 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcoSpa: Efficient Transformer Training with Coupled Sparsity
Nov 09, 2025Transformers have become the backbone of modern AI, yet their high computational demands pose critical system challenges. While sparse training offers efficiency gains, existing methods fail to preserve critical structural relationships between weight matrices that interact multiplicatively in attention and feed-forward layers. This oversight leads to performance degradation at high sparsity levels. We introduce EcoSpa, an efficient structured sparse training method that jointly evaluates and sparsifies coupled weight matrix pairs, preserving their interaction patterns through aligned row/column removal. EcoSpa introduces a new granularity for calibrating structural component importance and performs coupled estimation and sparsification across both pre-training and fine-tuning scenarios. Evaluations demonstrate substantial improvements: EcoSpa enables efficient training of LLaMA-1B with 50\% memory reduction and 21\% faster training, achieves $2.2\times$ model compression on GPT-2-Medium with $2.4$ lower perplexity, and delivers $1.6\times$ inference speedup. The approach uses standard PyTorch operations, requiring no custom hardware or kernels, making efficient transformer training accessible on commodity hardware.
COMCAT: Towards Efficient Compression and Customization of Attention-Based Vision Models
Jun 09, 2023



Attention-based vision models, such as Vision Transformer (ViT) and its variants, have shown promising performance in various computer vision tasks. However, these emerging architectures suffer from large model sizes and high computational costs, calling for efficient model compression solutions. To date, pruning ViTs has been well studied, while other compression strategies that have been widely applied in CNN compression, e.g., model factorization, is little explored in the context of ViT compression. This paper explores an efficient method for compressing vision transformers to enrich the toolset for obtaining compact attention-based vision models. Based on the new insight on the multi-head attention layer, we develop a highly efficient ViT compression solution, which outperforms the state-of-the-art pruning methods. For compressing DeiT-small and DeiT-base models on ImageNet, our proposed approach can achieve 0.45% and 0.76% higher top-1 accuracy even with fewer parameters. Our finding can also be applied to improve the customization efficiency of text-to-image diffusion models, with much faster training (up to $2.6\times$ speedup) and lower extra storage cost (up to $1927.5\times$ reduction) than the existing works.
GUAP: Graph Universal Attack Through Adversarial Patching
Jan 04, 2023Graph neural networks (GNNs) are a class of effective deep learning models for node classification tasks; yet their predictive capability may be severely compromised under adversarially designed unnoticeable perturbations to the graph structure and/or node data. Most of the current work on graph adversarial attacks aims at lowering the overall prediction accuracy, but we argue that the resulting abnormal model performance may catch attention easily and invite quick counterattack. Moreover, attacks through modification of existing graph data may be hard to conduct if good security protocols are implemented. In this work, we consider an easier attack harder to be noticed, through adversarially patching the graph with new nodes and edges. The attack is universal: it targets a single node each time and flips its connection to the same set of patch nodes. The attack is unnoticeable: it does not modify the predictions of nodes other than the target. We develop an algorithm, named GUAP, that achieves high attack success rate but meanwhile preserves the prediction accuracy. GUAP is fast to train by employing a sampling strategy. We demonstrate that a 5% sampling in each epoch yields 20x speedup in training, with only a slight degradation in attack performance. Additionally, we show that the adversarial patch trained with the graph convolutional network transfers well to other GNNs, such as the graph attention network.
Robot Motion Planning as Video Prediction: A Spatio-Temporal Neural Network-based Motion Planner
Aug 24, 2022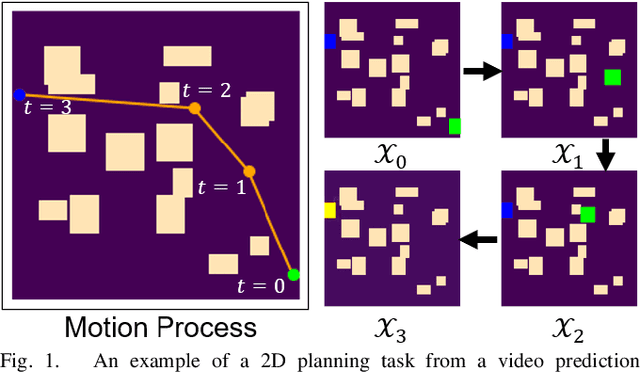
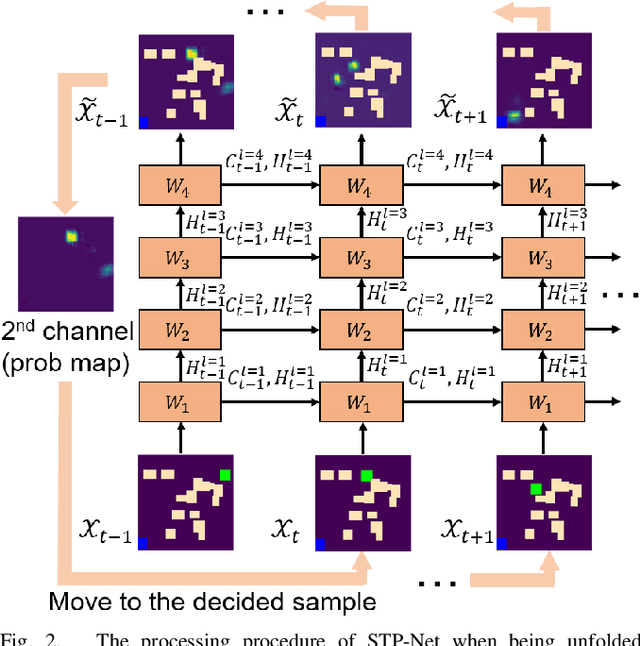
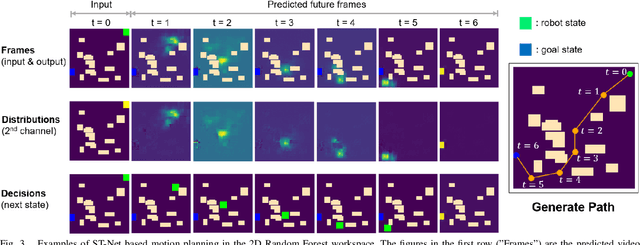
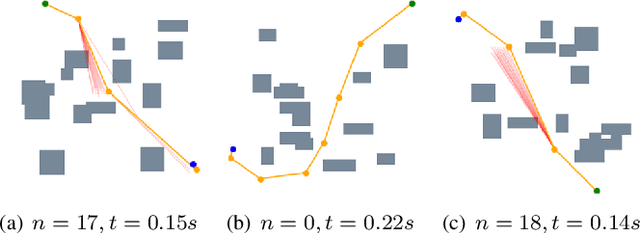
Neural network (NN)-based methods have emerged as an attractive approach for robot motion planning due to strong learning capabilities of NN models and their inherently high parallelism. Despite the current development in this direction, the efficient capture and processing of important sequential and spatial information, in a direct and simultaneous way, is still relatively under-explored. To overcome the challenge and unlock the potentials of neural networks for motion planning tasks, in this paper, we propose STP-Net, an end-to-end learning framework that can fully extract and leverage important spatio-temporal information to form an efficient neural motion planner. By interpreting the movement of the robot as a video clip, robot motion planning is transformed to a video prediction task that can be performed by STP-Net in both spatially and temporally efficient ways. Empirical evaluations across different seen and unseen environments show that, with nearly 100% accuracy (aka, success rate), STP-Net demonstrates very promising performance with respect to both planning speed and path cost. Compared with existing NN-based motion planners, STP-Net achieves at least 5x, 2.6x and 1.8x faster speed with lower path cost on 2D Random Forest, 2D Maze and 3D Random Forest environments, respectively. Furthermore, STP-Net can quickly and simultaneously compute multiple near-optimal paths in multi-robot motion planning tasks
Noise Injection-based Regularization for Point Cloud Processing
Mar 28, 2021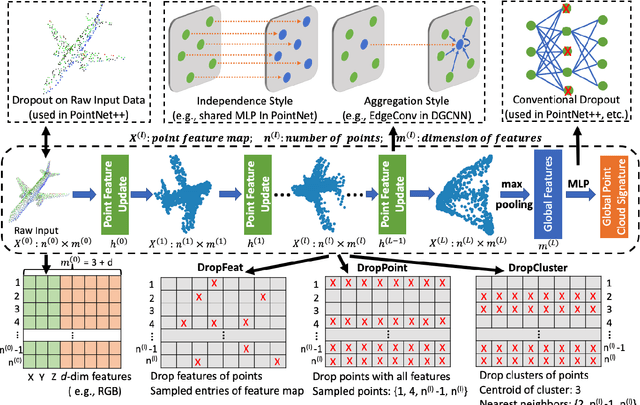
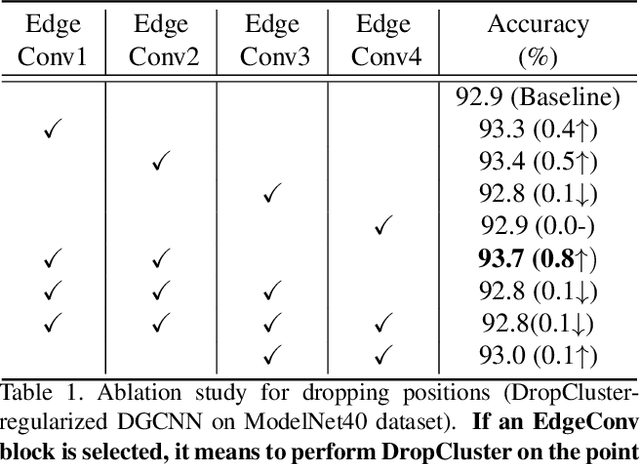
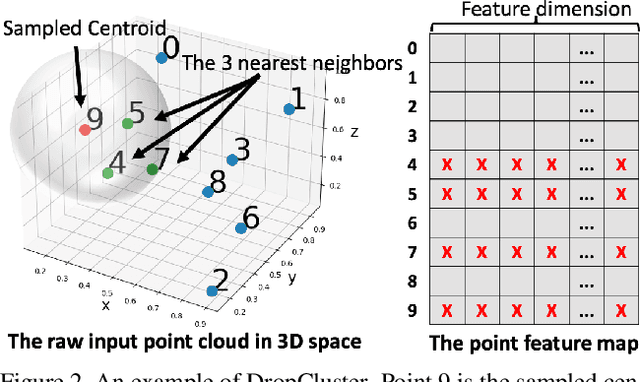
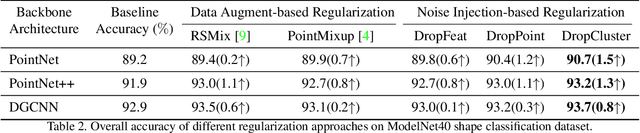
Noise injection-based regularization, such as Dropout, has been widely used in image domain to improve the performance of deep neural networks (DNNs). However, efficient regularization in the point cloud domain is rarely exploited, and most of the state-of-the-art works focus on data augmentation-based regularization. In this paper, we, for the first time, perform systematic investigation on noise injection-based regularization for point cloud-domain DNNs. To be specific, we propose a series of regularization techniques, namely DropFeat, DropPoint and DropCluster, to perform noise injection on the point feature maps at the feature level, point level and cluster level, respectively. We also empirically analyze the impacts of different factors, including dropping rate, cluster size and dropping position, to obtain useful insights and general deployment guidelines, which can facilitate the adoption of our approaches across different datasets and DNN architectures. We evaluate our proposed approaches on various DNN models for different point cloud processing tasks. Experimental results show our approaches enable significant performance improvement. Notably, our DropCluster brings 1.5%, 1.3% and 0.8% higher overall accuracy for PointNet, PointNet++ and DGCNN, respectively, on ModelNet40 shape classification dataset. On ShapeNet part segmentation dataset, DropCluster brings 0.5%, 0.5% and 0.2% mean Intersection-over-union (IoU) increase for PointNet, PointNet++ and DGCNN, respectively. On S3DIS semantic segmentation dataset, DropCluster improves the mean IoU of PointNet, PointNet++ and DGCNN by 3.2%, 2.9% and 3.7%, respectively. Meanwhile, DropCluster also enables the overall accuracy increase for these three popular backbone DNNs by 2.4%, 2.2% and 1.8%, respectively.
Graph Universal Adversarial Attacks: A Few Bad Actors Ruin Graph Learning Models
Feb 12, 2020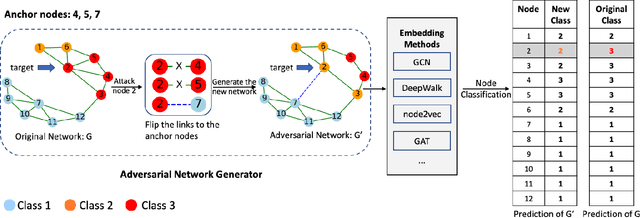
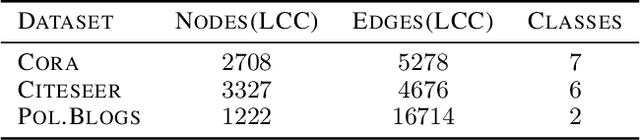

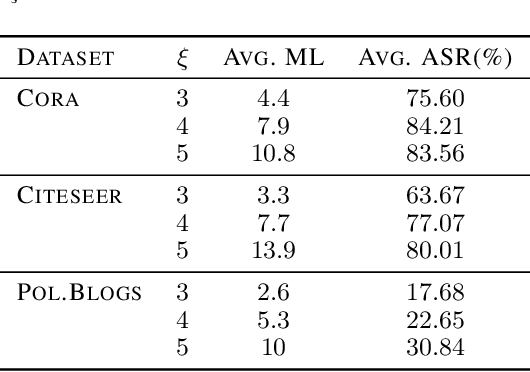
Deep neural networks, while generalize well, are known to be sensitive to small adversarial perturbations. This phenomenon poses severe security threat and calls for in-depth investigation of the robustness of deep learning models. With the emergence of neural networks for graph structured data, similar investigations are urged to understand their robustness. It has been found that adversarially perturbing the graph structure and/or node features may result in a significant degradation of the model performance. In this work, we show from a different angle that such fragility similarly occurs if the graph contains a few bad-actor nodes, which compromise a trained graph neural network through flipping the connections to any targeted victim. Worse, the bad actors found for one graph model severely compromise other models as well. We call the bad actors "anchor nodes" and propose an algorithm, named GUA, to identify them. Thorough empirical investigations suggest an interesting finding that the anchor nodes often belong to the same class; and they also corroborate the intuitive trade-off between the number of anchor nodes and the attack success rate. For the data set Cora which contains 2708 nodes, as few as six anchor nodes will result in an attack success rate higher than 80\% for GCN and other three models.