 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATA: Bridging Implicit Reasoning with Attention-Guided and Action-Guided Inference for Vision-Language Action Models
Mar 02, 2026Vision-Language-Action (VLA) models rely on current observations, including images, language instructions, and robot states, to predict actions and complete tasks. While accurate visual perception is crucial for precise action prediction and execution, recent work has attempted to further improve performance by introducing explicit reasoning during inference. However, such approaches face significant limitations. They often depend on data-intensive resources such as Chain-of-Thought (CoT) style annotations to decompose tasks into step-by-step reasoning, and in many cases require additional visual grounding annotations (e.g., bounding boxes or masks) to highlight relevant image regions. Moreover, they involve time-consuming dataset construction, labeling, and retraining, which ultimately results in longer inference sequences and reduced efficiency. To address these challenges, we propose ATA, a novel training-free framework that introduces implicit reasoning into VLA inference through complementary attention-guided and action-guided strategies. Unlike CoT or explicit visual-grounding methods, ATA formulates reasoning implicitly by integrating attention maps with an action-based region of interest (RoI), thereby adaptively refining visual inputs without requiring extra training or annotations. ATA is a plug-and-play implicit reasoning approach for VLA models, lightweight yet effective. Extensive experiments show that it consistently improves task success and robustness while preserving, and even enhancing, inference efficiency.
EcoSpa: Efficient Transformer Training with Coupled Sparsity
Nov 09, 2025Transformers have become the backbone of modern AI, yet their high computational demands pose critical system challenges. While sparse training offers efficiency gains, existing methods fail to preserve critical structural relationships between weight matrices that interact multiplicatively in attention and feed-forward layers. This oversight leads to performance degradation at high sparsity levels. We introduce EcoSpa, an efficient structured sparse training method that jointly evaluates and sparsifies coupled weight matrix pairs, preserving their interaction patterns through aligned row/column removal. EcoSpa introduces a new granularity for calibrating structural component importance and performs coupled estimation and sparsification across both pre-training and fine-tuning scenarios. Evaluations demonstrate substantial improvements: EcoSpa enables efficient training of LLaMA-1B with 50\% memory reduction and 21\% faster training, achieves $2.2\times$ model compression on GPT-2-Medium with $2.4$ lower perplexity, and delivers $1.6\times$ inference speedup. The approach uses standard PyTorch operations, requiring no custom hardware or kernels, making efficient transformer training accessible on commodity hardware.
MoE-I$^2$: Compressing Mixture of Experts Models through Inter-Expert Pruning and Intra-Expert Low-Rank Decomposition
Nov 01, 2024

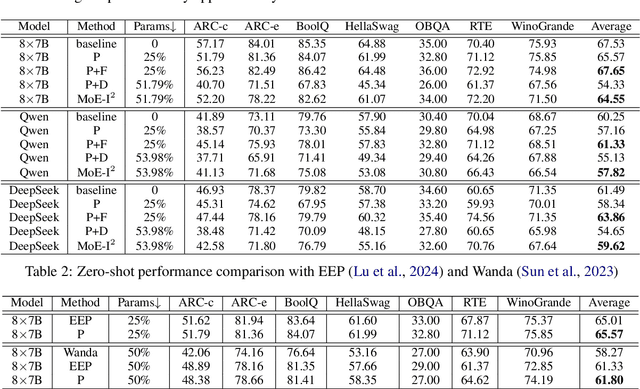
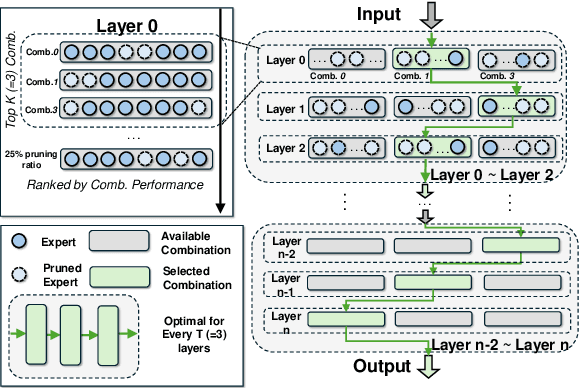
The emergence of Mixture of Experts (MoE) LLMs has significantly advanced the development of language models. Compared to traditional LLMs, MoE LLMs outperform traditional LLMs by achieving higher performance with considerably fewer activated parameters. Despite this efficiency, their enormous parameter size still leads to high deployment costs. In this paper, we introduce a two-stage compression method tailored for MoE to reduce the model size and decrease the computational cost. First, in the inter-expert pruning stage, we analyze the importance of each layer and propose the Layer-wise Genetic Search and Block-wise KT-Reception Field with the non-uniform pruning ratio to prune the individual expert. Second, in the intra-expert decomposition stage, we apply the low-rank decomposition to further compress the parameters within the remaining experts. Extensive experiments on Qwen1.5-MoE-A2.7B, DeepSeek-V2-Lite, and Mixtral-8$\times$7B demonstrate that our proposed methods can both reduce the model size and enhance inference efficiency while maintaining performance in various zero-shot tasks. The code will be available at \url{https://github.com/xiaochengsky/MoEI-2.git}
In-Sensor Radio Frequency Computing for Energy-Efficient Intelligent Radar
Dec 16, 2023Radio Frequency Neural Networks (RFNNs) have demonstrated advantages in realizing intelligent applications across various domains. However, as the model size of deep neural networks rapidly increases, implementing large-scale RFNN in practice requires an extensive number of RF interferometers and consumes a substantial amount of energy. To address this challenge, we propose to utilize low-rank decomposition to transform a large-scale RFNN into a compact RFNN while almost preserving its accuracy. Specifically, we develop a Tensor-Train RFNN (TT-RFNN) where each layer comprises a sequence of low-rank third-order tensors, leading to a notable reduction in parameter count, thereby optimizing RF interferometer utilization in comparison to the original large-scale RFNN. Additionally, considering the inherent physical errors when mapping TT-RFNN to RF device parameters in real-world deployment, from a general perspective, we construct the Robust TT-RFNN (RTT-RFNN) by incorporating a robustness solver on TT-RFNN to enhance its robustness. To adapt the RTT-RFNN to varying requirements of reshaping operations, we further provide a reconfigurable reshaping solution employing RF switch matrices. Empirical evaluations conducted on MNIST and CIFAR-10 datasets show the effectiveness of our proposed method.
Algorithm and Hardware Co-Design of Energy-Efficient LSTM Networks for Video Recognition with Hierarchical Tucker Tensor Decomposition
Dec 05, 2022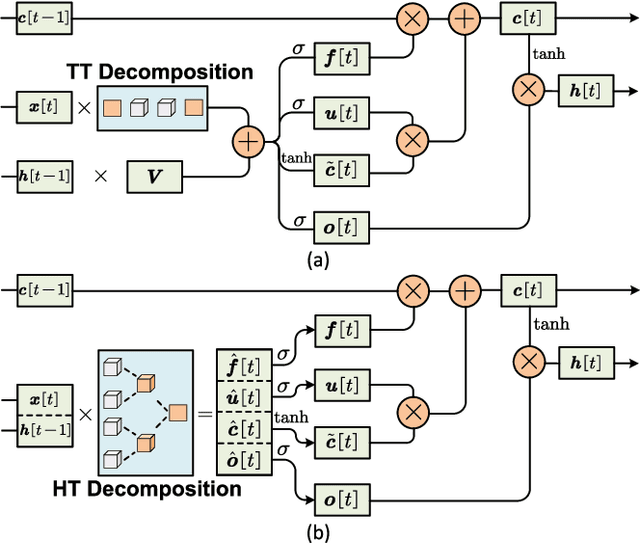
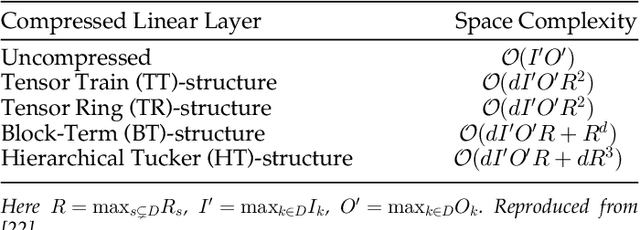
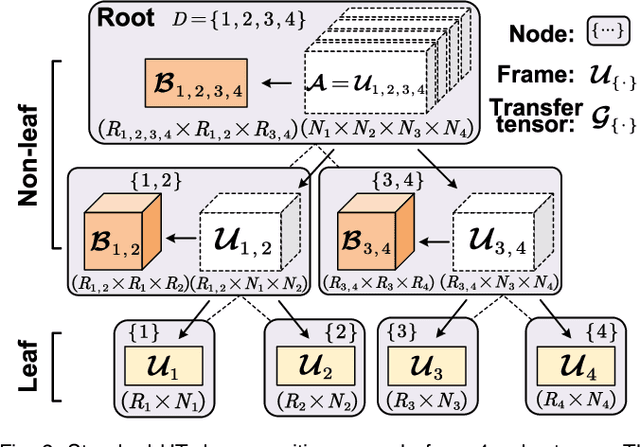

Long short-term memory (LSTM) is a type of powerful deep neural network that has been widely used in many sequence analysis and modeling applications. However, the large model size problem of LSTM networks make their practical deployment still very challenging, especially for the video recognition tasks that require high-dimensional input data. Aiming to overcome this limitation and fully unlock the potentials of LSTM models, in this paper we propose to perform algorithm and hardware co-design towards high-performance energy-efficient LSTM networks. At algorithm level, we propose to develop fully decomposed hierarchical Tucker (FDHT) structure-based LSTM, namely FDHT-LSTM, which enjoys ultra-low model complexity while still achieving high accuracy. In order to fully reap such attractive algorithmic benefit, we further develop the corresponding customized hardware architecture to support the efficient execution of the proposed FDHT-LSTM model. With the delicate design of memory access scheme, the complicated matrix transformation can be efficiently supported by the underlying hardware without any access conflict in an on-the-fly way. Our evaluation results show that both the proposed ultra-compact FDHT-LSTM models and the corresponding hardware accelerator achieve very high performance. Compared with the state-of-the-art compressed LSTM models, FDHT-LSTM enjoys both order-of-magnitude reduction in model size and significant accuracy improvement across different video recognition datasets. Meanwhile, compared with the state-of-the-art tensor decomposed model-oriented hardware TIE, our proposed FDHT-LSTM architecture achieves better performance in throughput, area efficiency and energy efficiency, respectively on LSTM-Youtube workload. For LSTM-UCF workload, our proposed design also outperforms TIE with higher throughput, higher energy efficiency and comparable area efficiency.
Robot Motion Planning as Video Prediction: A Spatio-Temporal Neural Network-based Motion Planner
Aug 24, 2022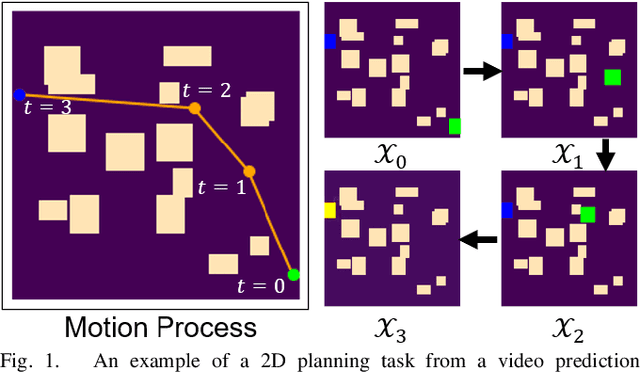
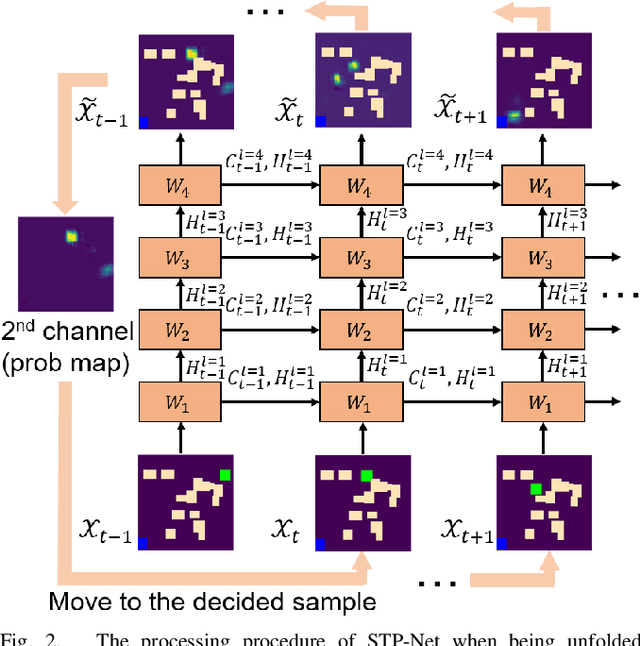
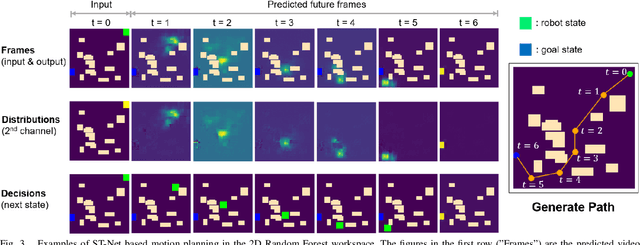
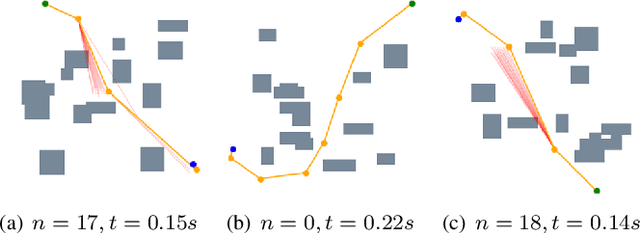
Neural network (NN)-based methods have emerged as an attractive approach for robot motion planning due to strong learning capabilities of NN models and their inherently high parallelism. Despite the current development in this direction, the efficient capture and processing of important sequential and spatial information, in a direct and simultaneous way, is still relatively under-explored. To overcome the challenge and unlock the potentials of neural networks for motion planning tasks, in this paper, we propose STP-Net, an end-to-end learning framework that can fully extract and leverage important spatio-temporal information to form an efficient neural motion planner. By interpreting the movement of the robot as a video clip, robot motion planning is transformed to a video prediction task that can be performed by STP-Net in both spatially and temporally efficient ways. Empirical evaluations across different seen and unseen environments show that, with nearly 100% accuracy (aka, success rate), STP-Net demonstrates very promising performance with respect to both planning speed and path cost. Compared with existing NN-based motion planners, STP-Net achieves at least 5x, 2.6x and 1.8x faster speed with lower path cost on 2D Random Forest, 2D Maze and 3D Random Forest environments, respectively. Furthermore, STP-Net can quickly and simultaneously compute multiple near-optimal paths in multi-robot motion planning tasks