 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Text-to-Image Diffusion Transformers with Representation Autoencoders
Jan 22, 2026Representation Autoencoders (RAEs) have shown distinct advantages in diffusion modeling on ImageNet by training in high-dimensional semantic latent spaces. In this work, we investigate whether this framework can scale to large-scale, freeform text-to-image (T2I) generation. We first scale RAE decoders on the frozen representation encoder (SigLIP-2) beyond ImageNet by training on web, synthetic, and text-rendering data, finding that while scale improves general fidelity, targeted data composition is essential for specific domains like text. We then rigorously stress-test the RAE design choices originally proposed for ImageNet. Our analysis reveals that scaling simplifies the framework: while dimension-dependent noise scheduling remains critical, architectural complexities such as wide diffusion heads and noise-augmented decoding offer negligible benefits at scale Building on this simplified framework, we conduct a controlled comparison of RAE against the state-of-the-art FLUX VAE across diffusion transformer scales from 0.5B to 9.8B parameters. RAEs consistently outperform VAEs during pretraining across all model scales. Further, during finetuning on high-quality datasets, VAE-based models catastrophically overfit after 64 epochs, while RAE models remain stable through 256 epochs and achieve consistently better performance. Across all experiments, RAE-based diffusion models demonstrate faster convergence and better generation quality, establishing RAEs as a simpler and stronger foundation than VAEs for large-scale T2I generation. Additionally, because both visual understanding and generation can operate in a shared representation space, the multimodal model can directly reason over generated latents, opening new possibilities for unified models.
Transition Matching Distillation for Fast Video Generation
Jan 14, 2026Large video diffusion and flow models have achieved remarkable success in high-quality video generation, but their use in real-time interactive applications remains limited due to their inefficient multi-step sampling process. In this work, we present Transition Matching Distillation (TMD), a novel framework for distilling video diffusion models into efficient few-step generators. The central idea of TMD is to match the multi-step denoising trajectory of a diffusion model with a few-step probability transition process, where each transition is modeled as a lightweight conditional flow. To enable efficient distillation, we decompose the original diffusion backbone into two components: (1) a main backbone, comprising the majority of early layers, that extracts semantic representations at each outer transition step; and (2) a flow head, consisting of the last few layers, that leverages these representations to perform multiple inner flow updates. Given a pretrained video diffusion model, we first introduce a flow head to the model, and adapt it into a conditional flow map. We then apply distribution matching distillation to the student model with flow head rollout in each transition step. Extensive experiments on distilling Wan2.1 1.3B and 14B text-to-video models demonstrate that TMD provides a flexible and strong trade-off between generation speed and visual quality. In particular, TMD outperforms existing distilled models under comparable inference costs in terms of visual fidelity and prompt adherence. Project page: https://research.nvidia.com/labs/genair/tmd
Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps
Jan 16, 2025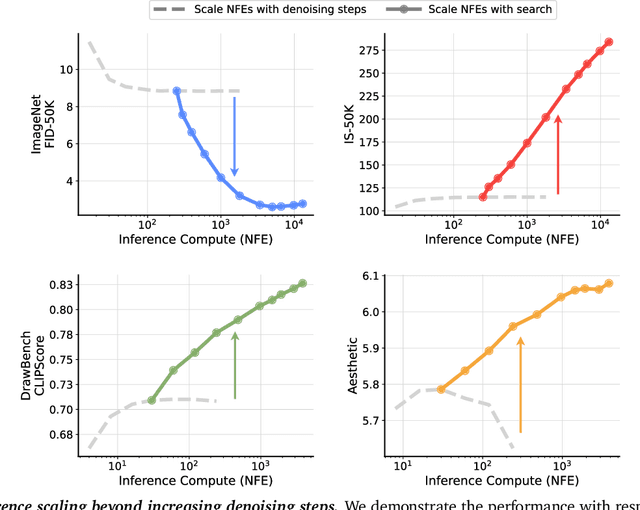
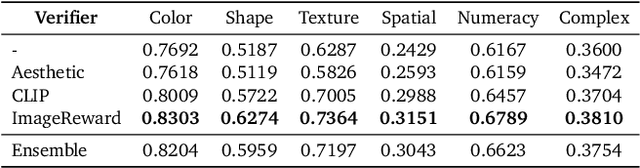
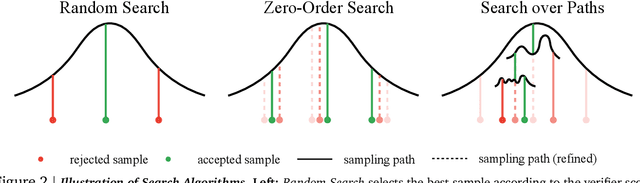
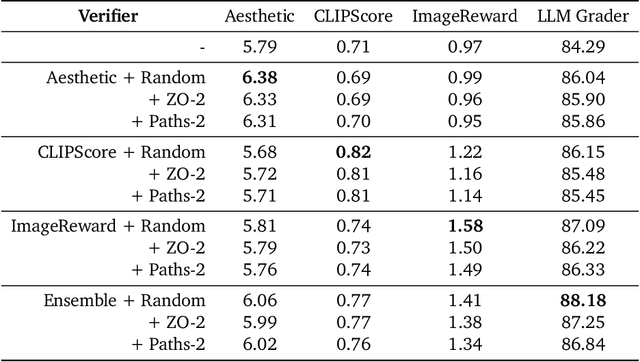
Generative models have made significant impacts across various domains, largely due to their ability to scale during training by increasing data, computational resources, and model size, a phenomenon characterized by the scaling laws. Recent research has begun to explore inference-time scaling behavior in Large Language Models (LLMs), revealing how performance can further improve with additional computation during inference. Unlike LLMs, diffusion models inherently possess the flexibility to adjust inference-time computation via the number of denoising steps, although the performance gains typically flatten after a few dozen. In this work, we explore the inference-time scaling behavior of diffusion models beyond increasing denoising steps and investigate how the generation performance can further improve with increased computation. Specifically, we consider a search problem aimed at identifying better noises for the diffusion sampling process. We structure the design space along two axes: the verifiers used to provide feedback, and the algorithms used to find better noise candidates. Through extensive experiments on class-conditioned and text-conditioned image generation benchmarks, our findings reveal that increasing inference-time compute leads to substantial improvements in the quality of samples generated by diffusion models, and with the complicated nature of images, combinations of the components in the framework can be specifically chosen to conform with different application scenario.
SiT: Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers
Jan 16, 2024We present Scalable Interpolant Transformers (SiT), a family of generative models built on the backbone of Diffusion Transformers (DiT). The interpolant framework, which allows for connecting two distributions in a more flexible way than standard diffusion models, makes possible a modular study of various design choices impacting generative models built on dynamical transport: using discrete vs. continuous time learning, deciding the objective for the model to learn, choosing the interpolant connecting the distributions, and deploying a deterministic or stochastic sampler. By carefully introducing the above ingredients, SiT surpasses DiT uniformly across model sizes on the conditional ImageNet 256x256 benchmark using the exact same backbone, number of parameters, and GFLOPs. By exploring various diffusion coefficients, which can be tuned separately from learning, SiT achieves an FID-50K score of 2.06.