 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fine-Grained Code-Switch Speech Translation with Semantic Space Alignment
Nov 09, 2025Code-switching (CS) speech translation (ST) refers to translating speech that alternates between two or more languages into a target language text, which poses significant challenges due to the complexity of semantic modeling and the scarcity of CS data. Previous studies tend to rely on the model itself to implicitly learn semantic modeling during training, and resort to inefficient and costly manual annotations for these two challenges. To mitigate these limitations, we propose enhancing Large Language Models (LLMs) with a Mixture of Experts (MoE) speech projector, where each expert specializes in the semantic subspace of a specific language, enabling fine-grained modeling of speech features. Additionally, we introduce a multi-stage training paradigm that utilizes readily available monolingual automatic speech recognition (ASR) and monolingual ST data, facilitating speech-text alignment and improving translation capabilities. During training, we leverage a combination of language-specific loss and intra-group load balancing loss to guide the MoE speech projector in efficiently allocating tokens to the appropriate experts, across expert groups and within each group, respectively. To bridge the data gap across different training stages and improve adaptation to the CS scenario, we further employ a transition loss, enabling smooth transitions of data between stages, to effectively address the scarcity of high-quality CS speech translation data. Extensive experiments on widely used datasets demonstrate the effectiveness and generality of our approach.
VLFeedback: A Large-Scale AI Feedback Dataset for Large Vision-Language Models Alignment
Oct 12, 2024



As large vision-language models (LVLMs) evolve rapidly, the demand for high-quality and diverse data to align these models becomes increasingly crucial. However, the creation of such data with human supervision proves costly and time-intensive. In this paper, we investigate the efficacy of AI feedback to scale supervision for aligning LVLMs. We introduce VLFeedback, the first large-scale vision-language feedback dataset, comprising over 82K multi-modal instructions and comprehensive rationales generated by off-the-shelf models without human annotations. To evaluate the effectiveness of AI feedback for vision-language alignment, we train Silkie, an LVLM fine-tuned via direct preference optimization on VLFeedback. Silkie showcases exceptional performance regarding helpfulness, visual faithfulness, and safety metrics. It outperforms its base model by 6.9\% and 9.5\% in perception and cognition tasks, reduces hallucination issues on MMHal-Bench, and exhibits enhanced resilience against red-teaming attacks. Furthermore, our analysis underscores the advantage of AI feedback, particularly in fostering preference diversity to deliver more comprehensive improvements. Our dataset, training code and models are available at https://vlf-silkie.github.io.
Improving Long Text Understanding with Knowledge Distilled from Summarization Model
May 08, 2024Long text understanding is important yet challenging for natural language processing. A long article or document usually contains many redundant words that are not pertinent to its gist and sometimes can be regarded as noise. With recent advances of abstractive summarization, we propose our \emph{Gist Detector} to leverage the gist detection ability of a summarization model and integrate the extracted gist into downstream models to enhance their long text understanding ability. Specifically, Gist Detector first learns the gist detection knowledge distilled from a summarization model, and then produces gist-aware representations to augment downstream models. We evaluate our method on three different tasks: long document classification, distantly supervised open-domain question answering, and non-parallel text style transfer. The experimental results show that our method can significantly improve the performance of baseline models on all tasks.
Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models
Apr 18, 2024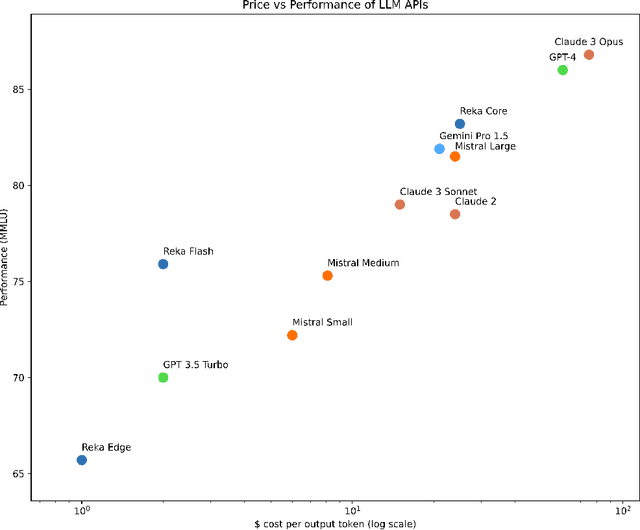


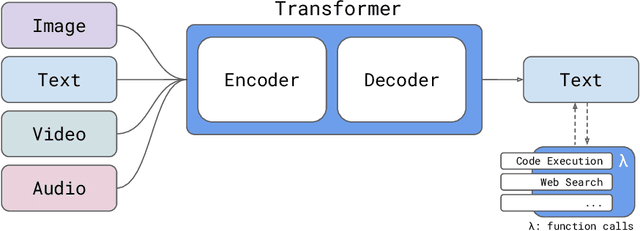
We introduce Reka Core, Flash, and Edge, a series of powerful multimodal language models trained from scratch by Reka. Reka models are able to process and reason with text, images, video, and audio inputs. This technical report discusses details of training some of these models and provides comprehensive evaluation results. We show that Reka Edge and Reka Flash are not only state-of-the-art but also outperform many much larger models, delivering outsized values for their respective compute class. Meanwhile, our most capable and largest model, Reka Core, approaches the best frontier models on both automatic evaluations and blind human evaluations. On image question answering benchmarks (e.g. MMMU, VQAv2), Core performs competitively to GPT4-V. Meanwhile, on multimodal chat, Core ranks as the second most preferred model under a blind third-party human evaluation setup, outperforming other models such as Claude 3 Opus. On text benchmarks, Core not only performs competitively to other frontier models on a set of well-established benchmarks (e.g. MMLU, GSM8K) but also outperforms GPT4-0613 on human evaluation. On video question answering (Perception-Test), Core outperforms Gemini Ultra. Models are shipped in production at http://chat.reka.ai . A showcase of non cherry picked qualitative examples can also be found at http://showcase.reka.ai .
Unleashing the Potential of Large Language Models for Predictive Tabular Tasks in Data Science
Apr 07, 2024
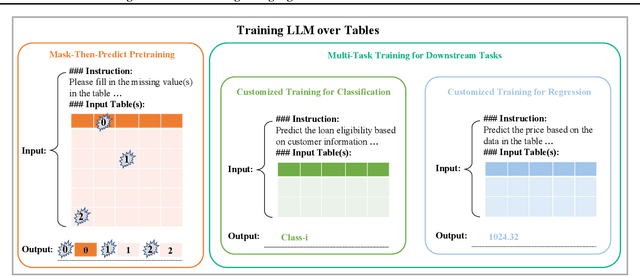
In the domain of data science, the predictive tasks of classification, regression, and imputation of missing values are commonly encountered challenges associated with tabular data. This research endeavors to apply Large Language Models (LLMs) towards addressing these predictive tasks. Despite their proficiency in comprehending natural language, LLMs fall short in dealing with structured tabular data. This limitation stems from their lacking exposure to the intricacies of tabular data during their foundational training. Our research aims to mitigate this gap by compiling a comprehensive corpus of tables annotated with instructions and executing large-scale training of Llama-2 on this enriched dataset. Furthermore, we investigate the practical application of applying the trained model to zero-shot prediction, few-shot prediction, and in-context learning scenarios. Through extensive experiments, our methodology has shown significant improvements over existing benchmarks. These advancements highlight the efficacy of tailoring LLM training to solve table-related problems in data science, thereby establishing a new benchmark in the utilization of LLMs for enhancing tabular intelligence.
Silkie: Preference Distillation for Large Visual Language Models
Dec 17, 2023This paper explores preference distillation for large vision language models (LVLMs), improving their ability to generate helpful and faithful responses anchoring the visual context. We first build a vision-language feedback (VLFeedback) dataset utilizing AI annotation. Specifically, responses are generated by models sampled from 12 LVLMs, conditioned on multi-modal instructions sourced from various datasets. We adopt GPT-4V to assess the generated outputs regarding helpfulness, visual faithfulness, and ethical considerations. Furthermore, the preference supervision is distilled into Qwen-VL-Chat through the direct preference optimization (DPO) method. The resulting model Silkie, achieves 6.9% and 9.5% relative improvement on the MME benchmark regarding the perception and cognition capabilities, respectively. Silkie also demonstrates reduced hallucination by setting a new state-of-the-art score of 3.02 on the MMHal-Bench benchmark. Further analysis shows that DPO with our VLFeedback dataset mainly boosts the fine-grained perception and complex cognition abilities of LVLMs, leading to more comprehensive improvements compared to human-annotated preference datasets.
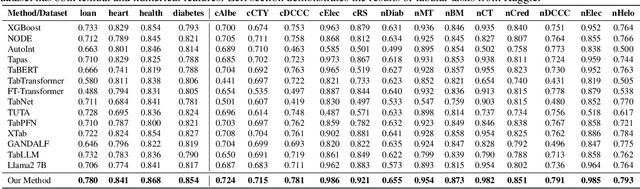
FinPT: Financial Risk Prediction with Profile Tuning on Pretrained Foundation Models
Jul 22, 2023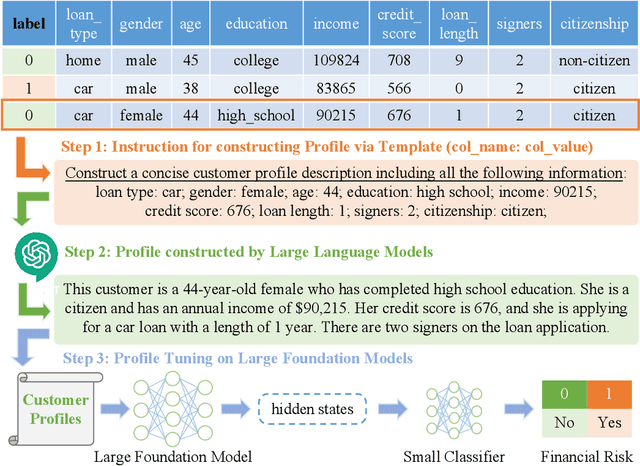
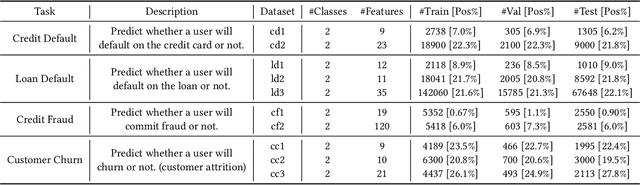
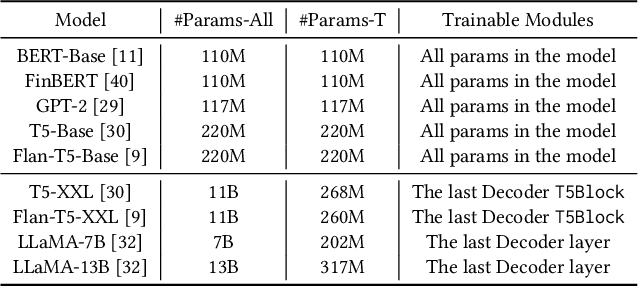
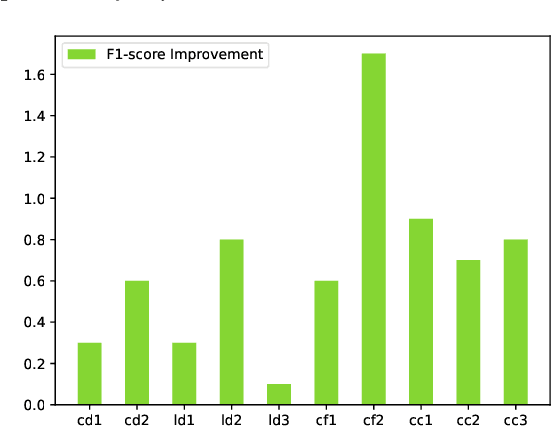
Financial risk prediction plays a crucial role in the financial sector. Machine learning methods have been widely applied for automatically detecting potential risks and thus saving the cost of labor. However, the development in this field is lagging behind in recent years by the following two facts: 1) the algorithms used are somewhat outdated, especially in the context of the fast advance of generative AI and large language models (LLMs); 2) the lack of a unified and open-sourced financial benchmark has impeded the related research for years. To tackle these issues, we propose FinPT and FinBench: the former is a novel approach for financial risk prediction that conduct Profile Tuning on large pretrained foundation models, and the latter is a set of high-quality datasets on financial risks such as default, fraud, and churn. In FinPT, we fill the financial tabular data into the pre-defined instruction template, obtain natural-language customer profiles by prompting LLMs, and fine-tune large foundation models with the profile text to make predictions. We demonstrate the effectiveness of the proposed FinPT by experimenting with a range of representative strong baselines on FinBench. The analytical studies further deepen the understanding of LLMs for financial risk prediction.
UniTabE: Pretraining a Unified Tabular Encoder for Heterogeneous Tabular Data
Jul 18, 2023



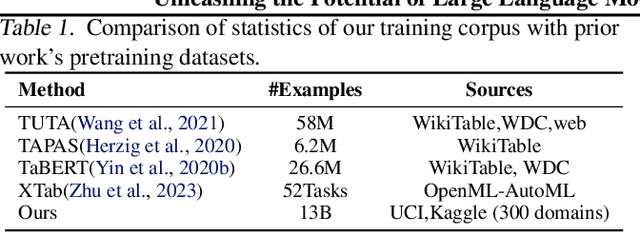
Recent advancements in Natural Language Processing (NLP) have witnessed the groundbreaking impact of pretrained models, yielding impressive outcomes across various tasks. This study seeks to extend the power of pretraining methodologies to tabular data, a domain traditionally overlooked, yet inherently challenging due to the plethora of table schemas intrinsic to different tasks. The primary research questions underpinning this work revolve around the adaptation to heterogeneous table structures, the establishment of a universal pretraining protocol for tabular data, the generalizability and transferability of learned knowledge across tasks, the adaptation to diverse downstream applications, and the incorporation of incremental columns over time. In response to these challenges, we introduce UniTabE, a pioneering method designed to process tables in a uniform manner, devoid of constraints imposed by specific table structures. UniTabE's core concept relies on representing each basic table element with a module, termed TabUnit. This is subsequently followed by a Transformer encoder to refine the representation. Moreover, our model is designed to facilitate pretraining and finetuning through the utilization of free-form prompts. In order to implement the pretraining phase, we curated an expansive tabular dataset comprising approximately 13 billion samples, meticulously gathered from the Kaggle platform. Rigorous experimental testing and analyses were performed under a myriad of scenarios to validate the effectiveness of our methodology. The experimental results demonstrate UniTabE's superior performance against several baseline models across a multitude of benchmark datasets. This, therefore, underscores UniTabE's potential to significantly enhance the semantic representation of tabular data, thereby marking a significant stride in the field of tabular data analysis.
MSSRNet: Manipulating Sequential Style Representation for Unsupervised Text Style Transfer
Jun 12, 2023Unsupervised text style transfer task aims to rewrite a text into target style while preserving its main content. Traditional methods rely on the use of a fixed-sized vector to regulate text style, which is difficult to accurately convey the style strength for each individual token. In fact, each token of a text contains different style intensity and makes different contribution to the overall style. Our proposed method addresses this issue by assigning individual style vector to each token in a text, allowing for fine-grained control and manipulation of the style strength. Additionally, an adversarial training framework integrated with teacher-student learning is introduced to enhance training stability and reduce the complexity of high-dimensional optimization. The results of our experiments demonstrate the efficacy of our method in terms of clearly improved style transfer accuracy and content preservation in both two-style transfer and multi-style transfer settings.
M$^3$IT: A Large-Scale Dataset towards Multi-Modal Multilingual Instruction Tuning
Jun 08, 2023Instruction tuning has significantly advanced large language models (LLMs) such as ChatGPT, enabling them to align with human instructions across diverse tasks. However, progress in open vision-language models (VLMs) has been limited due to the scarcity of high-quality instruction datasets. To tackle this challenge and promote research in the vision-language field, we introduce the Multi-Modal, Multilingual Instruction Tuning (M$^3$IT) dataset, designed to optimize VLM alignment with human instructions. Our M$^3$IT dataset comprises 40 carefully curated datasets, including 2.4 million instances and 400 manually written task instructions, reformatted into a vision-to-text structure. Key tasks are translated into 80 languages with an advanced translation system, ensuring broader accessibility. M$^3$IT surpasses previous datasets regarding task coverage, instruction number and instance scale. Moreover, we develop Ying-VLM, a VLM model trained on our M$^3$IT dataset, showcasing its potential to answer complex questions requiring world knowledge, generalize to unseen video tasks, and comprehend unseen instructions in Chinese. We have open-sourced the dataset to encourage further research.