 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlug-and-Play Spiking Operators: Breaking the Nonlinearity Bottleneck in Spiking Transformers
May 19, 2026ANN-to-SNN conversion offers a practical, training-free route to spiking large language models. However, current pipelines primarily focus on spike-driven realizations for Transformer linear-algebra operations, while providing limited support for key nonlinear operators. This gap limits compatibility with neuromorphic-style execution constraints, where such nonlinearities typically require division, exponentiation, or norm computations that are not naturally supported by standard leaky integrate-and-fire dynamics. To solve this problem, we propose a plug-and-play framework that implements spike-friendly approximations for Transformer nonlinearities and integrates into existing ANN-to-SNN pipelines. Our method decomposes these nonlinear computations into three recurring primitives -- division, exponentiation, and $\ell_2$ norms -- and realizes them via population computation using LIF neuron groups, combined with lightweight bit-shift scaling to avoid floating-point arithmetic. By composing these primitives as modular operator blocks, our framework supports common Transformer nonlinearities (e.g., Softmax, SiLU, and normalization) without any fine-tuning. Experiments on a range of LLMs Transformers show that selectively replacing the targeted nonlinear operators incurs less than a $1\%$ accuracy drop across all evaluated tasks.
S2MAM: Semi-supervised Meta Additive Model for Robust Estimation and Variable Selection
Apr 21, 2026Semi-supervised learning with manifold regularization is a classical framework for jointly learning from both labeled and unlabeled data, where the key requirement is that the support of the unknown marginal distribution has the geometric structure of a Riemannian manifold. Typically, the Laplace-Beltrami operator-based manifold regularization can be approximated empirically by the Laplacian regularization associated with the entire training data and its corresponding graph Laplacian matrix. However, the graph Laplacian matrix depends heavily on the prespecified similarity metric and may lead to inappropriate penalties when dealing with redundant or noisy input variables. To address the above issues, this paper proposes a new \textit{Semi-Supervised Meta Additive Model (S$^2$MAM) based on a bilevel optimization scheme that automatically identifies informative variables, updates the similarity matrix, and simultaneously achieves interpretable predictions. Theoretical guarantees are provided for S$^2$MAM, including the computing convergence and the statistical generalization bound. Experimental assessments across 4 synthetic and 12 real-world datasets, with varying levels and categories of corruption, validate the robustness and interpretability of the proposed approach.
FedOne: Query-Efficient Federated Learning for Black-box Discrete Prompt Learning
Jun 17, 2025

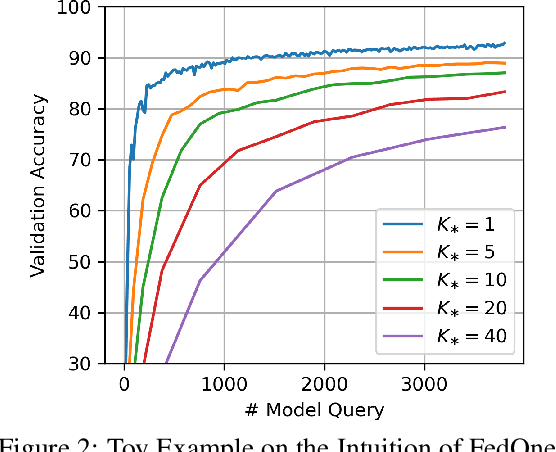

Black-Box Discrete Prompt Learning is a prompt-tuning method that optimizes discrete prompts without accessing model parameters or gradients, making the prompt tuning on a cloud-based Large Language Model (LLM) feasible. Adapting federated learning to BDPL could further enhance prompt tuning performance by leveraging data from diverse sources. However, all previous research on federated black-box prompt tuning had neglected the substantial query cost associated with the cloud-based LLM service. To address this gap, we conducted a theoretical analysis of query efficiency within the context of federated black-box prompt tuning. Our findings revealed that degrading FedAvg to activate only one client per round, a strategy we called \textit{FedOne}, enabled optimal query efficiency in federated black-box prompt learning. Building on this insight, we proposed the FedOne framework, a federated black-box discrete prompt learning method designed to maximize query efficiency when interacting with cloud-based LLMs. We conducted numerical experiments on various aspects of our framework, demonstrating a significant improvement in query efficiency, which aligns with our theoretical results.
* Published in Proceedings of the 42nd International Conference on Machine Learning
Event-Driven Online Vertical Federated Learning
Jun 17, 2025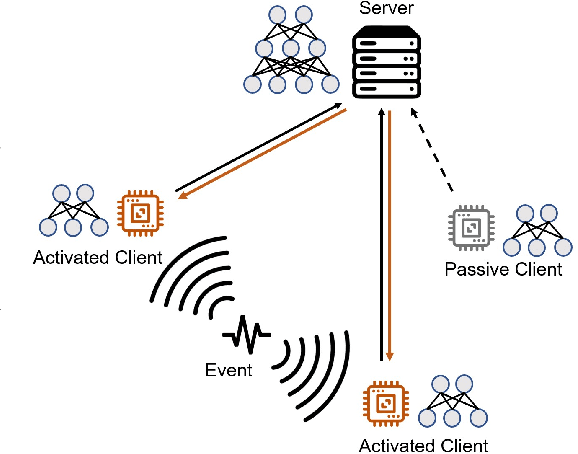



Online learning is more adaptable to real-world scenarios in Vertical Federated Learning (VFL) compared to offline learning. However, integrating online learning into VFL presents challenges due to the unique nature of VFL, where clients possess non-intersecting feature sets for the same sample. In real-world scenarios, the clients may not receive data streaming for the disjoint features for the same entity synchronously. Instead, the data are typically generated by an \emph{event} relevant to only a subset of clients. We are the first to identify these challenges in online VFL, which have been overlooked by previous research. To address these challenges, we proposed an event-driven online VFL framework. In this framework, only a subset of clients were activated during each event, while the remaining clients passively collaborated in the learning process. Furthermore, we incorporated \emph{dynamic local regret (DLR)} into VFL to address the challenges posed by online learning problems with non-convex models within a non-stationary environment. We conducted a comprehensive regret analysis of our proposed framework, specifically examining the DLR under non-convex conditions with event-driven online VFL. Extensive experiments demonstrated that our proposed framework was more stable than the existing online VFL framework under non-stationary data conditions while also significantly reducing communication and computation costs.
* Published as a conference paper at ICLR 2025
Optimization over Sparse Support-Preserving Sets: Two-Step Projection with Global Optimality Guarantees
Jun 11, 2025In sparse optimization, enforcing hard constraints using the $\ell_0$ pseudo-norm offers advantages like controlled sparsity compared to convex relaxations. However, many real-world applications demand not only sparsity constraints but also some extra constraints. While prior algorithms have been developed to address this complex scenario with mixed combinatorial and convex constraints, they typically require the closed form projection onto the mixed constraints which might not exist, and/or only provide local guarantees of convergence which is different from the global guarantees commonly sought in sparse optimization. To fill this gap, in this paper, we study the problem of sparse optimization with extra support-preserving constraints commonly encountered in the literature. We present a new variant of iterative hard-thresholding algorithm equipped with a two-step consecutive projection operator customized for these mixed constraints, serving as a simple alternative to the Euclidean projection onto the mixed constraint. By introducing a novel trade-off between sparsity relaxation and sub-optimality, we provide global guarantees in objective value for the output of our algorithm, in the deterministic, stochastic, and zeroth-order settings, under the conventional restricted strong-convexity/smoothness assumptions. As a fundamental contribution in proof techniques, we develop a novel extension of the classic three-point lemma to the considered two-step non-convex projection operator, which allows us to analyze the convergence in objective value in an elegant way that has not been possible with existing techniques. In the zeroth-order case, such technique also improves upon the state-of-the-art result from de Vazelhes et. al. (2022), even in the case without additional constraints, by allowing us to remove a non-vanishing system error present in their work.
Temporal Misalignment in ANN-SNN Conversion and Its Mitigation via Probabilistic Spiking Neurons
Feb 21, 2025Spiking Neural Networks (SNNs) offer a more energy-efficient alternative to Artificial Neural Networks (ANNs) by mimicking biological neural principles, establishing them as a promising approach to mitigate the increasing energy demands of large-scale neural models. However, fully harnessing the capabilities of SNNs remains challenging due to their discrete signal processing and temporal dynamics. ANN-SNN conversion has emerged as a practical approach, enabling SNNs to achieve competitive performance on complex machine learning tasks. In this work, we identify a phenomenon in the ANN-SNN conversion framework, termed temporal misalignment, in which random spike rearrangement across SNN layers leads to performance improvements. Based on this observation, we introduce biologically plausible two-phase probabilistic (TPP) spiking neurons, further enhancing the conversion process. We demonstrate the advantages of our proposed method both theoretically and empirically through comprehensive experiments on CIFAR-10/100, CIFAR10-DVS, and ImageNet across a variety of architectures, achieving state-of-the-art results.
Arabic Dataset for LLM Safeguard Evaluation
Oct 22, 2024The growing use of large language models (LLMs) has raised concerns regarding their safety. While many studies have focused on English, the safety of LLMs in Arabic, with its linguistic and cultural complexities, remains under-explored. Here, we aim to bridge this gap. In particular, we present an Arab-region-specific safety evaluation dataset consisting of 5,799 questions, including direct attacks, indirect attacks, and harmless requests with sensitive words, adapted to reflect the socio-cultural context of the Arab world. To uncover the impact of different stances in handling sensitive and controversial topics, we propose a dual-perspective evaluation framework. It assesses the LLM responses from both governmental and opposition viewpoints. Experiments over five leading Arabic-centric and multilingual LLMs reveal substantial disparities in their safety performance. This reinforces the need for culturally specific datasets to ensure the responsible deployment of LLMs.
Obtaining Lower Query Complexities through Lightweight Zeroth-Order Proximal Gradient Algorithms
Oct 03, 2024Zeroth-order (ZO) optimization is one key technique for machine learning problems where gradient calculation is expensive or impossible. Several variance reduced ZO proximal algorithms have been proposed to speed up ZO optimization for non-smooth problems, and all of them opted for the coordinated ZO estimator against the random ZO estimator when approximating the true gradient, since the former is more accurate. While the random ZO estimator introduces bigger error and makes convergence analysis more challenging compared to coordinated ZO estimator, it requires only $\mathcal{O}(1)$ computation, which is significantly less than $\mathcal{O}(d)$ computation of the coordinated ZO estimator, with $d$ being dimension of the problem space. To take advantage of the computationally efficient nature of the random ZO estimator, we first propose a ZO objective decrease (ZOOD) property which can incorporate two different types of errors in the upper bound of convergence rate. Next, we propose two generic reduction frameworks for ZO optimization which can automatically derive the convergence results for convex and non-convex problems respectively, as long as the convergence rate for the inner solver satisfies the ZOOD property. With the application of two reduction frameworks on our proposed ZOR-ProxSVRG and ZOR-ProxSAGA, two variance reduced ZO proximal algorithms with fully random ZO estimators, we improve the state-of-the-art function query complexities from $\mathcal{O}\left(\min\{\frac{dn^{1/2}}{\epsilon^2}, \frac{d}{\epsilon^3}\}\right)$ to $\tilde{\mathcal{O}}\left(\frac{n+d}{\epsilon^2}\right)$ under $d > n^{\frac{1}{2}}$ for non-convex problems, and from $\mathcal{O}\left(\frac{d}{\epsilon^2}\right)$ to $\tilde{\mathcal{O}}\left(n\log\frac{1}{\epsilon}+\frac{d}{\epsilon}\right)$ for convex problems.
* Neural Computation 36 (5), 897-935
Gradient-Free Method for Heavily Constrained Nonconvex Optimization
Aug 31, 2024



Zeroth-order (ZO) method has been shown to be a powerful method for solving the optimization problem where explicit expression of the gradients is difficult or infeasible to obtain. Recently, due to the practical value of the constrained problems, a lot of ZO Frank-Wolfe or projected ZO methods have been proposed. However, in many applications, we may have a very large number of nonconvex white/black-box constraints, which makes the existing zeroth-order methods extremely inefficient (or even not working) since they need to inquire function value of all the constraints and project the solution to the complicated feasible set. In this paper, to solve the nonconvex problem with a large number of white/black-box constraints, we proposed a doubly stochastic zeroth-order gradient method (DSZOG) with momentum method and adaptive step size. Theoretically, we prove DSZOG can converge to the $\epsilon$-stationary point of the constrained problem. Experimental results in two applications demonstrate the superiority of our method in terms of training time and accuracy compared with other ZO methods for the constrained problem.
* 21 page, 12 figures, conference
Double Momentum Method for Lower-Level Constrained Bilevel Optimization
Jun 25, 2024Bilevel optimization (BO) has recently gained prominence in many machine learning applications due to its ability to capture the nested structure inherent in these problems. Recently, many hypergradient methods have been proposed as effective solutions for solving large-scale problems. However, current hypergradient methods for the lower-level constrained bilevel optimization (LCBO) problems need very restrictive assumptions, namely, where optimality conditions satisfy the differentiability and invertibility conditions and lack a solid analysis of the convergence rate. What's worse, existing methods require either double-loop updates, which are sometimes less efficient. To solve this problem, in this paper, we propose a new hypergradient of LCBO leveraging the theory of nonsmooth implicit function theorem instead of using the restrive assumptions. In addition, we propose a \textit{single-loop single-timescale} algorithm based on the double-momentum method and adaptive step size method and prove it can return a $(\delta, \epsilon)$-stationary point with $\tilde{\mathcal{O}}(d_2^2\epsilon^{-4})$ iterations. Experiments on two applications demonstrate the effectiveness of our proposed method.