 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Flow Maps enable scalable reward alignment
Jan 20, 2026Controlling generative models is computationally expensive. This is because optimal alignment with a reward function--whether via inference-time steering or fine-tuning--requires estimating the value function. This task demands access to the conditional posterior $p_{1|t}(x_1|x_t)$, the distribution of clean data $x_1$ consistent with an intermediate state $x_t$, a requirement that typically compels methods to resort to costly trajectory simulations. To address this bottleneck, we introduce Meta Flow Maps (MFMs), a framework extending consistency models and flow maps into the stochastic regime. MFMs are trained to perform stochastic one-step posterior sampling, generating arbitrarily many i.i.d. draws of clean data $x_1$ from any intermediate state. Crucially, these samples provide a differentiable reparametrization that unlocks efficient value function estimation. We leverage this capability to solve bottlenecks in both paradigms: enabling inference-time steering without inner rollouts, and facilitating unbiased, off-policy fine-tuning to general rewards. Empirically, our single-particle steered-MFM sampler outperforms a Best-of-1000 baseline on ImageNet across multiple rewards at a fraction of the compute.
Tilt Matching for Scalable Sampling and Fine-Tuning
Dec 26, 2025We propose a simple, scalable algorithm for using stochastic interpolants to sample from unnormalized densities and for fine-tuning generative models. The approach, Tilt Matching, arises from a dynamical equation relating the flow matching velocity to one targeting the same distribution tilted by a reward, implicitly solving a stochastic optimal control problem. The new velocity inherits the regularity of stochastic interpolant transports while also being the minimizer of an objective with strictly lower variance than flow matching itself. The update to the velocity field can be interpreted as the sum of all joint cumulants of the stochastic interpolant and copies of the reward, and to first order is their covariance. The algorithms do not require any access to gradients of the reward or backpropagating through trajectories of the flow or diffusion. We empirically verify that the approach is efficient and highly scalable, providing state-of-the-art results on sampling under Lennard-Jones potentials and is competitive on fine-tuning Stable Diffusion, without requiring reward multipliers. It can also be straightforwardly applied to tilting few-step flow map models.
Generalised Flow Maps for Few-Step Generative Modelling on Riemannian Manifolds
Oct 24, 2025Geometric data and purpose-built generative models on them have become ubiquitous in high-impact deep learning application domains, ranging from protein backbone generation and computational chemistry to geospatial data. Current geometric generative models remain computationally expensive at inference -- requiring many steps of complex numerical simulation -- as they are derived from dynamical measure transport frameworks such as diffusion and flow-matching on Riemannian manifolds. In this paper, we propose Generalised Flow Maps (GFM), a new class of few-step generative models that generalises the Flow Map framework in Euclidean spaces to arbitrary Riemannian manifolds. We instantiate GFMs with three self-distillation-based training methods: Generalised Lagrangian Flow Maps, Generalised Eulerian Flow Maps, and Generalised Progressive Flow Maps. We theoretically show that GFMs, under specific design decisions, unify and elevate existing Euclidean few-step generative models, such as consistency models, shortcut models, and meanflows, to the Riemannian setting. We benchmark GFMs against other geometric generative models on a suite of geometric datasets, including geospatial data, RNA torsion angles, and hyperbolic manifolds, and achieve state-of-the-art sample quality for single- and few-step evaluations, and superior or competitive log-likelihoods using the implicit probability flow.
Multitask Learning with Stochastic Interpolants
Aug 06, 2025We propose a framework for learning maps between probability distributions that broadly generalizes the time dynamics of flow and diffusion models. To enable this, we generalize stochastic interpolants by replacing the scalar time variable with vectors, matrices, or linear operators, allowing us to bridge probability distributions across multiple dimensional spaces. This approach enables the construction of versatile generative models capable of fulfilling multiple tasks without task-specific training. Our operator-based interpolants not only provide a unifying theoretical perspective for existing generative models but also extend their capabilities. Through numerical experiments, we demonstrate the zero-shot efficacy of our method on conditional generation and inpainting, fine-tuning and posterior sampling, and multiscale modeling, suggesting its potential as a generic task-agnostic alternative to specialized models.
How to build a consistency model: Learning flow maps via self-distillation
May 24, 2025Building on the framework proposed in Boffi et al. (2024), we present a systematic approach for learning flow maps associated with flow and diffusion models. Flow map-based models, commonly known as consistency models, encompass recent efforts to improve the efficiency of generative models based on solutions to differential equations. By exploiting a relationship between the velocity field underlying a continuous-time flow and the instantaneous rate of change of the flow map, we show how to convert existing distillation schemes into direct training algorithms via self-distillation, eliminating the need for pre-trained models. We empirically evaluate several instantiations of our framework, finding that high-dimensional tasks like image synthesis benefit from objective functions that avoid temporal and spatial derivatives of the flow map, while lower-dimensional tasks can benefit from objectives incorporating higher-order derivatives to capture sharp features.
NETS: A Non-Equilibrium Transport Sampler
Oct 03, 2024We propose an algorithm, termed the Non-Equilibrium Transport Sampler (NETS), to sample from unnormalized probability distributions. NETS can be viewed as a variant of annealed importance sampling (AIS) based on Jarzynski's equality, in which the stochastic differential equation used to perform the non-equilibrium sampling is augmented with an additional learned drift term that lowers the impact of the unbiasing weights used in AIS. We show that this drift is the minimizer of a variety of objective functions, which can all be estimated in an unbiased fashion without backpropagating through solutions of the stochastic differential equations governing the sampling. We also prove that some these objectives control the Kullback-Leibler divergence of the estimated distribution from its target. NETS is shown to be unbiased and, in addition, has a tunable diffusion coefficient which can be adjusted post-training to maximize the effective sample size. We demonstrate the efficacy of the method on standard benchmarks, high-dimensional Gaussian mixture distributions, and a model from statistical lattice field theory, for which it surpasses the performances of related work and existing baselines.
Flow Map Matching
Jun 11, 2024Generative models based on dynamical transport of measure, such as diffusion models, flow matching models, and stochastic interpolants, learn an ordinary or stochastic differential equation whose trajectories push initial conditions from a known base distribution onto the target. While training is cheap, samples are generated via simulation, which is more expensive than one-step models like GANs. To close this gap, we introduce flow map matching -- an algorithm that learns the two-time flow map of an underlying ordinary differential equation. The approach leads to an efficient few-step generative model whose step count can be chosen a-posteriori to smoothly trade off accuracy for computational expense. Leveraging the stochastic interpolant framework, we introduce losses for both direct training of flow maps and distillation from pre-trained (or otherwise known) velocity fields. Theoretically, we show that our approach unifies many existing few-step generative models, including consistency models, consistency trajectory models, progressive distillation, and neural operator approaches, which can be obtained as particular cases of our formalism. With experiments on CIFAR-10 and ImageNet 32x32, we show that flow map matching leads to high-quality samples with significantly reduced sampling cost compared to diffusion or stochastic interpolant methods.
Practical applications of machine-learned flows on gauge fields
Apr 17, 2024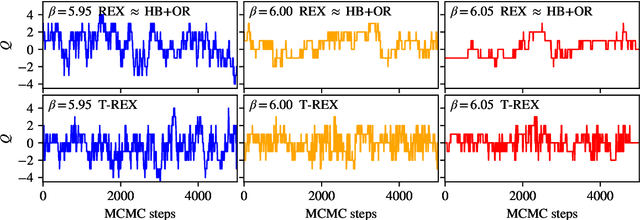
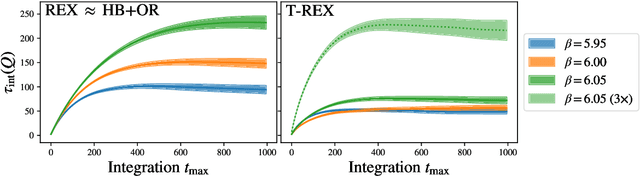
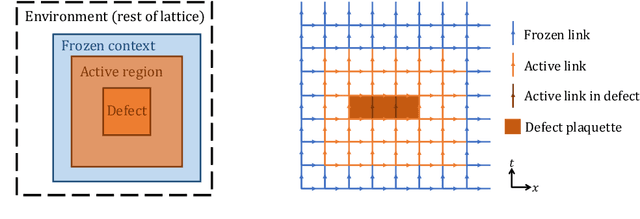
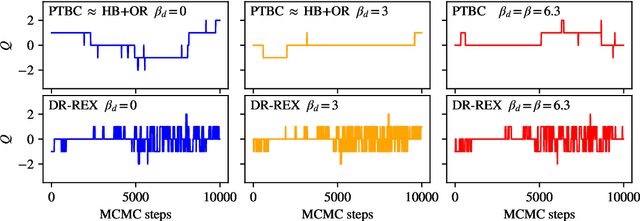
Normalizing flows are machine-learned maps between different lattice theories which can be used as components in exact sampling and inference schemes. Ongoing work yields increasingly expressive flows on gauge fields, but it remains an open question how flows can improve lattice QCD at state-of-the-art scales. We discuss and demonstrate two applications of flows in replica exchange (parallel tempering) sampling, aimed at improving topological mixing, which are viable with iterative improvements upon presently available flows.
Probabilistic Forecasting with Stochastic Interpolants and Föllmer Processes
Mar 20, 2024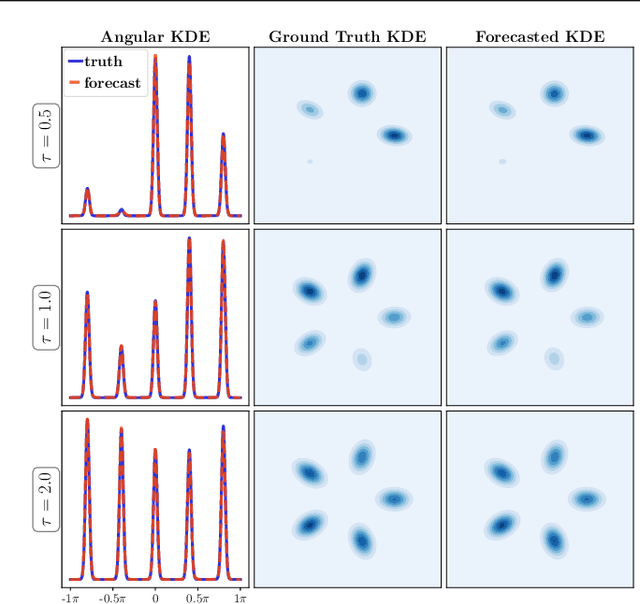
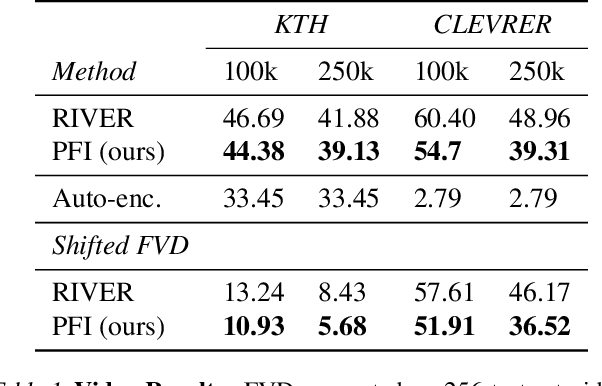

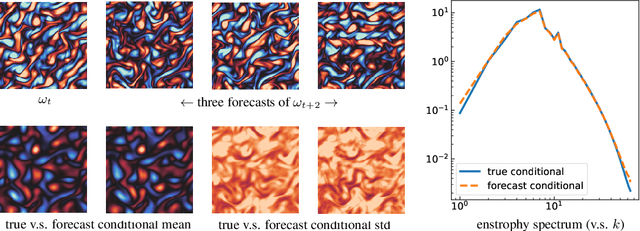
We propose a framework for probabilistic forecasting of dynamical systems based on generative modeling. Given observations of the system state over time, we formulate the forecasting problem as sampling from the conditional distribution of the future system state given its current state. To this end, we leverage the framework of stochastic interpolants, which facilitates the construction of a generative model between an arbitrary base distribution and the target. We design a fictitious, non-physical stochastic dynamics that takes as initial condition the current system state and produces as output a sample from the target conditional distribution in finite time and without bias. This process therefore maps a point mass centered at the current state onto a probabilistic ensemble of forecasts. We prove that the drift coefficient entering the stochastic differential equation (SDE) achieving this task is non-singular, and that it can be learned efficiently by square loss regression over the time-series data. We show that the drift and the diffusion coefficients of this SDE can be adjusted after training, and that a specific choice that minimizes the impact of the estimation error gives a F\"ollmer process. We highlight the utility of our approach on several complex, high-dimensional forecasting problems, including stochastically forced Navier-Stokes and video prediction on the KTH and CLEVRER datasets.
SiT: Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers
Jan 16, 2024We present Scalable Interpolant Transformers (SiT), a family of generative models built on the backbone of Diffusion Transformers (DiT). The interpolant framework, which allows for connecting two distributions in a more flexible way than standard diffusion models, makes possible a modular study of various design choices impacting generative models built on dynamical transport: using discrete vs. continuous time learning, deciding the objective for the model to learn, choosing the interpolant connecting the distributions, and deploying a deterministic or stochastic sampler. By carefully introducing the above ingredients, SiT surpasses DiT uniformly across model sizes on the conditional ImageNet 256x256 benchmark using the exact same backbone, number of parameters, and GFLOPs. By exploring various diffusion coefficients, which can be tuned separately from learning, SiT achieves an FID-50K score of 2.06.