 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountering the Over-Reliance Trap: Mitigating Object Hallucination for LVLMs via a Self-Validation Framework
Jan 30, 2026Despite progress in Large Vision Language Models (LVLMs), object hallucination remains a critical issue in image captioning task, where models generate descriptions of non-existent objects, compromising their reliability. Previous work attributes this to LVLMs' over-reliance on language priors and attempts to mitigate it through logits calibration. However, they still lack a thorough analysis of the over-reliance. To gain a deeper understanding of over-reliance, we conduct a series of preliminary experiments, indicating that as the generation length increases, LVLMs' over-reliance on language priors leads to inflated probability of hallucinated object tokens, consequently exacerbating object hallucination. To circumvent this issue, we propose Language-Prior-Free Verification to enable LVLMs to faithfully verify the confidence of object existence. Based on this, we propose a novel training-free Self-Validation Framework to counter the over-reliance trap. It first validates objects' existence in sampled candidate captions and further mitigates object hallucination via caption selection or aggregation. Experiment results demonstrate that our framework mitigates object hallucination significantly in image captioning task (e.g., 65.6% improvement on CHAIRI metric with LLaVA-v1.5-7B), surpassing the previous SOTA methods. This result highlights a novel path towards mitigating hallucination by unlocking the inherent potential within LVLMs themselves.
Towards Fine-Grained Code-Switch Speech Translation with Semantic Space Alignment
Nov 09, 2025Code-switching (CS) speech translation (ST) refers to translating speech that alternates between two or more languages into a target language text, which poses significant challenges due to the complexity of semantic modeling and the scarcity of CS data. Previous studies tend to rely on the model itself to implicitly learn semantic modeling during training, and resort to inefficient and costly manual annotations for these two challenges. To mitigate these limitations, we propose enhancing Large Language Models (LLMs) with a Mixture of Experts (MoE) speech projector, where each expert specializes in the semantic subspace of a specific language, enabling fine-grained modeling of speech features. Additionally, we introduce a multi-stage training paradigm that utilizes readily available monolingual automatic speech recognition (ASR) and monolingual ST data, facilitating speech-text alignment and improving translation capabilities. During training, we leverage a combination of language-specific loss and intra-group load balancing loss to guide the MoE speech projector in efficiently allocating tokens to the appropriate experts, across expert groups and within each group, respectively. To bridge the data gap across different training stages and improve adaptation to the CS scenario, we further employ a transition loss, enabling smooth transitions of data between stages, to effectively address the scarcity of high-quality CS speech translation data. Extensive experiments on widely used datasets demonstrate the effectiveness and generality of our approach.
LLaVE: Large Language and Vision Embedding Models with Hardness-Weighted Contrastive Learning
Mar 04, 2025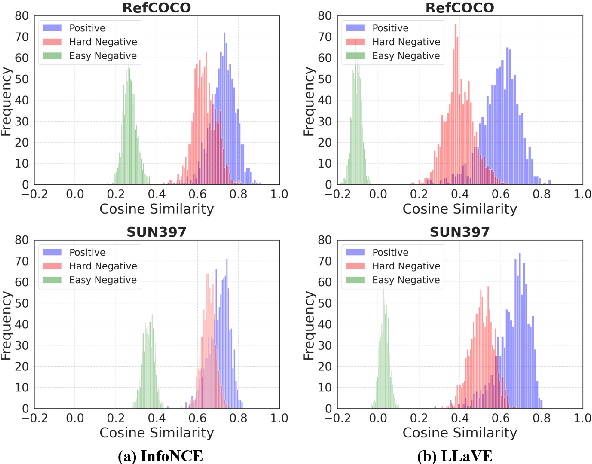
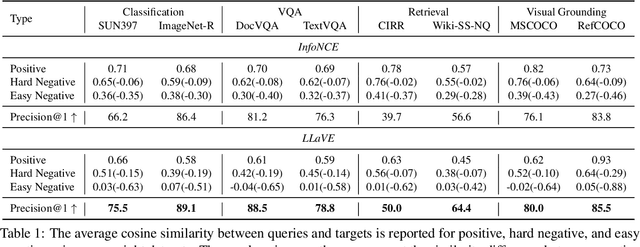
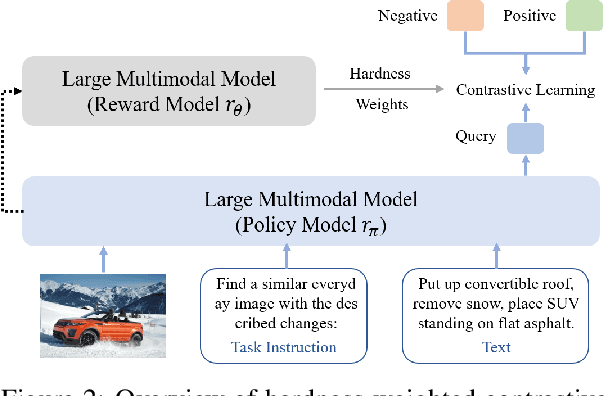
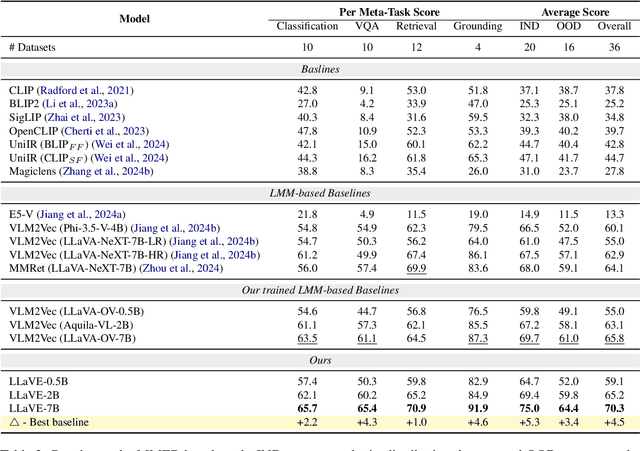
Universal multimodal embedding models play a critical role in tasks such as interleaved image-text retrieval, multimodal RAG, and multimodal clustering. However, our empirical results indicate that existing LMM-based embedding models trained with the standard InfoNCE loss exhibit a high degree of overlap in similarity distribution between positive and negative pairs, making it challenging to distinguish hard negative pairs effectively. To deal with this issue, we propose a simple yet effective framework that dynamically improves the embedding model's representation learning for negative pairs based on their discriminative difficulty. Within this framework, we train a series of models, named LLaVE, and evaluate them on the MMEB benchmark, which covers 4 meta-tasks and 36 datasets. Experimental results show that LLaVE establishes stronger baselines that achieve state-of-the-art (SOTA) performance while demonstrating strong scalability and efficiency. Specifically, LLaVE-2B surpasses the previous SOTA 7B models, while LLaVE-7B achieves a further performance improvement of 6.2 points. Although LLaVE is trained on image-text data, it can generalize to text-video retrieval tasks in a zero-shot manner and achieve strong performance, demonstrating its remarkable potential for transfer to other embedding tasks.
"I've Heard of You!": Generate Spoken Named Entity Recognition Data for Unseen Entities
Dec 26, 2024



Spoken named entity recognition (NER) aims to identify named entities from speech, playing an important role in speech processing. New named entities appear every day, however, annotating their Spoken NER data is costly. In this paper, we demonstrate that existing Spoken NER systems perform poorly when dealing with previously unseen named entities. To tackle this challenge, we propose a method for generating Spoken NER data based on a named entity dictionary (NED) to reduce costs. Specifically, we first use a large language model (LLM) to generate sentences from the sampled named entities and then use a text-to-speech (TTS) system to generate the speech. Furthermore, we introduce a noise metric to filter out noisy data. To evaluate our approach, we release a novel Spoken NER benchmark along with a corresponding NED containing 8,853 entities. Experiment results show that our method achieves state-of-the-art (SOTA) performance in the in-domain, zero-shot domain adaptation, and fully zero-shot settings. Our data will be available at https://github.com/DeepLearnXMU/HeardU.
Empowering Backbone Models for Visual Text Generation with Input Granularity Control and Glyph-Aware Training
Oct 06, 2024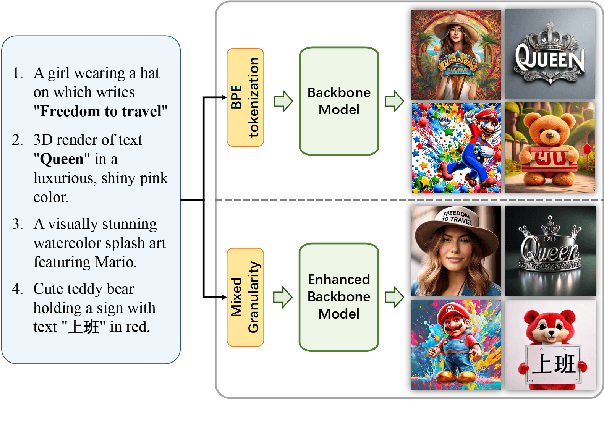
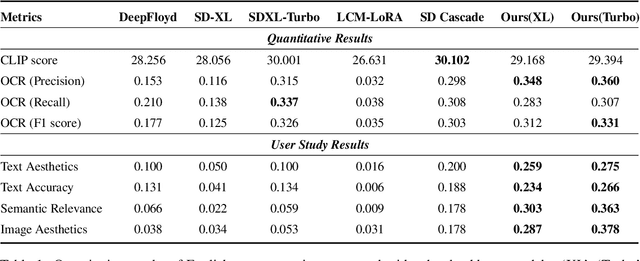
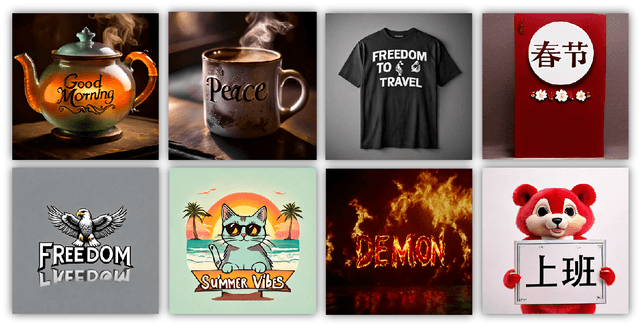

Diffusion-based text-to-image models have demonstrated impressive achievements in diversity and aesthetics but struggle to generate images with legible visual texts. Existing backbone models have limitations such as misspelling, failing to generate texts, and lack of support for Chinese text, but their development shows promising potential. In this paper, we propose a series of methods, aiming to empower backbone models to generate visual texts in English and Chinese. We first conduct a preliminary study revealing that Byte Pair Encoding (BPE) tokenization and the insufficient learning of cross-attention modules restrict the performance of the backbone models. Based on these observations, we make the following improvements: (1) We design a mixed granularity input strategy to provide more suitable text representations; (2) We propose to augment the conventional training objective with three glyph-aware training losses, which enhance the learning of cross-attention modules and encourage the model to focus on visual texts. Through experiments, we demonstrate that our methods can effectively empower backbone models to generate semantic relevant, aesthetically appealing, and accurate visual text images, while maintaining their fundamental image generation quality.
Translatotron-V(ison): An End-to-End Model for In-Image Machine Translation
Jul 03, 2024In-image machine translation (IIMT) aims to translate an image containing texts in source language into an image containing translations in target language. In this regard, conventional cascaded methods suffer from issues such as error propagation, massive parameters, and difficulties in deployment and retaining visual characteristics of the input image. Thus, constructing end-to-end models has become an option, which, however, faces two main challenges: 1) the huge modeling burden, as it is required to simultaneously learn alignment across languages and preserve the visual characteristics of the input image; 2) the difficulties of directly predicting excessively lengthy pixel sequences. In this paper, we propose \textit{Translatotron-V(ision)}, an end-to-end IIMT model consisting of four modules. In addition to an image encoder, and an image decoder, our model contains a target text decoder and an image tokenizer. Among them, the target text decoder is used to alleviate the language alignment burden, and the image tokenizer converts long sequences of pixels into shorter sequences of visual tokens, preventing the model from focusing on low-level visual features. Besides, we present a two-stage training framework for our model to assist the model in learning alignment across modalities and languages. Finally, we propose a location-aware evaluation metric called Structure-BLEU to assess the translation quality of the generated images. Experimental results demonstrate that our model achieves competitive performance compared to cascaded models with only 70.9\% of parameters, and significantly outperforms the pixel-level end-to-end IIMT model.
A Survey on Multi-modal Machine Translation: Tasks, Methods and Challenges
May 23, 2024In recent years, multi-modal machine translation has attracted significant interest in both academia and industry due to its superior performance. It takes both textual and visual modalities as inputs, leveraging visual context to tackle the ambiguities in source texts. In this paper, we begin by offering an exhaustive overview of 99 prior works, comprehensively summarizing representative studies from the perspectives of dominant models, datasets, and evaluation metrics. Afterwards, we analyze the impact of various factors on model performance and finally discuss the possible research directions for this task in the future. Over time, multi-modal machine translation has developed more types to meet diverse needs. Unlike previous surveys confined to the early stage of multi-modal machine translation, our survey thoroughly concludes these emerging types from different aspects, so as to provide researchers with a better understanding of its current state.
Exploring Better Text Image Translation with Multimodal Codebook
Jun 02, 2023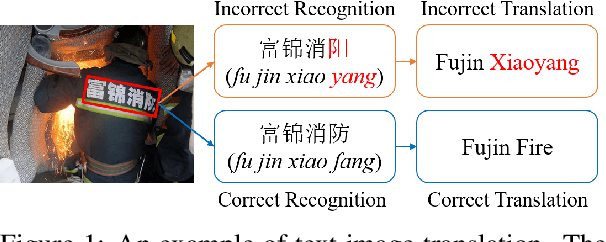



Text image translation (TIT) aims to translate the source texts embedded in the image to target translations, which has a wide range of applications and thus has important research value. However, current studies on TIT are confronted with two main bottlenecks: 1) this task lacks a publicly available TIT dataset, 2) dominant models are constructed in a cascaded manner, which tends to suffer from the error propagation of optical character recognition (OCR). In this work, we first annotate a Chinese-English TIT dataset named OCRMT30K, providing convenience for subsequent studies. Then, we propose a TIT model with a multimodal codebook, which is able to associate the image with relevant texts, providing useful supplementary information for translation. Moreover, we present a multi-stage training framework involving text machine translation, image-text alignment, and TIT tasks, which fully exploits additional bilingual texts, OCR dataset and our OCRMT30K dataset to train our model. Extensive experiments and in-depth analyses strongly demonstrate the effectiveness of our proposed model and training framework.