far, which covers 710 controversial topics and corresponding arguments for each topic. Evaluations by the GPT-4 judge with a novel controversy controllability metric show that LLMs' capability of expressing diverse perspectives is significantly improved by DEBATunE. Moreover, such controllability can be generalized to unseen topics, generating high-quality statements supporting controversial arguments. Our codes, models, and data will be released at https://github.com/tianyi-lab/DEBATunE.