 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBellman Error Centering
Feb 05, 2025



This paper revisits the recently proposed reward centering algorithms including simple reward centering (SRC) and value-based reward centering (VRC), and points out that SRC is indeed the reward centering, while VRC is essentially Bellman error centering (BEC). Based on BEC, we provide the centered fixpoint for tabular value functions, as well as the centered TD fixpoint for linear value function approximation. We design the on-policy CTD algorithm and the off-policy CTDC algorithm, and prove the convergence of both algorithms. Finally, we experimentally validate the stability of our proposed algorithms. Bellman error centering facilitates the extension to various reinforcement learning algorithms.
A Variance Minimization Approach to Temporal-Difference Learning
Nov 10, 2024Fast-converging algorithms are a contemporary requirement in reinforcement learning. In the context of linear function approximation, the magnitude of the smallest eigenvalue of the key matrix is a major factor reflecting the convergence speed. Traditional value-based RL algorithms focus on minimizing errors. This paper introduces a variance minimization (VM) approach for value-based RL instead of error minimization. Based on this approach, we proposed two objectives, the Variance of Bellman Error (VBE) and the Variance of Projected Bellman Error (VPBE), and derived the VMTD, VMTDC, and VMETD algorithms. We provided proofs of their convergence and optimal policy invariance of the variance minimization. Experimental studies validate the effectiveness of the proposed algorithms.
MoE-I$^2$: Compressing Mixture of Experts Models through Inter-Expert Pruning and Intra-Expert Low-Rank Decomposition
Nov 01, 2024

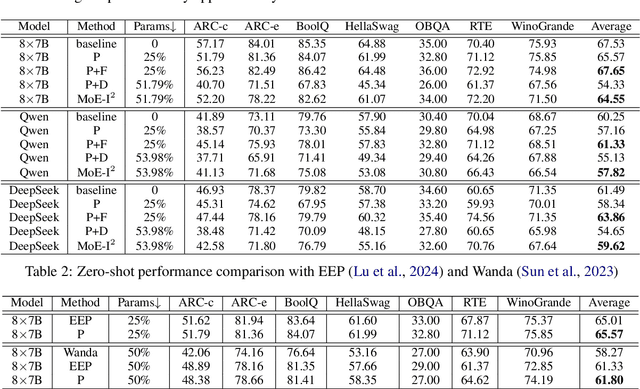
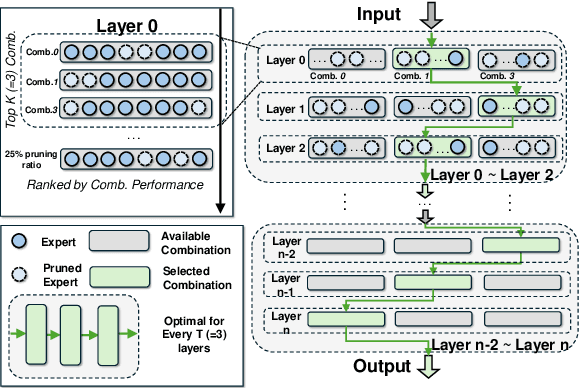
The emergence of Mixture of Experts (MoE) LLMs has significantly advanced the development of language models. Compared to traditional LLMs, MoE LLMs outperform traditional LLMs by achieving higher performance with considerably fewer activated parameters. Despite this efficiency, their enormous parameter size still leads to high deployment costs. In this paper, we introduce a two-stage compression method tailored for MoE to reduce the model size and decrease the computational cost. First, in the inter-expert pruning stage, we analyze the importance of each layer and propose the Layer-wise Genetic Search and Block-wise KT-Reception Field with the non-uniform pruning ratio to prune the individual expert. Second, in the intra-expert decomposition stage, we apply the low-rank decomposition to further compress the parameters within the remaining experts. Extensive experiments on Qwen1.5-MoE-A2.7B, DeepSeek-V2-Lite, and Mixtral-8$\times$7B demonstrate that our proposed methods can both reduce the model size and enhance inference efficiency while maintaining performance in various zero-shot tasks. The code will be available at \url{https://github.com/xiaochengsky/MoEI-2.git}
ELRT: Efficient Low-Rank Training for Compact Convolutional Neural Networks
Jan 18, 2024Low-rank compression, a popular model compression technique that produces compact convolutional neural networks (CNNs) with low rankness, has been well-studied in the literature. On the other hand, low-rank training, as an alternative way to train low-rank CNNs from scratch, has been exploited little yet. Unlike low-rank compression, low-rank training does not need pre-trained full-rank models, and the entire training phase is always performed on the low-rank structure, bringing attractive benefits for practical applications. However, the existing low-rank training solutions still face several challenges, such as a considerable accuracy drop and/or still needing to update full-size models during the training. In this paper, we perform a systematic investigation on low-rank CNN training. By identifying the proper low-rank format and performance-improving strategy, we propose ELRT, an efficient low-rank training solution for high-accuracy, high-compactness, low-rank CNN models. Our extensive evaluation results for training various CNNs on different datasets demonstrate the effectiveness of ELRT.
COMCAT: Towards Efficient Compression and Customization of Attention-Based Vision Models
Jun 09, 2023



Attention-based vision models, such as Vision Transformer (ViT) and its variants, have shown promising performance in various computer vision tasks. However, these emerging architectures suffer from large model sizes and high computational costs, calling for efficient model compression solutions. To date, pruning ViTs has been well studied, while other compression strategies that have been widely applied in CNN compression, e.g., model factorization, is little explored in the context of ViT compression. This paper explores an efficient method for compressing vision transformers to enrich the toolset for obtaining compact attention-based vision models. Based on the new insight on the multi-head attention layer, we develop a highly efficient ViT compression solution, which outperforms the state-of-the-art pruning methods. For compressing DeiT-small and DeiT-base models on ImageNet, our proposed approach can achieve 0.45% and 0.76% higher top-1 accuracy even with fewer parameters. Our finding can also be applied to improve the customization efficiency of text-to-image diffusion models, with much faster training (up to $2.6\times$ speedup) and lower extra storage cost (up to $1927.5\times$ reduction) than the existing works.
Human-machine knowledge hybrid augmentation method for surface defect detection based few-data learning
May 02, 2023



Visual-based defect detection is a crucial but challenging task in industrial quality control. Most mainstream methods rely on large amounts of existing or related domain data as auxiliary information. However, in actual industrial production, there are often multi-batch, low-volume manufacturing scenarios with rapidly changing task demands, making it difficult to obtain sufficient and diverse defect data. This paper proposes a parallel solution that uses a human-machine knowledge hybrid augmentation method to help the model extract unknown important features. Specifically, by incorporating experts' knowledge of abnormality to create data with rich features, positions, sizes, and backgrounds, we can quickly accumulate an amount of data from scratch and provide it to the model as prior knowledge for few-data learning. The proposed method was evaluated on the magnetic tile dataset and achieved F1-scores of 60.73%, 70.82%, 77.09%, and 82.81% when using 2, 5, 10, and 15 training images, respectively. Compared to the traditional augmentation method's F1-score of 64.59%, the proposed method achieved an 18.22% increase in the best result, demonstrating its feasibility and effectiveness in few-data industrial defect detection.
HALOC: Hardware-Aware Automatic Low-Rank Compression for Compact Neural Networks
Jan 20, 2023



Low-rank compression is an important model compression strategy for obtaining compact neural network models. In general, because the rank values directly determine the model complexity and model accuracy, proper selection of layer-wise rank is very critical and desired. To date, though many low-rank compression approaches, either selecting the ranks in a manual or automatic way, have been proposed, they suffer from costly manual trials or unsatisfied compression performance. In addition, all of the existing works are not designed in a hardware-aware way, limiting the practical performance of the compressed models on real-world hardware platforms. To address these challenges, in this paper we propose HALOC, a hardware-aware automatic low-rank compression framework. By interpreting automatic rank selection from an architecture search perspective, we develop an end-to-end solution to determine the suitable layer-wise ranks in a differentiable and hardware-aware way. We further propose design principles and mitigation strategy to efficiently explore the rank space and reduce the potential interference problem. Experimental results on different datasets and hardware platforms demonstrate the effectiveness of our proposed approach. On CIFAR-10 dataset, HALOC enables 0.07% and 0.38% accuracy increase over the uncompressed ResNet-20 and VGG-16 models with 72.20% and 86.44% fewer FLOPs, respectively. On ImageNet dataset, HALOC achieves 0.9% higher top-1 accuracy than the original ResNet-18 model with 66.16% fewer FLOPs. HALOC also shows 0.66% higher top-1 accuracy increase than the state-of-the-art automatic low-rank compression solution with fewer computational and memory costs. In addition, HALOC demonstrates the practical speedups on different hardware platforms, verified by the measurement results on desktop GPU, embedded GPU and ASIC accelerator.
Algorithm and Hardware Co-Design of Energy-Efficient LSTM Networks for Video Recognition with Hierarchical Tucker Tensor Decomposition
Dec 05, 2022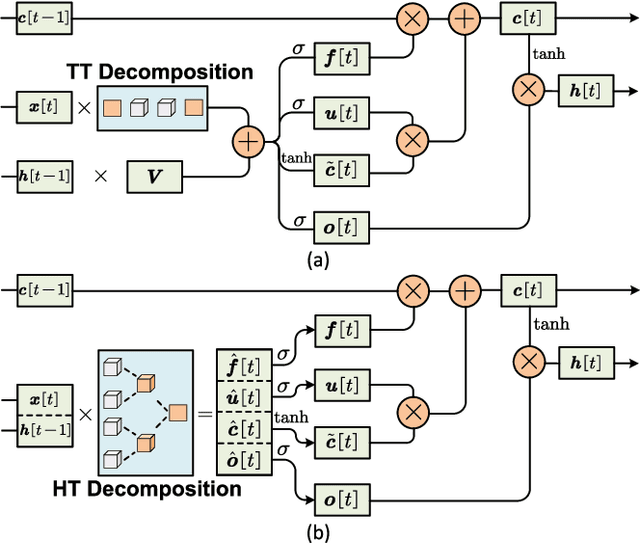
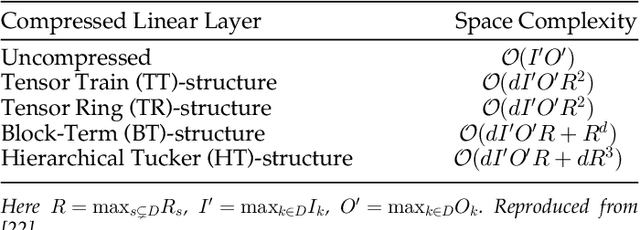
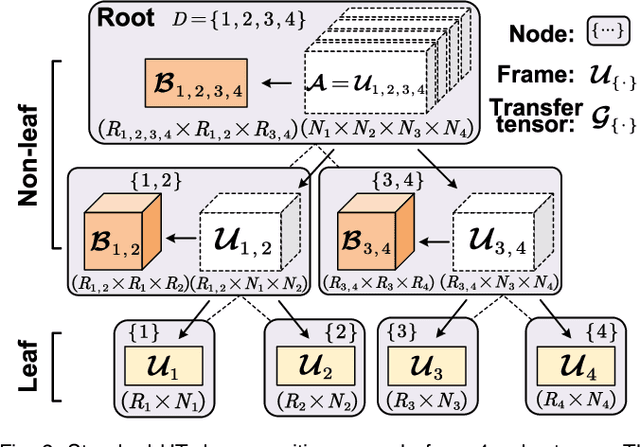

Long short-term memory (LSTM) is a type of powerful deep neural network that has been widely used in many sequence analysis and modeling applications. However, the large model size problem of LSTM networks make their practical deployment still very challenging, especially for the video recognition tasks that require high-dimensional input data. Aiming to overcome this limitation and fully unlock the potentials of LSTM models, in this paper we propose to perform algorithm and hardware co-design towards high-performance energy-efficient LSTM networks. At algorithm level, we propose to develop fully decomposed hierarchical Tucker (FDHT) structure-based LSTM, namely FDHT-LSTM, which enjoys ultra-low model complexity while still achieving high accuracy. In order to fully reap such attractive algorithmic benefit, we further develop the corresponding customized hardware architecture to support the efficient execution of the proposed FDHT-LSTM model. With the delicate design of memory access scheme, the complicated matrix transformation can be efficiently supported by the underlying hardware without any access conflict in an on-the-fly way. Our evaluation results show that both the proposed ultra-compact FDHT-LSTM models and the corresponding hardware accelerator achieve very high performance. Compared with the state-of-the-art compressed LSTM models, FDHT-LSTM enjoys both order-of-magnitude reduction in model size and significant accuracy improvement across different video recognition datasets. Meanwhile, compared with the state-of-the-art tensor decomposed model-oriented hardware TIE, our proposed FDHT-LSTM architecture achieves better performance in throughput, area efficiency and energy efficiency, respectively on LSTM-Youtube workload. For LSTM-UCF workload, our proposed design also outperforms TIE with higher throughput, higher energy efficiency and comparable area efficiency.
RankSim: Ranking Similarity Regularization for Deep Imbalanced Regression
May 30, 2022
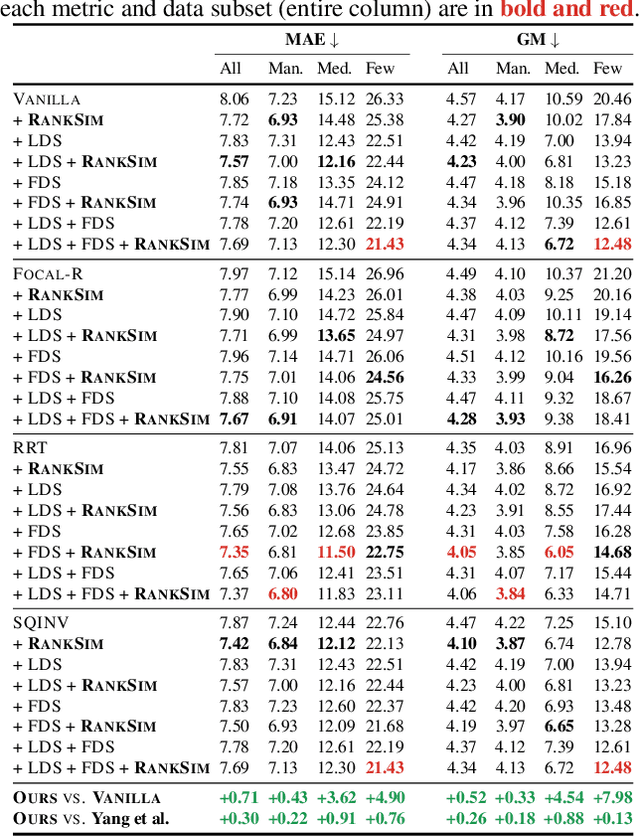
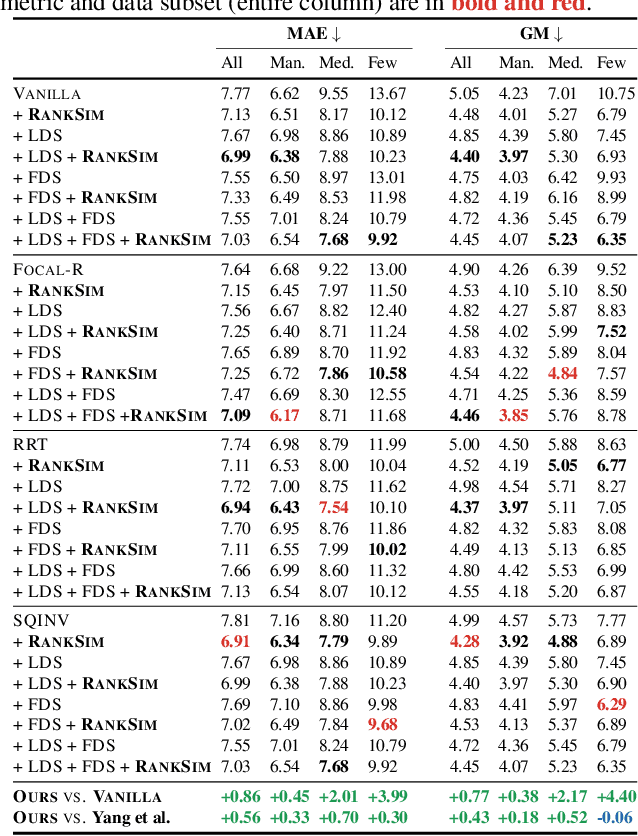

Data imbalance, in which a plurality of the data samples come from a small proportion of labels, poses a challenge in training deep neural networks. Unlike classification, in regression the labels are continuous, potentially boundless, and form a natural ordering. These distinct features of regression call for new techniques that leverage the additional information encoded in label-space relationships. This paper presents the RankSim (ranking similarity) regularizer for deep imbalanced regression, which encodes an inductive bias that samples that are closer in label space should also be closer in feature space. In contrast to recent distribution smoothing based approaches, RankSim captures both nearby and distant relationships: for a given data sample, RankSim encourages the sorted list of its neighbors in label space to match the sorted list of its neighbors in feature space. RankSim is complementary to conventional imbalanced learning techniques, including re-weighting, two-stage training, and distribution smoothing, and lifts the state-of-the-art performance on three imbalanced regression benchmarks: IMDB-WIKI-DIR, AgeDB-DIR, and STS-B-DIR.
GIFT: Graph-guIded Feature Transfer for Cold-Start Video Click-Through Rate Prediction
Feb 21, 2022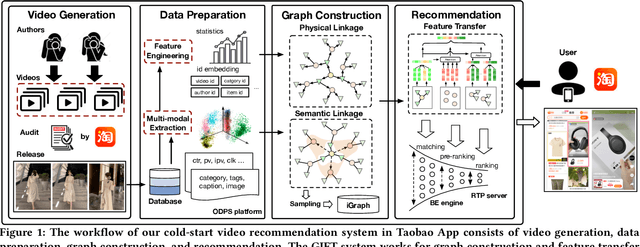
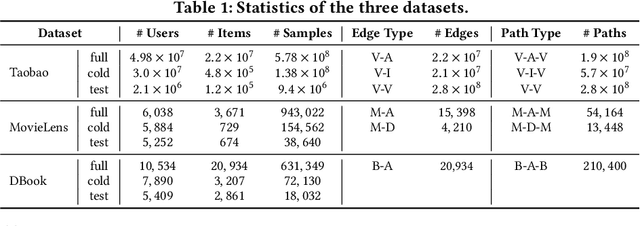


Short video has witnessed rapid growth in China and shows a promising market for promoting the sales of products in e-commerce platforms like Taobao. To ensure the freshness of the content, the platform needs to release a large number of new videos every day, which makes the conventional click-through rate (CTR) prediction model suffer from the severe item cold-start problem. In this paper, we propose GIFT, an efficient Graph-guIded Feature Transfer system, to fully take advantages of the rich information of warmed-up videos that related to the cold-start video. More specifically, we conduct feature transfer from warmed-up videos to those cold-start ones by involving the physical and semantic linkages into a heterogeneous graph. The former linkages consist of those explicit relationships (e.g., sharing the same category, under the same authorship etc.), while the latter measure the proximity of multimodal representations of two videos. In practice, the style, content, and even the recommendation pattern are pretty similar among those physically or semantically related videos. Besides, in order to provide the robust id representations and historical statistics obtained from warmed-up neighbors that cold-start videos covet most, we elaborately design the transfer function to make aware of different transferred features from different types of nodes and edges along the metapath on the graph. Extensive experiments on a large real-world dataset show that our GIFT system outperforms SOTA methods significantly and brings a 6.82% lift on click-through rate (CTR) in the homepage of Taobao App.