 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps
Jan 16, 2025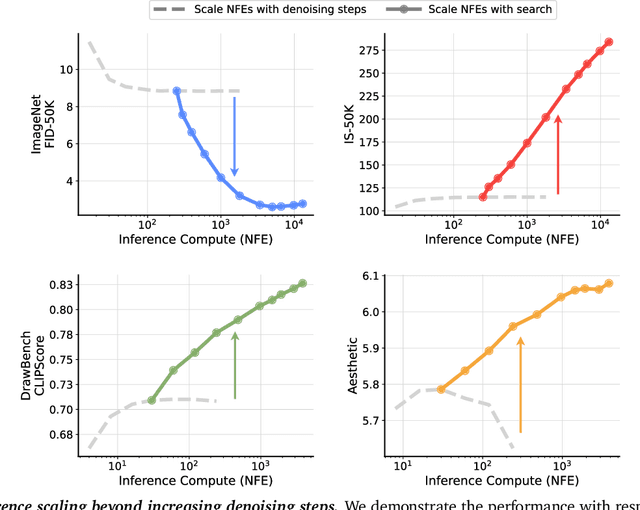
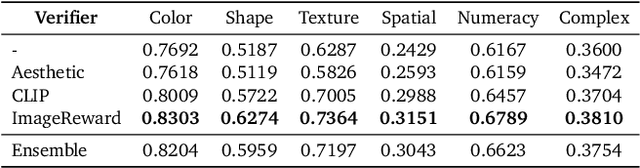
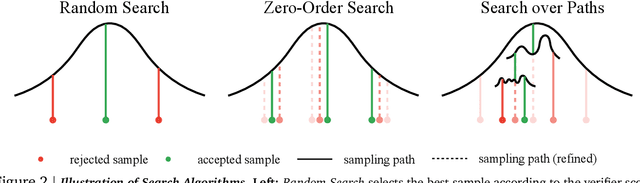
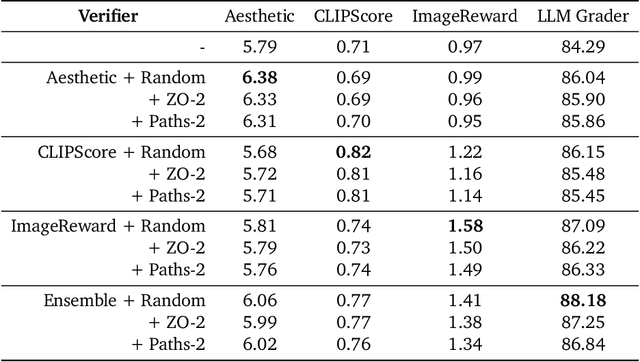
Generative models have made significant impacts across various domains, largely due to their ability to scale during training by increasing data, computational resources, and model size, a phenomenon characterized by the scaling laws. Recent research has begun to explore inference-time scaling behavior in Large Language Models (LLMs), revealing how performance can further improve with additional computation during inference. Unlike LLMs, diffusion models inherently possess the flexibility to adjust inference-time computation via the number of denoising steps, although the performance gains typically flatten after a few dozen. In this work, we explore the inference-time scaling behavior of diffusion models beyond increasing denoising steps and investigate how the generation performance can further improve with increased computation. Specifically, we consider a search problem aimed at identifying better noises for the diffusion sampling process. We structure the design space along two axes: the verifiers used to provide feedback, and the algorithms used to find better noise candidates. Through extensive experiments on class-conditioned and text-conditioned image generation benchmarks, our findings reveal that increasing inference-time compute leads to substantial improvements in the quality of samples generated by diffusion models, and with the complicated nature of images, combinations of the components in the framework can be specifically chosen to conform with different application scenario.
Video Creation by Demonstration
Dec 12, 2024



We explore a novel video creation experience, namely Video Creation by Demonstration. Given a demonstration video and a context image from a different scene, we generate a physically plausible video that continues naturally from the context image and carries out the action concepts from the demonstration. To enable this capability, we present $\delta$-Diffusion, a self-supervised training approach that learns from unlabeled videos by conditional future frame prediction. Unlike most existing video generation controls that are based on explicit signals, we adopts the form of implicit latent control for maximal flexibility and expressiveness required by general videos. By leveraging a video foundation model with an appearance bottleneck design on top, we extract action latents from demonstration videos for conditioning the generation process with minimal appearance leakage. Empirically, $\delta$-Diffusion outperforms related baselines in terms of both human preference and large-scale machine evaluations, and demonstrates potentials towards interactive world simulation. Sampled video generation results are available at https://delta-diffusion.github.io/.
The Spatial Complexity of Optical Computing and How to Reduce It
Nov 15, 2024



Similar to algorithms, which consume time and memory to run, hardware requires resources to function. For devices processing physical waves, implementing operations needs sufficient "space," as dictated by wave physics. How much space is needed to perform a certain function is a fundamental question in optics, with recent research addressing it for given mathematical operations, but not for more general computing tasks, e.g., classification. Inspired by computational complexity theory, we study the "spatial complexity" of optical computing systems in terms of scaling laws - specifically, how their physical dimensions must scale as the dimension of the mathematical operation increases - and propose a new paradigm for designing optical computing systems: space-efficient neuromorphic optics, based on structural sparsity constraints and neural pruning methods motivated by wave physics (notably, the concept of "overlapping nonlocality"). On two mainstream platforms, free-space optics and on-chip integrated photonics, our methods demonstrate substantial size reductions (to 1%-10% the size of conventional designs) with minimal compromise on performance. Our theoretical and computational results reveal a trend of diminishing returns on accuracy as structure dimensions increase, providing a new perspective for interpreting and approaching the ultimate limits of optical computing - a balanced trade-off between device size and accuracy.
OmnixR: Evaluating Omni-modality Language Models on Reasoning across Modalities
Oct 16, 2024We introduce OmnixR, an evaluation suite designed to benchmark SoTA Omni-modality Language Models, such as GPT-4o and Gemini. Evaluating OLMs, which integrate multiple modalities such as text, vision, and audio, presents unique challenges. Particularly, the user message might often consist of multiple modalities, such that OLMs have to establish holistic understanding and reasoning across modalities to accomplish the task. Existing benchmarks are limited to single modality or dual-modality tasks, overlooking comprehensive multi-modal assessments of model reasoning. To address this, OmnixR offers two evaluation variants: (1)synthetic subset: a synthetic dataset generated automatically by translating text into multiple modalities--audio, images, video, and hybrids (Omnify). (2)realistic subset: a real-world dataset, manually curated and annotated by experts, for evaluating cross-modal reasoning in natural settings. OmnixR presents a unique evaluation towards assessing OLMs over a diverse mix of modalities, such as a question that involves video, audio, and text, providing a rigorous cross-modal reasoning testbed unlike any existing benchmarks. Our experiments find that all state-of-the-art OLMs struggle with OmnixR questions that require integrating information from multiple modalities to answer. Further analysis highlights differences in reasoning behavior, underscoring the challenges of omni-modal AI alignment.
$ε$-VAE: Denoising as Visual Decoding
Oct 05, 2024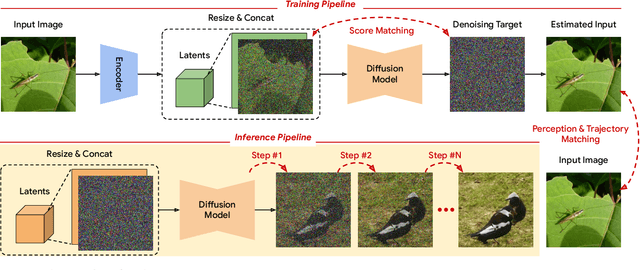
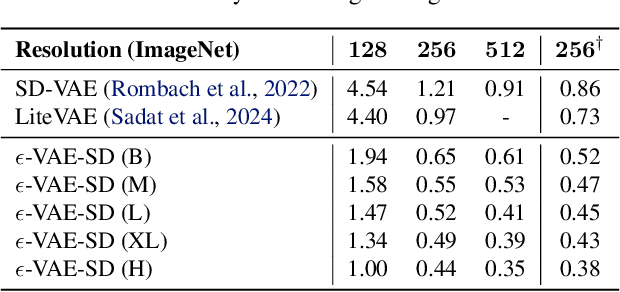
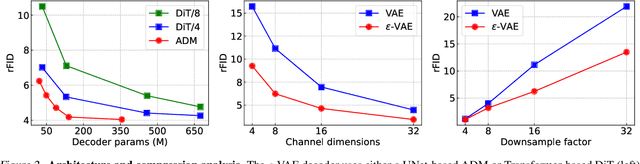
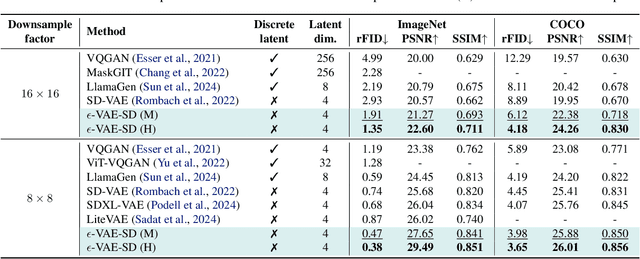
In generative modeling, tokenization simplifies complex data into compact, structured representations, creating a more efficient, learnable space. For high-dimensional visual data, it reduces redundancy and emphasizes key features for high-quality generation. Current visual tokenization methods rely on a traditional autoencoder framework, where the encoder compresses data into latent representations, and the decoder reconstructs the original input. In this work, we offer a new perspective by proposing denoising as decoding, shifting from single-step reconstruction to iterative refinement. Specifically, we replace the decoder with a diffusion process that iteratively refines noise to recover the original image, guided by the latents provided by the encoder. We evaluate our approach by assessing both reconstruction (rFID) and generation quality (FID), comparing it to state-of-the-art autoencoding approach. We hope this work offers new insights into integrating iterative generation and autoencoding for improved compression and generation.
Perturbing Attention Gives You More Bang for the Buck: Subtle Imaging Perturbations That Efficiently Fool Customized Diffusion Models
Apr 23, 2024


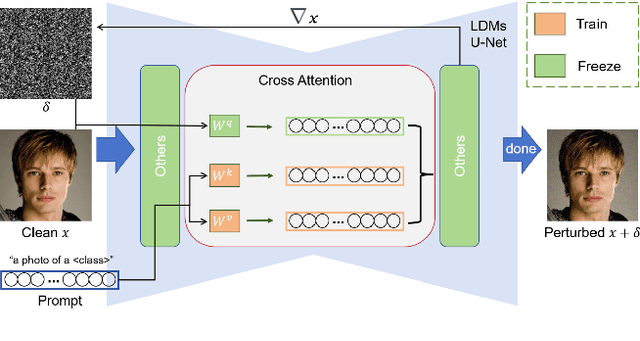
Diffusion models (DMs) embark a new era of generative modeling and offer more opportunities for efficient generating high-quality and realistic data samples. However, their widespread use has also brought forth new challenges in model security, which motivates the creation of more effective adversarial attackers on DMs to understand its vulnerability. We propose CAAT, a simple but generic and efficient approach that does not require costly training to effectively fool latent diffusion models (LDMs). The approach is based on the observation that cross-attention layers exhibits higher sensitivity to gradient change, allowing for leveraging subtle perturbations on published images to significantly corrupt the generated images. We show that a subtle perturbation on an image can significantly impact the cross-attention layers, thus changing the mapping between text and image during the fine-tuning of customized diffusion models. Extensive experiments demonstrate that CAAT is compatible with diverse diffusion models and outperforms baseline attack methods in a more effective (more noise) and efficient (twice as fast as Anti-DreamBooth and Mist) manner.
RoboDreamer: Learning Compositional World Models for Robot Imagination
Apr 18, 2024

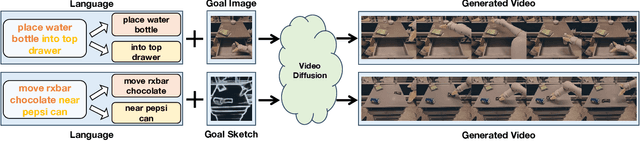

Text-to-video models have demonstrated substantial potential in robotic decision-making, enabling the imagination of realistic plans of future actions as well as accurate environment simulation. However, one major issue in such models is generalization -- models are limited to synthesizing videos subject to language instructions similar to those seen at training time. This is heavily limiting in decision-making, where we seek a powerful world model to synthesize plans of unseen combinations of objects and actions in order to solve previously unseen tasks in new environments. To resolve this issue, we introduce RoboDreamer, an innovative approach for learning a compositional world model by factorizing the video generation. We leverage the natural compositionality of language to parse instructions into a set of lower-level primitives, which we condition a set of models on to generate videos. We illustrate how this factorization naturally enables compositional generalization, by allowing us to formulate a new natural language instruction as a combination of previously seen components. We further show how such a factorization enables us to add additional multimodal goals, allowing us to specify a video we wish to generate given both natural language instructions and a goal image. Our approach can successfully synthesize video plans on unseen goals in the RT-X, enables successful robot execution in simulation, and substantially outperforms monolithic baseline approaches to video generation.
Instruct-Imagen: Image Generation with Multi-modal Instruction
Jan 03, 2024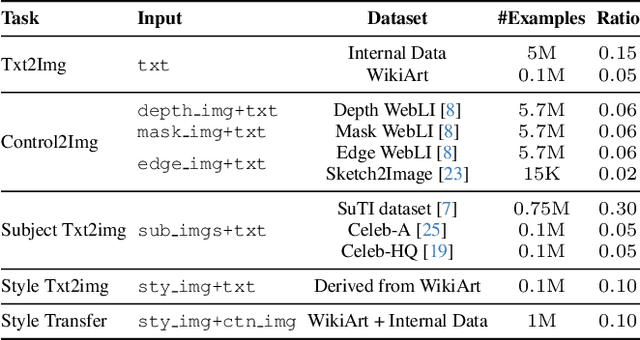

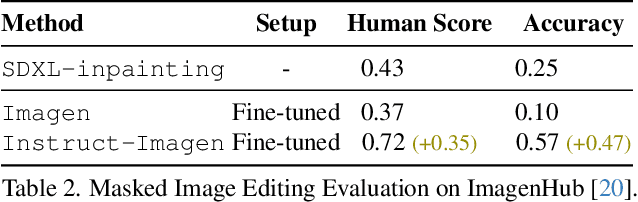
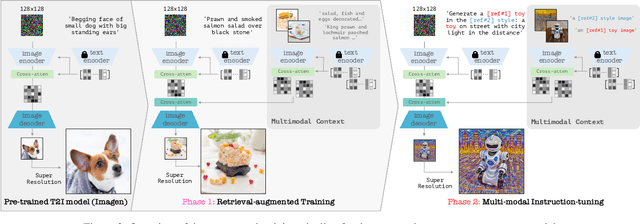
This paper presents instruct-imagen, a model that tackles heterogeneous image generation tasks and generalizes across unseen tasks. We introduce *multi-modal instruction* for image generation, a task representation articulating a range of generation intents with precision. It uses natural language to amalgamate disparate modalities (e.g., text, edge, style, subject, etc.), such that abundant generation intents can be standardized in a uniform format. We then build instruct-imagen by fine-tuning a pre-trained text-to-image diffusion model with a two-stage framework. First, we adapt the model using the retrieval-augmented training, to enhance model's capabilities to ground its generation on external multimodal context. Subsequently, we fine-tune the adapted model on diverse image generation tasks that requires vision-language understanding (e.g., subject-driven generation, etc.), each paired with a multi-modal instruction encapsulating the task's essence. Human evaluation on various image generation datasets reveals that instruct-imagen matches or surpasses prior task-specific models in-domain and demonstrates promising generalization to unseen and more complex tasks.
DreamInpainter: Text-Guided Subject-Driven Image Inpainting with Diffusion Models
Dec 05, 2023
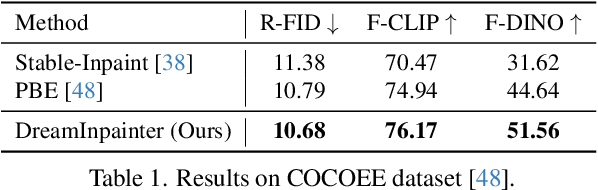

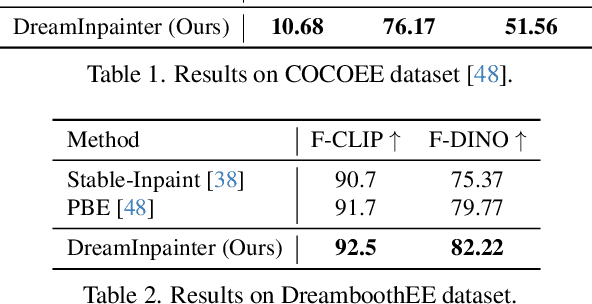
This study introduces Text-Guided Subject-Driven Image Inpainting, a novel task that combines text and exemplar images for image inpainting. While both text and exemplar images have been used independently in previous efforts, their combined utilization remains unexplored. Simultaneously accommodating both conditions poses a significant challenge due to the inherent balance required between editability and subject fidelity. To tackle this challenge, we propose a two-step approach DreamInpainter. First, we compute dense subject features to ensure accurate subject replication. Then, we employ a discriminative token selection module to eliminate redundant subject details, preserving the subject's identity while allowing changes according to other conditions such as mask shape and text prompts. Additionally, we introduce a decoupling regularization technique to enhance text control in the presence of exemplar images. Our extensive experiments demonstrate the superior performance of our method in terms of visual quality, identity preservation, and text control, showcasing its effectiveness in the context of text-guided subject-driven image inpainting.
Identity Encoder for Personalized Diffusion
Apr 14, 2023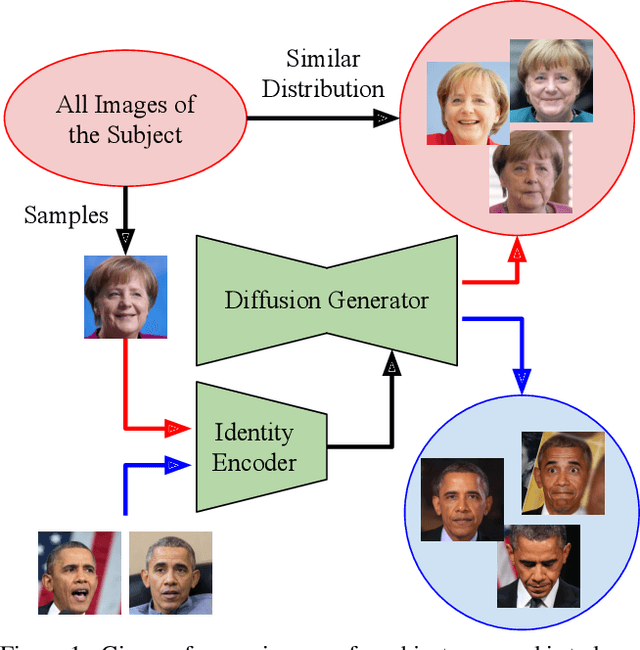
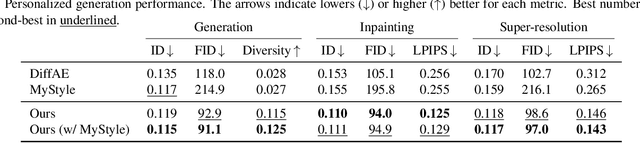
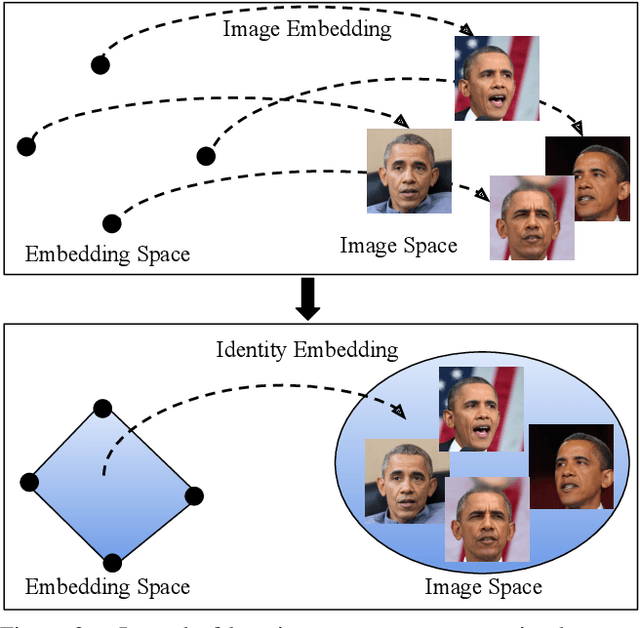
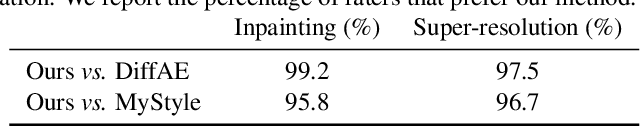
Many applications can benefit from personalized image generation models, including image enhancement, video conferences, just to name a few. Existing works achieved personalization by fine-tuning one model for each person. While being successful, this approach incurs additional computation and storage overhead for each new identity. Furthermore, it usually expects tens or hundreds of examples per identity to achieve the best performance. To overcome these challenges, we propose an encoder-based approach for personalization. We learn an identity encoder which can extract an identity representation from a set of reference images of a subject, together with a diffusion generator that can generate new images of the subject conditioned on the identity representation. Once being trained, the model can be used to generate images of arbitrary identities given a few examples even if the model hasn't been trained on the identity. Our approach greatly reduces the overhead for personalized image generation and is more applicable in many potential applications. Empirical results show that our approach consistently outperforms existing fine-tuning based approach in both image generation and reconstruction, and the outputs is preferred by users more than 95% of the time compared with the best performing baseline.