 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the Potential of Large Language Models for Predictive Tabular Tasks in Data Science
Apr 07, 2024
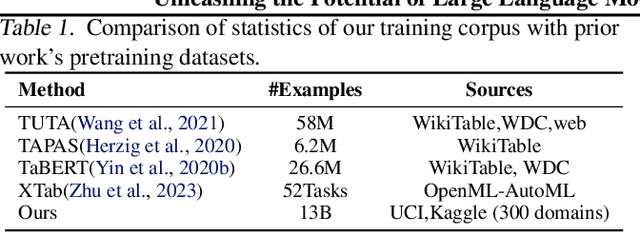
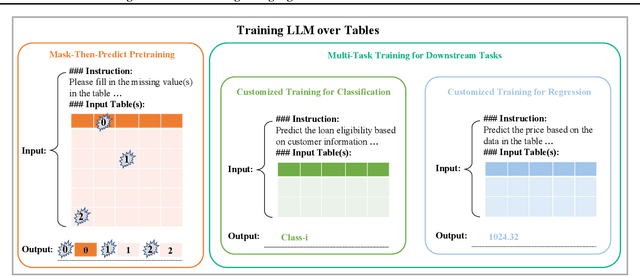
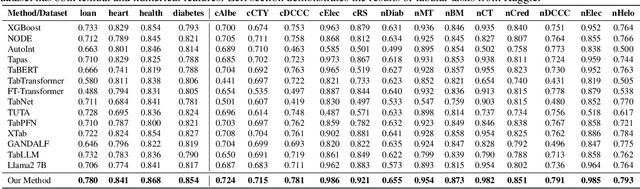
In the domain of data science, the predictive tasks of classification, regression, and imputation of missing values are commonly encountered challenges associated with tabular data. This research endeavors to apply Large Language Models (LLMs) towards addressing these predictive tasks. Despite their proficiency in comprehending natural language, LLMs fall short in dealing with structured tabular data. This limitation stems from their lacking exposure to the intricacies of tabular data during their foundational training. Our research aims to mitigate this gap by compiling a comprehensive corpus of tables annotated with instructions and executing large-scale training of Llama-2 on this enriched dataset. Furthermore, we investigate the practical application of applying the trained model to zero-shot prediction, few-shot prediction, and in-context learning scenarios. Through extensive experiments, our methodology has shown significant improvements over existing benchmarks. These advancements highlight the efficacy of tailoring LLM training to solve table-related problems in data science, thereby establishing a new benchmark in the utilization of LLMs for enhancing tabular intelligence.
Analyzing Hong Kong's Legal Judgments from a Computational Linguistics point-of-view
May 04, 2023Analysis and extraction of useful information from legal judgments using computational linguistics was one of the earliest problems posed in the domain of information retrieval. Presently, several commercial vendors exist who automate such tasks. However, a crucial bottleneck arises in the form of exorbitant pricing and lack of resources available in analysis of judgements mete out by Hong Kong's Legal System. This paper attempts to bridge this gap by providing several statistical, machine learning, deep learning and zero-shot learning based methods to effectively analyze legal judgments from Hong Kong's Court System. The methods proposed consists of: (1) Citation Network Graph Generation, (2) PageRank Algorithm, (3) Keyword Analysis and Summarization, (4) Sentiment Polarity, and (5) Paragrah Classification, in order to be able to extract key insights from individual as well a group of judgments together. This would make the overall analysis of judgments in Hong Kong less tedious and more automated in order to extract insights quickly using fast inferencing. We also provide an analysis of our results by benchmarking our results using Large Language Models making robust use of the HuggingFace ecosystem.
Exploring the Effects of Data Augmentation for Drivable Area Segmentation
Aug 06, 2022
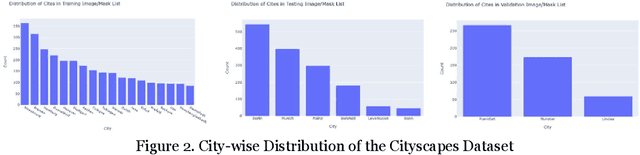
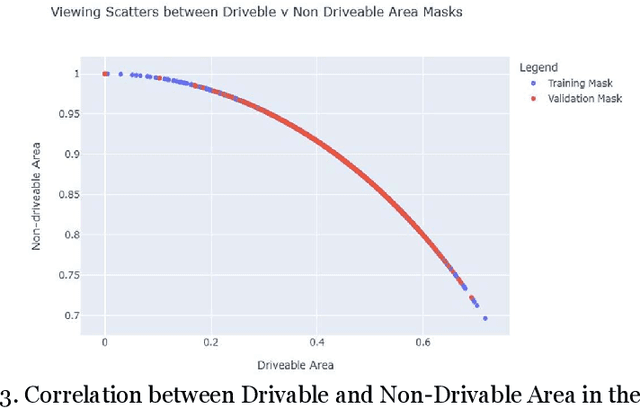
The real-time segmentation of drivable areas plays a vital role in accomplishing autonomous perception in cars. Recently there have been some rapid strides in the development of image segmentation models using deep learning. However, most of the advancements have been made in model architecture design. In solving any supervised deep learning problem related to segmentation, the success of the model that one builds depends upon the amount and quality of input training data we use for that model. This data should contain well-annotated varied images for better working of the segmentation model. Issues like this pertaining to annotations in a dataset can lead the model to conclude with overwhelming Type I and II errors in testing and validation, causing malicious issues when trying to tackle real world problems. To address this problem and to make our model more accurate, dynamic, and robust, data augmentation comes into usage as it helps in expanding our sample training data and making it better and more diversified overall. Hence, in our study, we focus on investigating the benefits of data augmentation by analyzing pre-existing image datasets and performing augmentations accordingly. Our results show that the performance and robustness of existing state of the art (or SOTA) models can be increased dramatically without any increase in model complexity or inference time. The augmentations decided on and used in this paper were decided only after thorough research of several other augmentation methodologies and strategies and their corresponding effects that are in widespread usage today. All our results are being reported on the widely used Cityscapes Dataset.