 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Normalizing flows for lattice gauge theory in arbitrary space-time dimension
May 03, 2023



Applications of normalizing flows to the sampling of field configurations in lattice gauge theory have so far been explored almost exclusively in two space-time dimensions. We report new algorithmic developments of gauge-equivariant flow architectures facilitating the generalization to higher-dimensional lattice geometries. Specifically, we discuss masked autoregressive transformations with tractable and unbiased Jacobian determinants, a key ingredient for scalable and asymptotically exact flow-based sampling algorithms. For concreteness, results from a proof-of-principle application to SU(3) lattice gauge theory in four space-time dimensions are reported.
Aspects of scaling and scalability for flow-based sampling of lattice QCD
Nov 14, 2022Recent applications of machine-learned normalizing flows to sampling in lattice field theory suggest that such methods may be able to mitigate critical slowing down and topological freezing. However, these demonstrations have been at the scale of toy models, and it remains to be determined whether they can be applied to state-of-the-art lattice quantum chromodynamics calculations. Assessing the viability of sampling algorithms for lattice field theory at scale has traditionally been accomplished using simple cost scaling laws, but as we discuss in this work, their utility is limited for flow-based approaches. We conclude that flow-based approaches to sampling are better thought of as a broad family of algorithms with different scaling properties, and that scalability must be assessed experimentally.
A Generalist Agent
May 19, 2022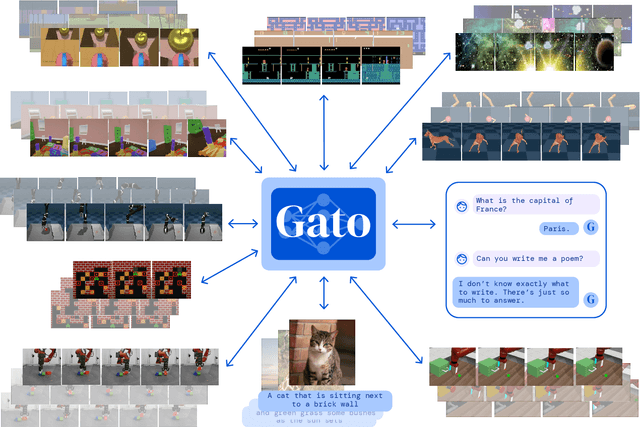
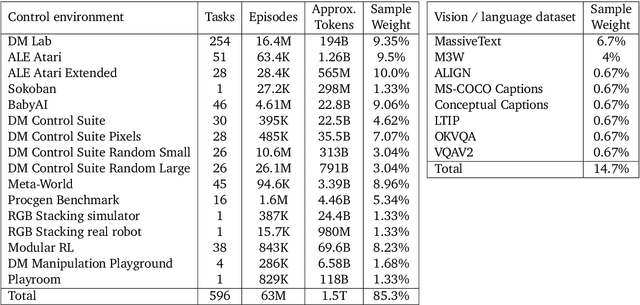
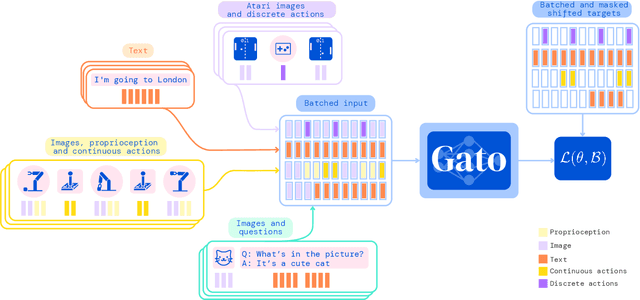

Inspired by progress in large-scale language modeling, we apply a similar approach towards building a single generalist agent beyond the realm of text outputs. The agent, which we refer to as Gato, works as a multi-modal, multi-task, multi-embodiment generalist policy. The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens. In this report we describe the model and the data, and document the current capabilities of Gato.
Vector Quantized Models for Planning
Jun 10, 2021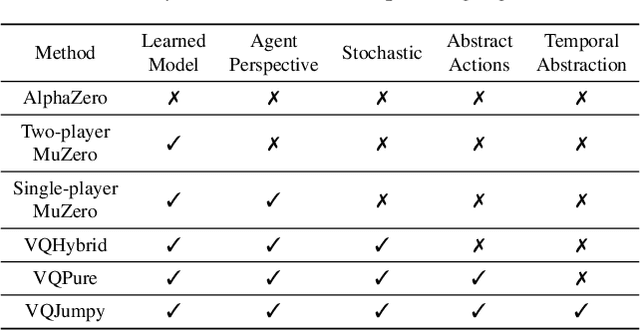
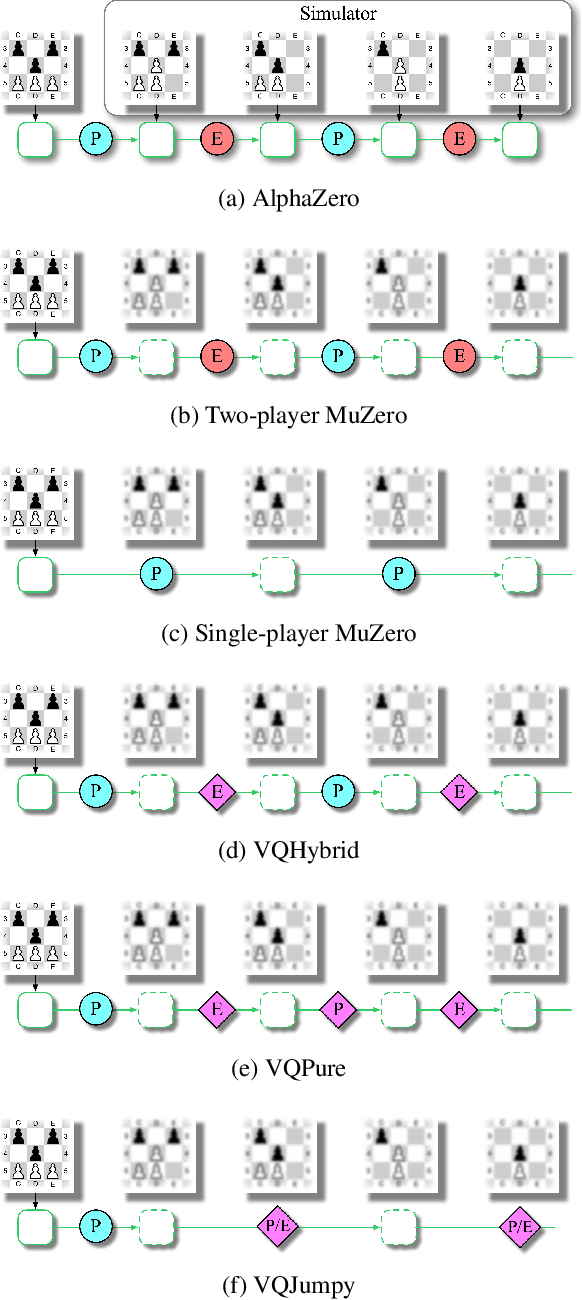
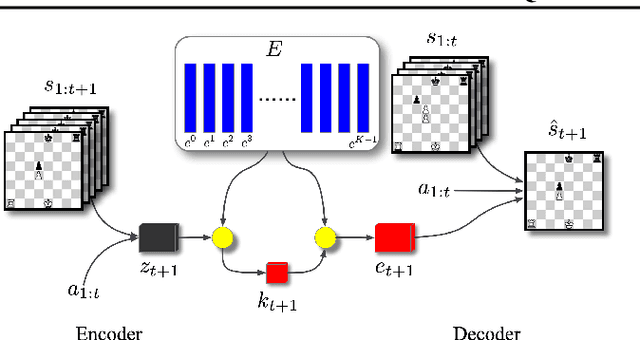
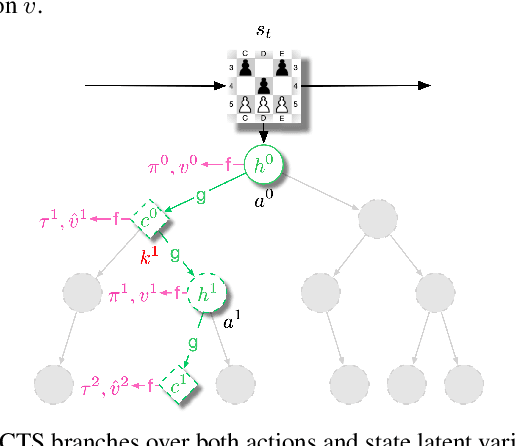
Recent developments in the field of model-based RL have proven successful in a range of environments, especially ones where planning is essential. However, such successes have been limited to deterministic fully-observed environments. We present a new approach that handles stochastic and partially-observable environments. Our key insight is to use discrete autoencoders to capture the multiple possible effects of an action in a stochastic environment. We use a stochastic variant of Monte Carlo tree search to plan over both the agent's actions and the discrete latent variables representing the environment's response. Our approach significantly outperforms an offline version of MuZero on a stochastic interpretation of chess where the opponent is considered part of the environment. We also show that our approach scales to DeepMind Lab, a first-person 3D environment with large visual observations and partial observability.
Predicting Video with VQVAE
Mar 02, 2021
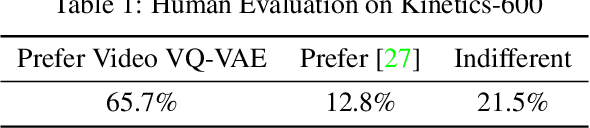


In recent years, the task of video prediction-forecasting future video given past video frames-has attracted attention in the research community. In this paper we propose a novel approach to this problem with Vector Quantized Variational AutoEncoders (VQ-VAE). With VQ-VAE we compress high-resolution videos into a hierarchical set of multi-scale discrete latent variables. Compared to pixels, this compressed latent space has dramatically reduced dimensionality, allowing us to apply scalable autoregressive generative models to predict video. In contrast to previous work that has largely emphasized highly constrained datasets, we focus on very diverse, large-scale datasets such as Kinetics-600. We predict video at a higher resolution on unconstrained videos, 256x256, than any other previous method to our knowledge. We further validate our approach against prior work via a crowdsourced human evaluation.
Do Transformers Need Deep Long-Range Memory
Jul 07, 2020
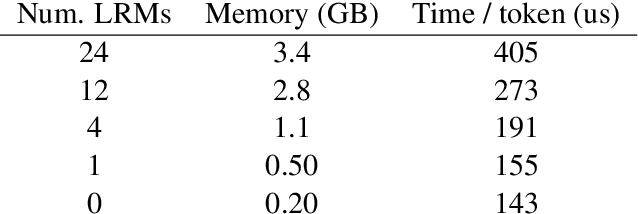


Deep attention models have advanced the modelling of sequential data across many domains. For language modelling in particular, the Transformer-XL -- a Transformer augmented with a long-range memory of past activations -- has been shown to be state-of-the-art across a variety of well-studied benchmarks. The Transformer-XL incorporates a long-range memory at every layer of the network, which renders its state to be thousands of times larger than RNN predecessors. However it is unclear whether this is necessary. We perform a set of interventions to show that comparable performance can be obtained with 6X fewer long range memories and better performance can be obtained by limiting the range of attention in lower layers of the network.
Generating Diverse High-Fidelity Images with VQ-VAE-2
Jun 02, 2019



We explore the use of Vector Quantized Variational AutoEncoder (VQ-VAE) models for large scale image generation. To this end, we scale and enhance the autoregressive priors used in VQ-VAE to generate synthetic samples of much higher coherence and fidelity than possible before. We use simple feed-forward encoder and decoder networks, making our model an attractive candidate for applications where the encoding and/or decoding speed is critical. Additionally, VQ-VAE requires sampling an autoregressive model only in the compressed latent space, which is an order of magnitude faster than sampling in the pixel space, especially for large images. We demonstrate that a multi-scale hierarchical organization of VQ-VAE, augmented with powerful priors over the latent codes, is able to generate samples with quality that rivals that of state of the art Generative Adversarial Networks on multifaceted datasets such as ImageNet, while not suffering from GAN's known shortcomings such as mode collapse and lack of diversity.
Data-Efficient Image Recognition with Contrastive Predictive Coding
May 22, 2019



Large scale deep learning excels when labeled images are abundant, yet data-efficient learning remains a longstanding challenge. While biological vision is thought to leverage vast amounts of unlabeled data to solve classification problems with limited supervision, computer vision has so far not succeeded in this `semi-supervised' regime. Our work tackles this challenge with Contrastive Predictive Coding, an unsupervised objective which extracts stable structure from still images. The result is a representation which, equipped with a simple linear classifier, separates ImageNet categories better than all competing methods, and surpasses the performance of a fully-supervised AlexNet model. When given a small number of labeled images (as few as 13 per class), this representation retains a strong classification performance, outperforming state-of-the-art semi-supervised methods by 10% Top-5 accuracy and supervised methods by 20%. Finally, we find our unsupervised representation to serve as a useful substrate for image detection on the PASCAL-VOC 2007 dataset, approaching the performance of representations trained with a fully annotated ImageNet dataset. We expect these results to open the door to pipelines that use scalable unsupervised representations as a drop-in replacement for supervised ones for real-world vision tasks where labels are scarce.
Preventing Posterior Collapse with delta-VAEs
Jan 10, 2019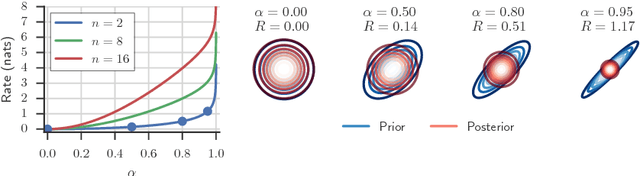
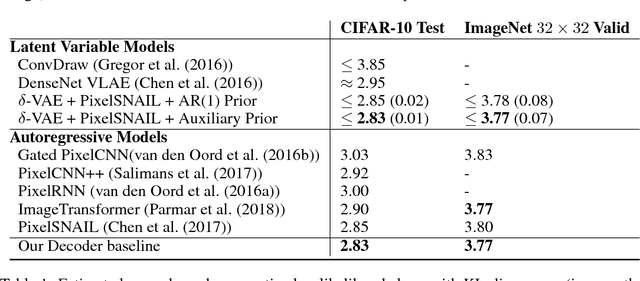
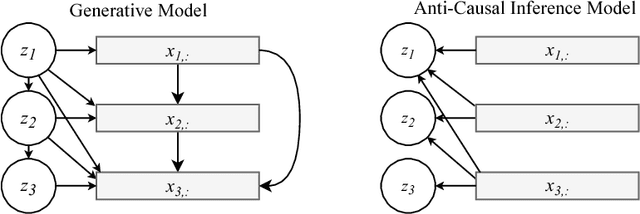

Due to the phenomenon of "posterior collapse," current latent variable generative models pose a challenging design choice that either weakens the capacity of the decoder or requires augmenting the objective so it does not only maximize the likelihood of the data. In this paper, we propose an alternative that utilizes the most powerful generative models as decoders, whilst optimising the variational lower bound all while ensuring that the latent variables preserve and encode useful information. Our proposed $\delta$-VAEs achieve this by constraining the variational family for the posterior to have a minimum distance to the prior. For sequential latent variable models, our approach resembles the classic representation learning approach of slow feature analysis. We demonstrate the efficacy of our approach at modeling text on LM1B and modeling images: learning representations, improving sample quality, and achieving state of the art log-likelihood on CIFAR-10 and ImageNet $32\times 32$.