 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Free Method for Heavily Constrained Nonconvex Optimization
Aug 31, 2024



Zeroth-order (ZO) method has been shown to be a powerful method for solving the optimization problem where explicit expression of the gradients is difficult or infeasible to obtain. Recently, due to the practical value of the constrained problems, a lot of ZO Frank-Wolfe or projected ZO methods have been proposed. However, in many applications, we may have a very large number of nonconvex white/black-box constraints, which makes the existing zeroth-order methods extremely inefficient (or even not working) since they need to inquire function value of all the constraints and project the solution to the complicated feasible set. In this paper, to solve the nonconvex problem with a large number of white/black-box constraints, we proposed a doubly stochastic zeroth-order gradient method (DSZOG) with momentum method and adaptive step size. Theoretically, we prove DSZOG can converge to the $\epsilon$-stationary point of the constrained problem. Experimental results in two applications demonstrate the superiority of our method in terms of training time and accuracy compared with other ZO methods for the constrained problem.
* 21 page, 12 figures, conference
Double Momentum Method for Lower-Level Constrained Bilevel Optimization
Jun 25, 2024Bilevel optimization (BO) has recently gained prominence in many machine learning applications due to its ability to capture the nested structure inherent in these problems. Recently, many hypergradient methods have been proposed as effective solutions for solving large-scale problems. However, current hypergradient methods for the lower-level constrained bilevel optimization (LCBO) problems need very restrictive assumptions, namely, where optimality conditions satisfy the differentiability and invertibility conditions and lack a solid analysis of the convergence rate. What's worse, existing methods require either double-loop updates, which are sometimes less efficient. To solve this problem, in this paper, we propose a new hypergradient of LCBO leveraging the theory of nonsmooth implicit function theorem instead of using the restrive assumptions. In addition, we propose a \textit{single-loop single-timescale} algorithm based on the double-momentum method and adaptive step size method and prove it can return a $(\delta, \epsilon)$-stationary point with $\tilde{\mathcal{O}}(d_2^2\epsilon^{-4})$ iterations. Experiments on two applications demonstrate the effectiveness of our proposed method.
Quadruply Stochastic Gradient Method for Large Scale Nonlinear Semi-Supervised Ordinal Regression AUC Optimization
Dec 24, 2019
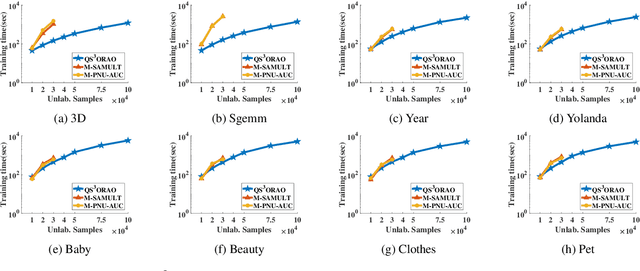
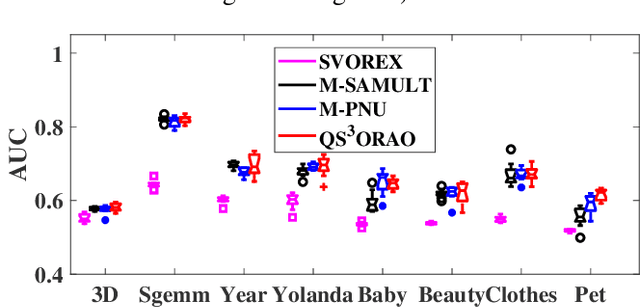
Semi-supervised ordinal regression (S$^2$OR) problems are ubiquitous in real-world applications, where only a few ordered instances are labeled and massive instances remain unlabeled. Recent researches have shown that directly optimizing concordance index or AUC can impose a better ranking on the data than optimizing the traditional error rate in ordinal regression (OR) problems. In this paper, we propose an unbiased objective function for S$^2$OR AUC optimization based on ordinal binary decomposition approach. Besides, to handle the large-scale kernelized learning problems, we propose a scalable algorithm called QS$^3$ORAO using the doubly stochastic gradients (DSG) framework for functional optimization. Theoretically, we prove that our method can converge to the optimal solution at the rate of $O(1/t)$, where $t$ is the number of iterations for stochastic data sampling. Extensive experimental results on various benchmark and real-world datasets also demonstrate that our method is efficient and effective while retaining similar generalization performance.
Quadruply Stochastic Gradients for Large Scale Nonlinear Semi-Supervised AUC Optimization
Jul 29, 2019
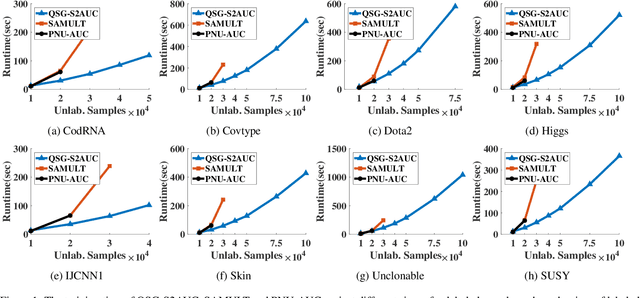


Semi-supervised learning is pervasive in real-world applications, where only a few labeled data are available and large amounts of instances remain unlabeled. Since AUC is an important model evaluation metric in classification, directly optimizing AUC in semi-supervised learning scenario has drawn much attention in the machine learning community. Recently, it has been shown that one could find an unbiased solution for the semi-supervised AUC maximization problem without knowing the class prior distribution. However, this method is hardly scalable for nonlinear classification problems with kernels. To address this problem, in this paper, we propose a novel scalable quadruply stochastic gradient algorithm (QSG-S2AUC) for nonlinear semi-supervised AUC optimization. In each iteration of the stochastic optimization process, our method randomly samples a positive instance, a negative instance, an unlabeled instance and their random features to compute the gradient and then update the model by using this quadruply stochastic gradient to approach the optimal solution. More importantly, we prove that QSG-S2AUC can converge to the optimal solution in O(1/t), where t is the iteration number. Extensive experimental results on a variety of benchmark datasets show that QSG-S2AUC is far more efficient than the existing state-of-the-art algorithms for semi-supervised AUC maximization while retaining the similar generalization performance.
Scalable Semi-Supervised SVM via Triply Stochastic Gradients
Jul 26, 2019


Semi-supervised learning (SSL) plays an increasingly important role in the big data era because a large number of unlabeled samples can be used effectively to improve the performance of the classifier. Semi-supervised support vector machine (S$^3$VM) is one of the most appealing methods for SSL, but scaling up S$^3$VM for kernel learning is still an open problem. Recently, a doubly stochastic gradient (DSG) algorithm has been proposed to achieve efficient and scalable training for kernel methods. However, the algorithm and theoretical analysis of DSG are developed based on the convexity assumption which makes them incompetent for non-convex problems such as S$^3$VM. To address this problem, in this paper, we propose a triply stochastic gradient algorithm for S$^3$VM, called TSGS$^3$VM. Specifically, to handle two types of data instances involved in S$^3$VM, TSGS$^3$VM samples a labeled instance and an unlabeled instance as well with the random features in each iteration to compute a triply stochastic gradient. We use the approximated gradient to update the solution. More importantly, we establish new theoretic analysis for TSGS$^3$VM which guarantees that TSGS$^3$VM can converge to a stationary point. Extensive experimental results on a variety of datasets demonstrate that TSGS$^3$VM is much more efficient and scalable than existing S$^3$VM algorithms.