 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Effects of Data Augmentation for Drivable Area Segmentation
Aug 06, 2022
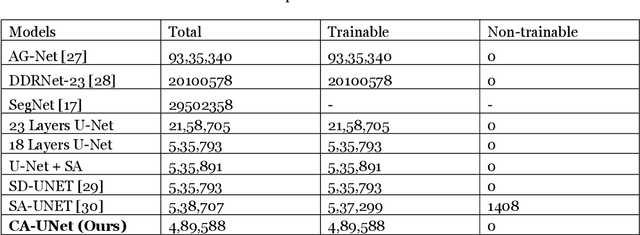
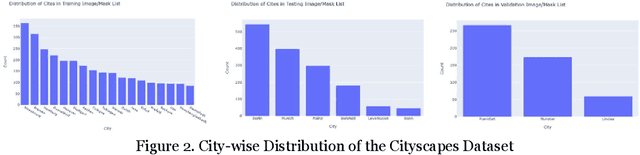
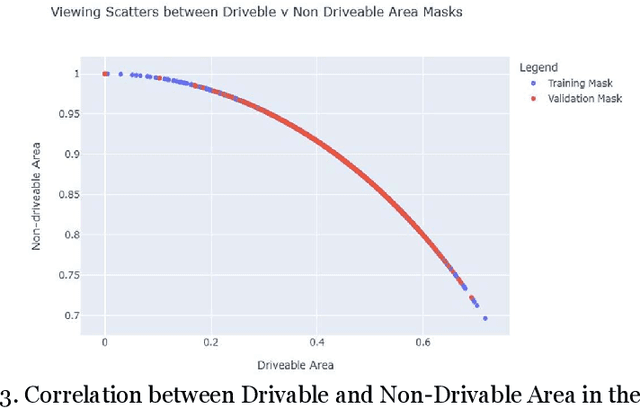
The real-time segmentation of drivable areas plays a vital role in accomplishing autonomous perception in cars. Recently there have been some rapid strides in the development of image segmentation models using deep learning. However, most of the advancements have been made in model architecture design. In solving any supervised deep learning problem related to segmentation, the success of the model that one builds depends upon the amount and quality of input training data we use for that model. This data should contain well-annotated varied images for better working of the segmentation model. Issues like this pertaining to annotations in a dataset can lead the model to conclude with overwhelming Type I and II errors in testing and validation, causing malicious issues when trying to tackle real world problems. To address this problem and to make our model more accurate, dynamic, and robust, data augmentation comes into usage as it helps in expanding our sample training data and making it better and more diversified overall. Hence, in our study, we focus on investigating the benefits of data augmentation by analyzing pre-existing image datasets and performing augmentations accordingly. Our results show that the performance and robustness of existing state of the art (or SOTA) models can be increased dramatically without any increase in model complexity or inference time. The augmentations decided on and used in this paper were decided only after thorough research of several other augmentation methodologies and strategies and their corresponding effects that are in widespread usage today. All our results are being reported on the widely used Cityscapes Dataset.