 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dialogue between Causal and Traditional Representation Learning: Toward Mutual Benefits in a Unified Formulation
May 20, 2026Causal representation learning (CRL) and traditional representation learning have largely developed along different trajectories. Traditional representation learning has been driven mainly by applications and empirical objectives, whereas CRL has focused more on theoretical questions, particularly identifiability. This difference in emphasis has created a gap between the two fields in terminology, problem formulation, and evaluation, limiting communication and sometimes leading to disconnected or redundant efforts. In this paper, we argue that these two fields should be brought into dialogue rather than treated as separate paradigms. To this end, we introduce a unified formulation in which the representation learning is characterized by two components: a task component, which specifies what information the learned representation is required to preserve, and a constraint component, which specifies what structure is imposed on the latent space. Under this formulation, the benefits run in both directions. CRL provides theoretical tools for understanding when structured latent constraints are useful or necessary, while traditional representation learning offers practical insights on task design and objective choice that can improve the development of CRL methods. To illustrate this interaction, we experimentally study how different task components affect the behavior of CRL methods under different structured constraints. Results on CausalVerse show that the effectiveness of causal constraints depends strongly on the tasks with which they are paired.
From Generalist to Specialist Representation
May 12, 2026Given a generalist model, learning a task-relevant specialist representation is fundamental for downstream applications. Identifiability, the asymptotic guarantee of recovering the ground-truth representation, is critical because it sets the ultimate limit of any model, even with infinite data and computation. We study this problem in a completely nonparametric setting, without relying on interventions, parametric forms, or structural constraints. We first prove that the structure between time steps and tasks is identifiable in a fully unsupervised manner, even when sequences lack strict temporal dependence and may exhibit disconnections, and task assignments can follow arbitrarily complex and interleaving structures. We then prove that, within each time step, the task-relevant latent representation can be disentangled from the irrelevant part under a simple sparsity regularization, without any additional information or parametric constraints. Together, these results establish a hierarchical foundation: task structure is identifiable across time steps, and task-relevant latent representations are identifiable within each step. To our knowledge, each result provides a first general nonparametric identifiability guarantee, and together they mark a step toward provably moving from generalist to specialist models.
Causal Representation Learning from General Environments under Nonparametric Mixing
Apr 26, 2026Causal representation learning aims to recover the latent causal variables and their causal relations, typically represented by directed acyclic graphs (DAGs), from low-level observations such as image pixels. A prevailing line of research exploits multiple environments, which assume how data distributions change, including single-node interventions, coupled interventions, or hard interventions, or parametric constraints on the mixing function or the latent causal model, such as linearity. Despite the novelty and elegance of the results, they are often violated in real problems. Accordingly, we formalize a set of desiderata for causal representation learning that applies to a broader class of environments, referred to as general environments. Interestingly, we show that one can fully recover the latent DAG and identify the latent variables up to minor indeterminacies under a nonparametric mixing function and nonlinear latent causal models, such as additive (Gaussian) noise models or heteroscedastic noise models, by properly leveraging sufficient change conditions on the causal mechanisms up to third-order derivatives. These represent, to our knowledge, the first results to fully recover the latent DAG from general environments under nonparametric mixing. Notably, our results match or improve upon many existing works, but require less restrictive assumptions about changing environments.
SEDGE: Structural Extrapolated Data Generation
Apr 02, 2026This paper proposes a framework for Structural Extrapolated Data GEneration (SEDGE) based on suitable assumptions on the underlying data generating process. We provide conditions under which data satisfying new specifications can be generated reliably, together with the approximate identifiability of the distribution of such data under certain ``conservative" assumptions. On the algorithmic side, we develop practical methods to achieve extrapolated data generation, based on the structure-informed optimization strategy or diffusion posterior sampling, respectively. We verify the extrapolation performance on synthetic data and also consider extrapolated image generation as a real-world scenario to illustrate the validity of the proposed framework.
Beyond the Black Box: Identifiable Interpretation and Control in Generative Models via Causal Minimality
Dec 11, 2025Deep generative models, while revolutionizing fields like image and text generation, largely operate as opaque black boxes, hindering human understanding, control, and alignment. While methods like sparse autoencoders (SAEs) show remarkable empirical success, they often lack theoretical guarantees, risking subjective insights. Our primary objective is to establish a principled foundation for interpretable generative models. We demonstrate that the principle of causal minimality -- favoring the simplest causal explanation -- can endow the latent representations of diffusion vision and autoregressive language models with clear causal interpretation and robust, component-wise identifiable control. We introduce a novel theoretical framework for hierarchical selection models, where higher-level concepts emerge from the constrained composition of lower-level variables, better capturing the complex dependencies in data generation. Under theoretically derived minimality conditions (manifesting as sparsity or compression constraints), we show that learned representations can be equivalent to the true latent variables of the data-generating process. Empirically, applying these constraints to leading generative models allows us to extract their innate hierarchical concept graphs, offering fresh insights into their internal knowledge organization. Furthermore, these causally grounded concepts serve as levers for fine-grained model steering, paving the way for transparent, reliable systems.
Learning by Analogy: A Causal Framework for Composition Generalization
Dec 11, 2025Compositional generalization -- the ability to understand and generate novel combinations of learned concepts -- enables models to extend their capabilities beyond limited experiences. While effective, the data structures and principles that enable this crucial capability remain poorly understood. We propose that compositional generalization fundamentally requires decomposing high-level concepts into basic, low-level concepts that can be recombined across similar contexts, similar to how humans draw analogies between concepts. For example, someone who has never seen a peacock eating rice can envision this scene by relating it to their previous observations of a chicken eating rice. In this work, we formalize these intuitive processes using principles of causal modularity and minimal changes. We introduce a hierarchical data-generating process that naturally encodes different levels of concepts and their interaction mechanisms. Theoretically, we demonstrate that this approach enables compositional generalization supporting complex relations between composed concepts, advancing beyond prior work that assumes simpler interactions like additive effects. Critically, we also prove that this latent hierarchical structure is provably recoverable (identifiable) from observable data like text-image pairs, a necessary step for learning such a generative process. To validate our theory, we apply insights from our theoretical framework and achieve significant improvements on benchmark datasets.
Step-Aware Policy Optimization for Reasoning in Diffusion Large Language Models
Oct 02, 2025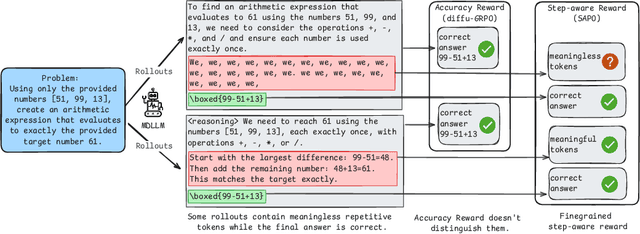
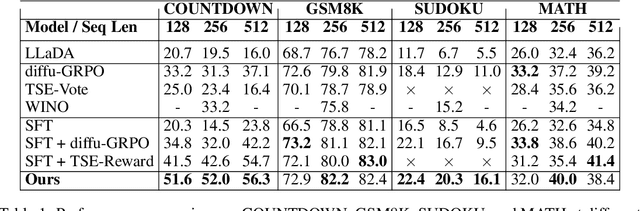
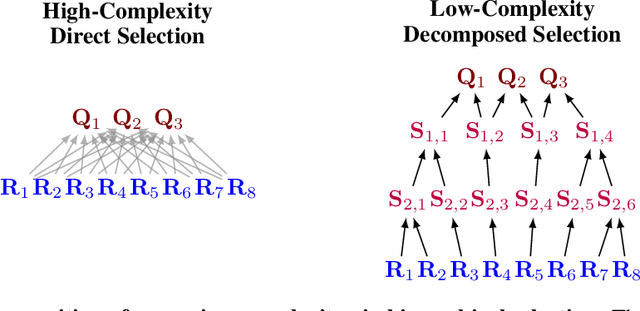
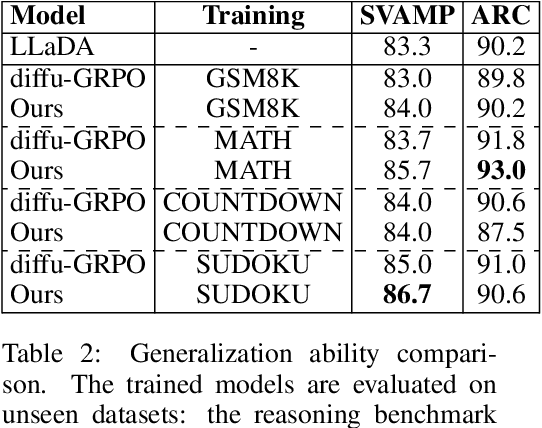
Diffusion language models (dLLMs) offer a promising, non-autoregressive paradigm for text generation, yet training them for complex reasoning remains a key challenge. Current reinforcement learning approaches often rely on sparse, outcome-based rewards, which can reinforce flawed reasoning paths that lead to coincidentally correct answers. We argue that this stems from a fundamental mismatch with the natural structure of reasoning. We first propose a theoretical framework that formalizes complex problem solving as a hierarchical selection process, where an intractable global constraint is decomposed into a series of simpler, localized logical steps. This framework provides a principled foundation for algorithm design, including theoretical insights into the identifiability of this latent reasoning structure. Motivated by this theory, we identify unstructured refinement -- a failure mode where a model's iterative steps do not contribute meaningfully to the solution -- as a core deficiency in existing methods. We then introduce Step-Aware Policy Optimization (SAPO), a novel RL algorithm that aligns the dLLM's denoising process with the latent reasoning hierarchy. By using a process-based reward function that encourages incremental progress, SAPO guides the model to learn structured, coherent reasoning paths. Our empirical results show that this principled approach significantly improves performance on challenging reasoning benchmarks and enhances the interpretability of the generation process.
SmartCLIP: Modular Vision-language Alignment with Identification Guarantees
Jul 29, 2025
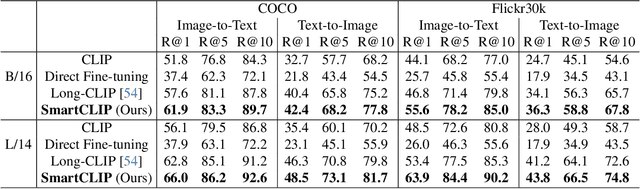
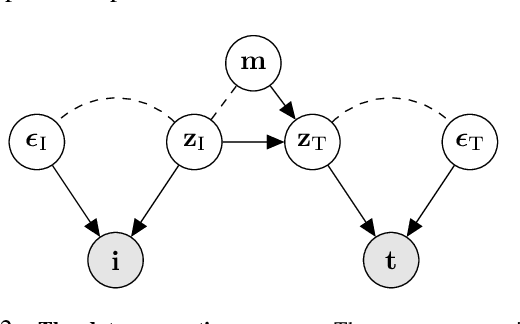
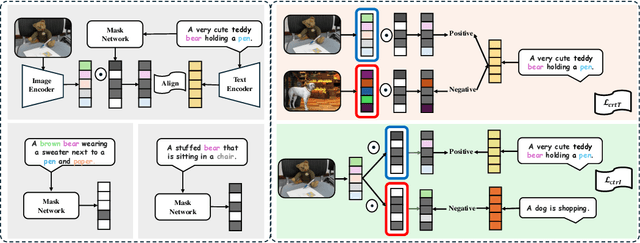
Contrastive Language-Image Pre-training (CLIP)~\citep{radford2021learning} has emerged as a pivotal model in computer vision and multimodal learning, achieving state-of-the-art performance at aligning visual and textual representations through contrastive learning. However, CLIP struggles with potential information misalignment in many image-text datasets and suffers from entangled representation. On the one hand, short captions for a single image in datasets like MSCOCO may describe disjoint regions in the image, leaving the model uncertain about which visual features to retain or disregard. On the other hand, directly aligning long captions with images can lead to the retention of entangled details, preventing the model from learning disentangled, atomic concepts -- ultimately limiting its generalization on certain downstream tasks involving short prompts. In this paper, we establish theoretical conditions that enable flexible alignment between textual and visual representations across varying levels of granularity. Specifically, our framework ensures that a model can not only \emph{preserve} cross-modal semantic information in its entirety but also \emph{disentangle} visual representations to capture fine-grained textual concepts. Building on this foundation, we introduce \ours, a novel approach that identifies and aligns the most relevant visual and textual representations in a modular manner. Superior performance across various tasks demonstrates its capability to handle information misalignment and supports our identification theory. The code is available at https://github.com/Mid-Push/SmartCLIP.
Controllable Video Generation with Provable Disentanglement
Feb 04, 2025



Controllable video generation remains a significant challenge, despite recent advances in generating high-quality and consistent videos. Most existing methods for controlling video generation treat the video as a whole, neglecting intricate fine-grained spatiotemporal relationships, which limits both control precision and efficiency. In this paper, we propose Controllable Video Generative Adversarial Networks (CoVoGAN) to disentangle the video concepts, thus facilitating efficient and independent control over individual concepts. Specifically, following the minimal change principle, we first disentangle static and dynamic latent variables. We then leverage the sufficient change property to achieve component-wise identifiability of dynamic latent variables, enabling independent control over motion and identity. To establish the theoretical foundation, we provide a rigorous analysis demonstrating the identifiability of our approach. Building on these theoretical insights, we design a Temporal Transition Module to disentangle latent dynamics. To enforce the minimal change principle and sufficient change property, we minimize the dimensionality of latent dynamic variables and impose temporal conditional independence. To validate our approach, we integrate this module as a plug-in for GANs. Extensive qualitative and quantitative experiments on various video generation benchmarks demonstrate that our method significantly improves generation quality and controllability across diverse real-world scenarios.
Causal Representation Learning from Multiple Distributions: A General Setting
Feb 07, 2024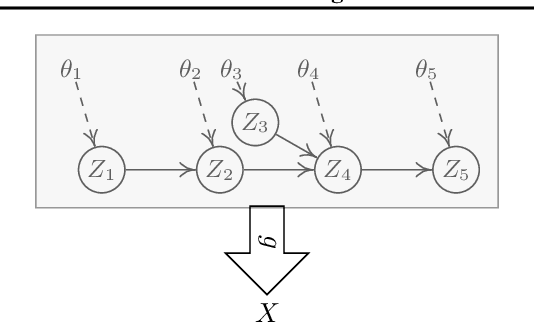
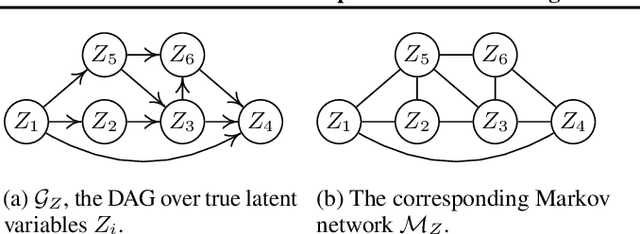
In many problems, the measured variables (e.g., image pixels) are just mathematical functions of the hidden causal variables (e.g., the underlying concepts or objects). For the purpose of making predictions in changing environments or making proper changes to the system, it is helpful to recover the hidden causal variables $Z_i$ and their causal relations represented by graph $\mathcal{G}_Z$. This problem has recently been known as causal representation learning. This paper is concerned with a general, completely nonparametric setting of causal representation learning from multiple distributions (arising from heterogeneous data or nonstationary time series), without assuming hard interventions behind distribution changes. We aim to develop general solutions in this fundamental case; as a by product, this helps see the unique benefit offered by other assumptions such as parametric causal models or hard interventions. We show that under the sparsity constraint on the recovered graph over the latent variables and suitable sufficient change conditions on the causal influences, interestingly, one can recover the moralized graph of the underlying directed acyclic graph, and the recovered latent variables and their relations are related to the underlying causal model in a specific, nontrivial way. In some cases, each latent variable can even be recovered up to component-wise transformations. Experimental results verify our theoretical claims.