 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Mathematical Reasoning Adaptive
Oct 06, 2025



Mathematical reasoning is a primary indicator of large language models (LLMs) intelligence. However, existing LLMs exhibit failures of robustness and generalization. This paper attributes these deficiencies to spurious reasoning, i.e., producing answers from superficial features. To address this challenge, we propose the AdaR framework to enable adaptive reasoning, wherein models rely on problem-solving logic to produce answers. AdaR synthesizes logically equivalent queries by varying variable values, and trains models with RLVR on these data to penalize spurious logic while encouraging adaptive logic. To improve data quality, we extract the problem-solving logic from the original query and generate the corresponding answer by code execution, then apply a sanity check. Experimental results demonstrate that AdaR improves robustness and generalization, achieving substantial improvement in mathematical reasoning while maintaining high data efficiency. Analysis indicates that data synthesis and RLVR function in a coordinated manner to enable adaptive reasoning in LLMs. Subsequent analyses derive key design insights into the effect of critical factors and the applicability to instruct LLMs. Our project is available at https://github.com/LaiZhejian/AdaR
Alleviating Distribution Shift in Synthetic Data for Machine Translation Quality Estimation
Feb 28, 2025Quality Estimation (QE) models evaluate the quality of machine translations without reference translations, serving as the reward models for the translation task. Due to the data scarcity, synthetic data generation has emerged as a promising solution. However, synthetic QE data often suffers from distribution shift, which can manifest as discrepancies between pseudo and real translations, or in pseudo labels that do not align with human preferences. To tackle this issue, we introduce ADSQE, a novel framework for alleviating distribution shift in synthetic QE data. To reduce the difference between pseudo and real translations, we employ the constrained beam search algorithm and enhance translation diversity through the use of distinct generation models. ADSQE uses references, i.e., translation supervision signals, to guide both the generation and annotation processes, enhancing the quality of word-level labels. ADSE further identifies the shortest phrase covering consecutive error tokens, mimicking human annotation behavior, to assign the final phrase-level labels. Specially, we underscore that the translation model can not annotate translations of itself accurately. Extensive experiments demonstrate that ADSQE outperforms SOTA baselines like COMET in both supervised and unsupervised settings. Further analysis offers insights into synthetic data generation that could benefit reward models for other tasks.
"I've Heard of You!": Generate Spoken Named Entity Recognition Data for Unseen Entities
Dec 26, 2024



Spoken named entity recognition (NER) aims to identify named entities from speech, playing an important role in speech processing. New named entities appear every day, however, annotating their Spoken NER data is costly. In this paper, we demonstrate that existing Spoken NER systems perform poorly when dealing with previously unseen named entities. To tackle this challenge, we propose a method for generating Spoken NER data based on a named entity dictionary (NED) to reduce costs. Specifically, we first use a large language model (LLM) to generate sentences from the sampled named entities and then use a text-to-speech (TTS) system to generate the speech. Furthermore, we introduce a noise metric to filter out noisy data. To evaluate our approach, we release a novel Spoken NER benchmark along with a corresponding NED containing 8,853 entities. Experiment results show that our method achieves state-of-the-art (SOTA) performance in the in-domain, zero-shot domain adaptation, and fully zero-shot settings. Our data will be available at https://github.com/DeepLearnXMU/HeardU.
Why Not Transform Chat Large Language Models to Non-English?
May 22, 2024
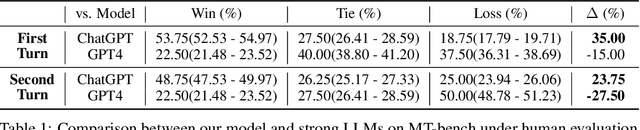


The scarcity of non-English data limits the development of non-English large language models (LLMs). Transforming English-centric LLMs to non-English has been identified as an effective and resource-efficient method. Previous works start from base LLMs and perform knowledge distillation (KD) with data generated by stronger LLMs, e.g. GPT-4. Compared to base LLMs, chat LLMs are further optimized for advanced abilities, e.g. multi-turn conversation and human preference alignment, and thus more powerful in both helpfulness and safety. However, transforming a chat LLM involves two critical issues: (1) How can we effectively transfer advanced abilities without their supervised data? (2) How can we prevent the original knowledge from catastrophic forgetting during transformation? We target these issues by introducing a simple framework called TransLLM. For the first issue, TransLLM divides the transfer problem into some common sub-tasks with the translation chain-of-thought, which uses the translation as the bridge between English and non-English step-by-step. We further enhance the performance of sub-tasks with publicly available data. For the second issue, we propose a method comprising two synergistic components: low-rank adaptation for training to maintain the original LLM parameters, and recovery KD, which utilizes data generated by the chat LLM itself to recover the original knowledge from the frozen parameters. In the experiments, we transform the LLaMA-2-chat-7B to the Thai language. Our method, using only single-turn data, outperforms strong baselines and ChatGPT on multi-turn benchmark MT-bench. Furthermore, our method, without safety data, rejects more harmful queries of safety benchmark AdvBench than both ChatGPT and GPT-4.
From Handcrafted Features to LLMs: A Brief Survey for Machine Translation Quality Estimation
Mar 21, 2024Machine Translation Quality Estimation (MTQE) is the task of estimating the quality of machine-translated text in real time without the need for reference translations, which is of great importance for the development of MT. After two decades of evolution, QE has yielded a wealth of results. This article provides a comprehensive overview of QE datasets, annotation methods, shared tasks, methodologies, challenges, and future research directions. It begins with an introduction to the background and significance of QE, followed by an explanation of the concepts and evaluation metrics for word-level QE, sentence-level QE, document-level QE, and explainable QE. The paper categorizes the methods developed throughout the history of QE into those based on handcrafted features, deep learning, and Large Language Models (LLMs), with a further division of deep learning-based methods into classic deep learning and those incorporating pre-trained language models (LMs). Additionally, the article details the advantages and limitations of each method and offers a straightforward comparison of different approaches. Finally, the paper discusses the current challenges in QE research and provides an outlook on future research directions.
Lost in the Source Language: How Large Language Models Evaluate the Quality of Machine Translation
Jan 12, 2024



Large Language Models (LLMs) have achieved remarkable results in the machine translation evaluation task, yet there remains a gap in knowledge regarding how they utilize the provided data to conduct evaluations. This study aims to explore how LLMs leverage source and reference information in evaluating translations, with the ultimate goal of better understanding the working mechanism of LLMs. To this end, we design the controlled experiments across various input modes and model types, and employ both coarse-grained and fine-grained prompts to discern the utility of source versus reference information. Surprisingly, we find that reference information significantly enhances the evaluation accuracy, while source information sometimes is counterproductive, indicating a lack of cross-lingual capability when using LLMs to evaluate translations. We further conduct a meta-evaluation for translation error detection of LLMs, observing a similar phenomenon. These findings also suggest a potential research direction for LLMs that fully exploits the cross-lingual capability of LLMs to achieve better performance in machine translation evaluation tasks.
MAPO: Advancing Multilingual Reasoning through Multilingual Alignment-as-Preference Optimization
Jan 12, 2024Though reasoning abilities are considered language-agnostic, existing LLMs exhibit inconsistent reasoning abilities across different languages, e.g., reasoning in a pivot language is superior to other languages due to the imbalance of multilingual training data.To enhance reasoning abilities in non-pivot languages, we propose an alignment-as-preference optimization framework. Specifically, we adopt an open-source translation model to estimate the consistency between answers in non-pivot and pivot languages. We further adopt the answer consistency as the preference for DPO or PPO thus optimizing the lesser reasoning. Experiments show that our method significantly improves the model's multilingual reasoning, with better reasoning consistency across languages. Our framework achieved a 13.7% accuracy improvement on out-of-domain datasets MSVAMP while preserving the competitive performance on MGSM. Moreover, we find that iterative DPO is helpful for further alignment and improvement of the model's multilingual mathematical reasoning ability, further pushing the improvement to 16.7%
NJUNLP's Participation for the WMT2023 Quality Estimation Shared Task
Sep 23, 2023We introduce the submissions of the NJUNLP team to the WMT 2023 Quality Estimation (QE) shared task. Our team submitted predictions for the English-German language pair on all two sub-tasks: (i) sentence- and word-level quality prediction; and (ii) fine-grained error span detection. This year, we further explore pseudo data methods for QE based on NJUQE framework (https://github.com/NJUNLP/njuqe). We generate pseudo MQM data using parallel data from the WMT translation task. We pre-train the XLMR large model on pseudo QE data, then fine-tune it on real QE data. At both stages, we jointly learn sentence-level scores and word-level tags. Empirically, we conduct experiments to find the key hyper-parameters that improve the performance. Technically, we propose a simple method that covert the word-level outputs to fine-grained error span results. Overall, our models achieved the best results in English-German for both word-level and fine-grained error span detection sub-tasks by a considerable margin.
CoP: Factual Inconsistency Detection by Controlling the Preference
Dec 03, 2022Abstractive summarization is the process of generating a summary given a document as input. Although significant progress has been made, the factual inconsistency between the document and the generated summary still limits its practical applications. Previous work found that the probabilities assigned by the generation model reflect its preferences for the generated summary, including the preference for factual consistency, and the preference for the language or knowledge prior as well. To separate the preference for factual consistency, we propose an unsupervised framework named CoP by controlling the preference of the generation model with the help of prompt. More specifically, the framework performs an extra inference step in which a text prompt is introduced as an additional input. In this way, another preference is described by the generation probability of this extra inference process. The difference between the above two preferences, i.e. the difference between the probabilities, could be used as measurements for detecting factual inconsistencies. Interestingly, we found that with the properly designed prompt, our framework could evaluate specific preferences and serve as measurements for fine-grained categories of inconsistency, such as entity-related inconsistency, coreference-related inconsistency, etc. Moreover, our framework could also be extended to the supervised setting to learn better prompt from the labeled data as well. Experiments show that our framework achieves new SOTA results on three factual inconsistency detection tasks.
DirectQE: Direct Pretraining for Machine Translation Quality Estimation
May 15, 2021
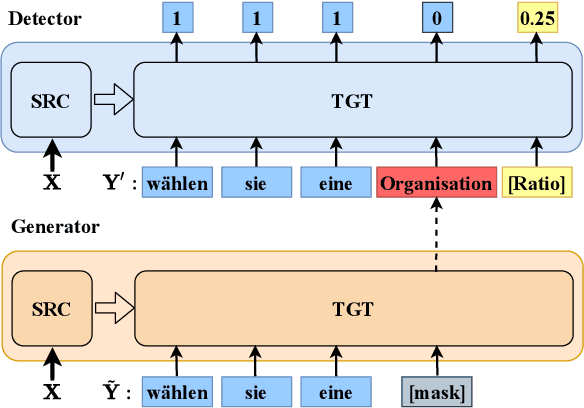
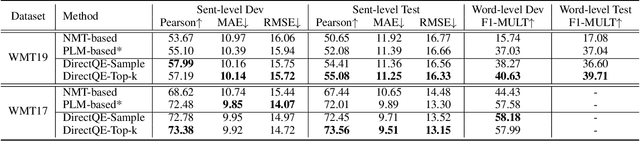
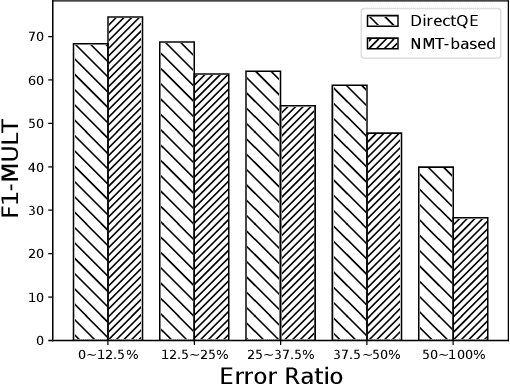
Machine Translation Quality Estimation (QE) is a task of predicting the quality of machine translations without relying on any reference. Recently, the predictor-estimator framework trains the predictor as a feature extractor, which leverages the extra parallel corpora without QE labels, achieving promising QE performance. However, we argue that there are gaps between the predictor and the estimator in both data quality and training objectives, which preclude QE models from benefiting from a large number of parallel corpora more directly. We propose a novel framework called DirectQE that provides a direct pretraining for QE tasks. In DirectQE, a generator is trained to produce pseudo data that is closer to the real QE data, and a detector is pretrained on these data with novel objectives that are akin to the QE task. Experiments on widely used benchmarks show that DirectQE outperforms existing methods, without using any pretraining models such as BERT. We also give extensive analyses showing how fixing the two gaps contributes to our improvements.