 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Wisdom of the Crowd: High-Fidelity Classification of Cyber-Attacks and Faults in Power Systems Using Ensemble and Machine Learning
Nov 10, 2025This paper presents a high-fidelity evaluation framework for machine learning (ML)-based classification of cyber-attacks and physical faults using electromagnetic transient simulations with digital substation emulation at 4.8 kHz. Twelve ML models, including ensemble algorithms and a multi-layer perceptron (MLP), were trained on labeled time-domain measurements and evaluated in a real-time streaming environment designed for sub-cycle responsiveness. The architecture incorporates a cycle-length smoothing filter and confidence threshold to stabilize decisions. Results show that while several models achieved near-perfect offline accuracies (up to 99.9%), only the MLP sustained robust coverage (98-99%) under streaming, whereas ensembles preserved perfect anomaly precision but abstained frequently (10-49% coverage). These findings demonstrate that offline accuracy alone is an unreliable indicator of field readiness and underscore the need for realistic testing and inference pipelines to ensure dependable classification in inverter-based resources (IBR)-rich networks.
Why Don't You Clean Your Glasses? Perception Attacks with Dynamic Optical Perturbations
Jul 27, 2023



Camera-based autonomous systems that emulate human perception are increasingly being integrated into safety-critical platforms. Consequently, an established body of literature has emerged that explores adversarial attacks targeting the underlying machine learning models. Adapting adversarial attacks to the physical world is desirable for the attacker, as this removes the need to compromise digital systems. However, the real world poses challenges related to the "survivability" of adversarial manipulations given environmental noise in perception pipelines and the dynamicity of autonomous systems. In this paper, we take a sensor-first approach. We present EvilEye, a man-in-the-middle perception attack that leverages transparent displays to generate dynamic physical adversarial examples. EvilEye exploits the camera's optics to induce misclassifications under a variety of illumination conditions. To generate dynamic perturbations, we formalize the projection of a digital attack into the physical domain by modeling the transformation function of the captured image through the optical pipeline. Our extensive experiments show that EvilEye's generated adversarial perturbations are much more robust across varying environmental light conditions relative to existing physical perturbation frameworks, achieving a high attack success rate (ASR) while bypassing state-of-the-art physical adversarial detection frameworks. We demonstrate that the dynamic nature of EvilEye enables attackers to adapt adversarial examples across a variety of objects with a significantly higher ASR compared to state-of-the-art physical world attack frameworks. Finally, we discuss mitigation strategies against the EvilEye attack.
CSTAR: Towards Compact and STructured Deep Neural Networks with Adversarial Robustness
Dec 04, 2022
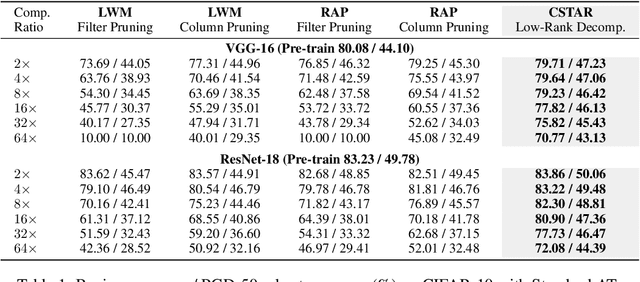


Model compression and model defense for deep neural networks (DNNs) have been extensively and individually studied. Considering the co-importance of model compactness and robustness in practical applications, several prior works have explored to improve the adversarial robustness of the sparse neural networks. However, the structured sparse models obtained by the exiting works suffer severe performance degradation for both benign and robust accuracy, thereby causing a challenging dilemma between robustness and structuredness of the compact DNNs. To address this problem, in this paper, we propose CSTAR, an efficient solution that can simultaneously impose the low-rankness-based Compactness, high STructuredness and high Adversarial Robustness on the target DNN models. By formulating the low-rankness and robustness requirement within the same framework and globally determining the ranks, the compressed DNNs can simultaneously achieve high compression performance and strong adversarial robustness. Evaluations for various DNN models on different datasets demonstrate the effectiveness of CSTAR. Compared with the state-of-the-art robust structured pruning methods, CSTAR shows consistently better performance. For instance, when compressing ResNet-18 on CIFAR-10, CSTAR can achieve up to 20.07% and 11.91% improvement for benign accuracy and robust accuracy, respectively. For compressing ResNet-18 with 16x compression ratio on Imagenet, CSTAR can obtain 8.58% benign accuracy gain and 4.27% robust accuracy gain compared to the existing robust structured pruning method.
Robot Motion Planning as Video Prediction: A Spatio-Temporal Neural Network-based Motion Planner
Aug 24, 2022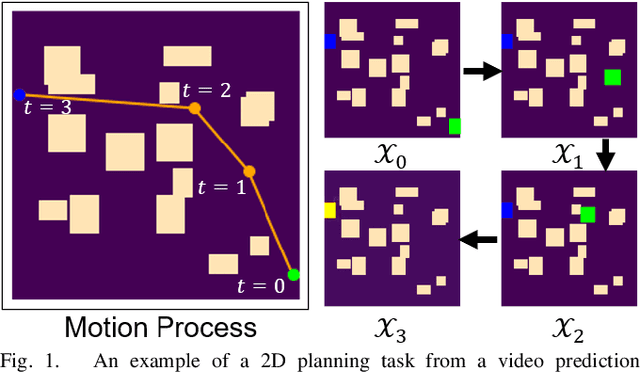
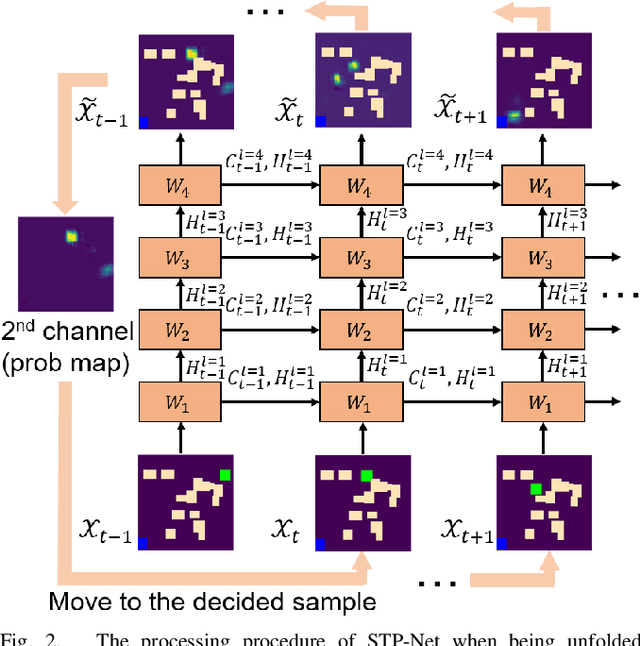
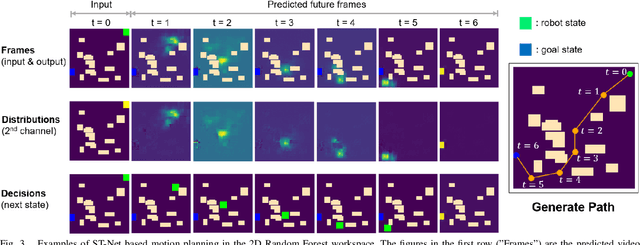
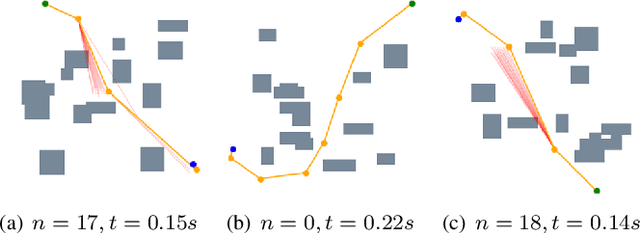
Neural network (NN)-based methods have emerged as an attractive approach for robot motion planning due to strong learning capabilities of NN models and their inherently high parallelism. Despite the current development in this direction, the efficient capture and processing of important sequential and spatial information, in a direct and simultaneous way, is still relatively under-explored. To overcome the challenge and unlock the potentials of neural networks for motion planning tasks, in this paper, we propose STP-Net, an end-to-end learning framework that can fully extract and leverage important spatio-temporal information to form an efficient neural motion planner. By interpreting the movement of the robot as a video clip, robot motion planning is transformed to a video prediction task that can be performed by STP-Net in both spatially and temporally efficient ways. Empirical evaluations across different seen and unseen environments show that, with nearly 100% accuracy (aka, success rate), STP-Net demonstrates very promising performance with respect to both planning speed and path cost. Compared with existing NN-based motion planners, STP-Net achieves at least 5x, 2.6x and 1.8x faster speed with lower path cost on 2D Random Forest, 2D Maze and 3D Random Forest environments, respectively. Furthermore, STP-Net can quickly and simultaneously compute multiple near-optimal paths in multi-robot motion planning tasks
CHIP: CHannel Independence-based Pruning for Compact Neural Networks
Oct 26, 2021
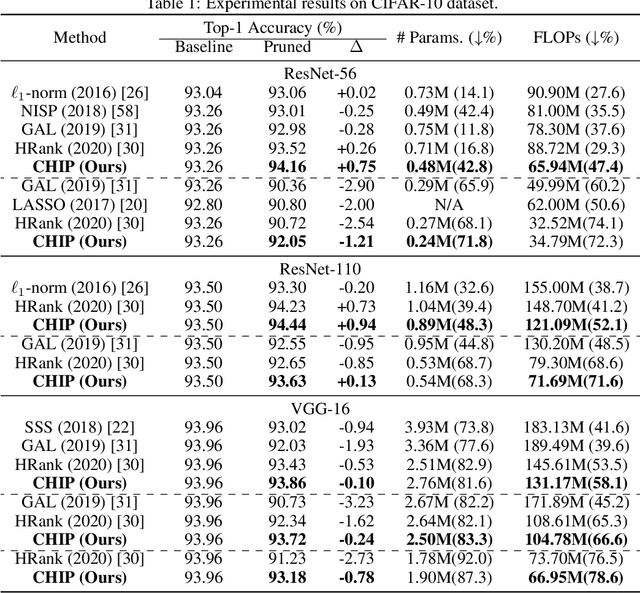
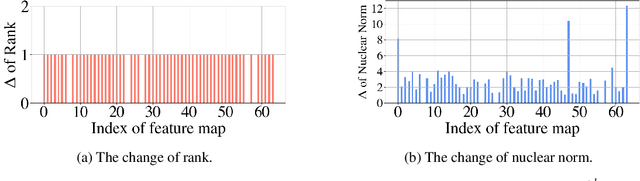

Filter pruning has been widely used for neural network compression because of its enabled practical acceleration. To date, most of the existing filter pruning works explore the importance of filters via using intra-channel information. In this paper, starting from an inter-channel perspective, we propose to perform efficient filter pruning using Channel Independence, a metric that measures the correlations among different feature maps. The less independent feature map is interpreted as containing less useful information$/$knowledge, and hence its corresponding filter can be pruned without affecting model capacity. We systematically investigate the quantification metric, measuring scheme and sensitiveness$/$reliability of channel independence in the context of filter pruning. Our evaluation results for different models on various datasets show the superior performance of our approach. Notably, on CIFAR-10 dataset our solution can bring $0.75\%$ and $0.94\%$ accuracy increase over baseline ResNet-56 and ResNet-110 models, respectively, and meanwhile the model size and FLOPs are reduced by $42.8\%$ and $47.4\%$ (for ResNet-56) and $48.3\%$ and $52.1\%$ (for ResNet-110), respectively. On ImageNet dataset, our approach can achieve $40.8\%$ and $44.8\%$ storage and computation reductions, respectively, with $0.15\%$ accuracy increase over the baseline ResNet-50 model. The code is available at https://github.com/Eclipsess/CHIP_NeurIPS2021.
Multi-Source Data Fusion for Cyberattack Detection in Power Systems
Jan 18, 2021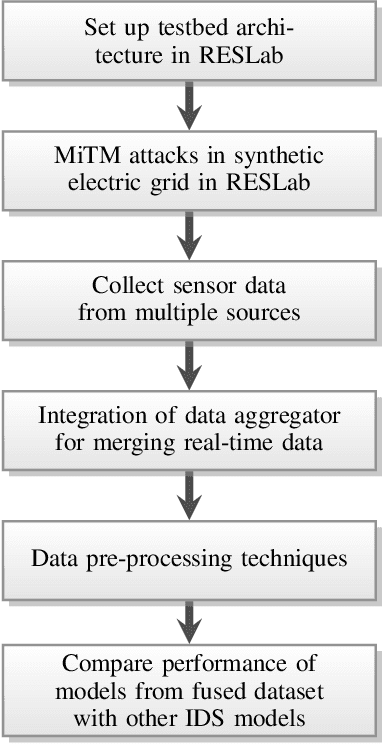
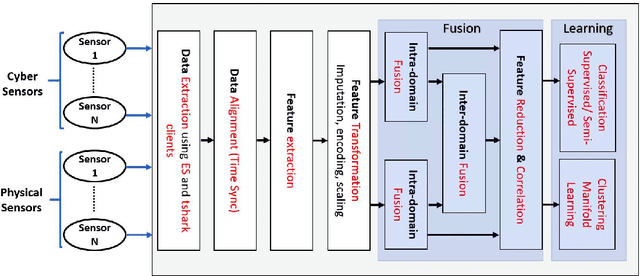
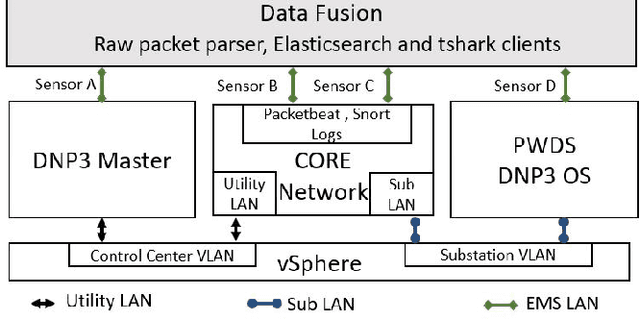
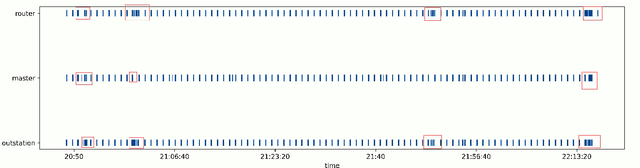
Cyberattacks can cause a severe impact on power systems unless detected early. However, accurate and timely detection in critical infrastructure systems presents challenges, e.g., due to zero-day vulnerability exploitations and the cyber-physical nature of the system coupled with the need for high reliability and resilience of the physical system. Conventional rule-based and anomaly-based intrusion detection system (IDS) tools are insufficient for detecting zero-day cyber intrusions in the industrial control system (ICS) networks. Hence, in this work, we show that fusing information from multiple data sources can help identify cyber-induced incidents and reduce false positives. Specifically, we present how to recognize and address the barriers that can prevent the accurate use of multiple data sources for fusion-based detection. We perform multi-source data fusion for training IDS in a cyber-physical power system testbed where we collect cyber and physical side data from multiple sensors emulating real-world data sources that would be found in a utility and synthesizes these into features for algorithms to detect intrusions. Results are presented using the proposed data fusion application to infer False Data and Command injection-based Man-in- The-Middle (MiTM) attacks. Post collection, the data fusion application uses time-synchronized merge and extracts features followed by pre-processing such as imputation and encoding before training supervised, semi-supervised, and unsupervised learning models to evaluate the performance of the IDS. A major finding is the improvement of detection accuracy by fusion of features from cyber, security, and physical domains. Additionally, we observed the co-training technique performs at par with supervised learning methods when fed with our features.
On-board Deep-learning-based Unmanned Aerial Vehicle Fault Cause Detection and Identification
Apr 03, 2020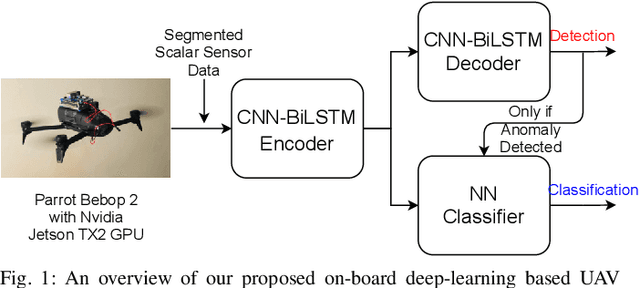
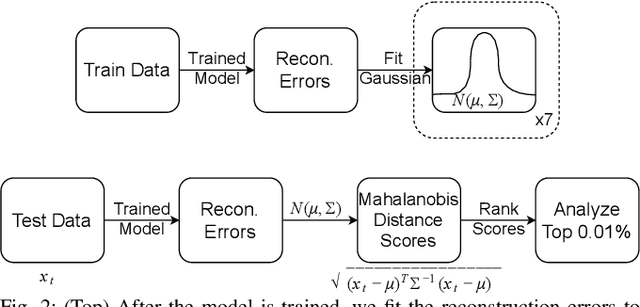
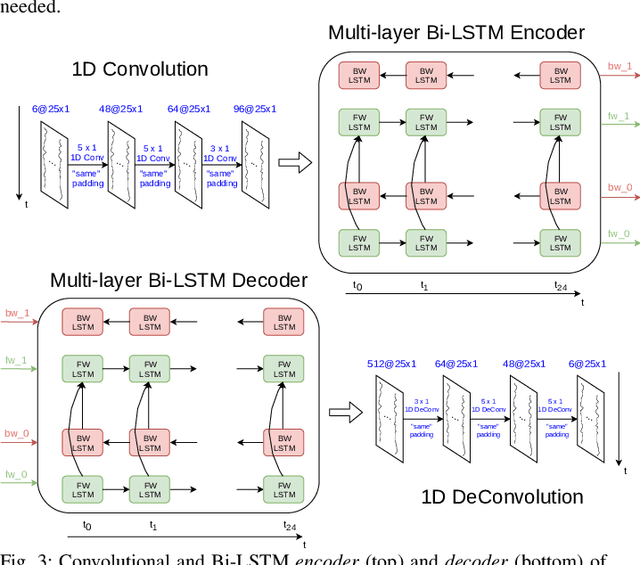

With the increase in use of Unmanned Aerial Vehicles (UAVs)/drones, it is important to detect and identify causes of failure in real time for proper recovery from a potential crash-like scenario or post incident forensics analysis. The cause of crash could be either a fault in the sensor/actuator system, a physical damage/attack, or a cyber attack on the drone's software. In this paper, we propose novel architectures based on deep Convolutional and Long Short-Term Memory Neural Networks (CNNs and LSTMs) to detect (via Autoencoder) and classify drone mis-operations based on sensor data. The proposed architectures are able to learn high-level features automatically from the raw sensor data and learn the spatial and temporal dynamics in the sensor data. We validate the proposed deep-learning architectures via simulations and experiments on a real drone. Empirical results show that our solution is able to detect with over 90% accuracy and classify various types of drone mis-operations (with about 99% accuracy (simulation data) and upto 88% accuracy (experimental data)).
HCFContext: Smartphone Context Inference via Sequential History-based Collaborative Filtering
Apr 29, 2019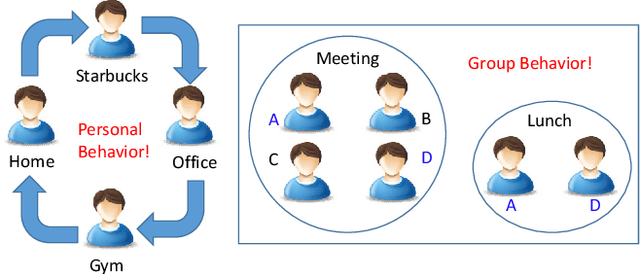
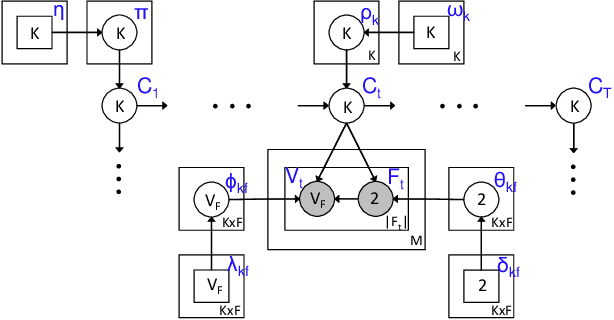
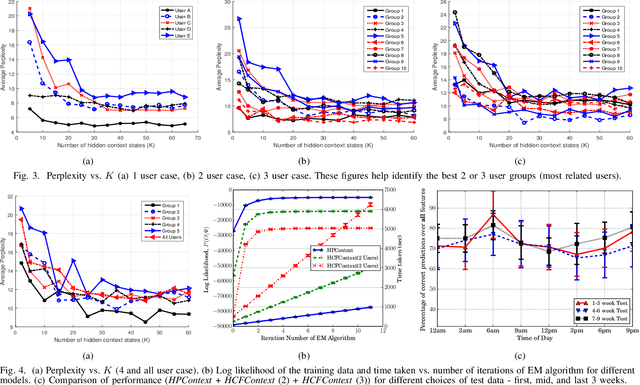
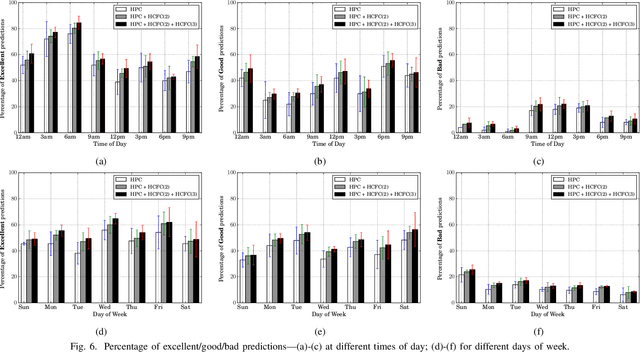
Mobile context determination is an important step for many context aware services such as location-based services, enterprise policy enforcement, building or room occupancy detection for power or HVAC operation, etc. Especially in enterprise scenarios where policies (e.g., attending a confidential meeting only when the user is in "Location X") are defined based on mobile context, it is paramount to verify the accuracy of the mobile context. To this end, two stochastic models based on the theory of Hidden Markov Models (HMMs) to obtain mobile context are proposed-personalized model (HPContext) and collaborative filtering model (HCFContext). The former predicts the current context using sequential history of the user's past context observations, the latter enhances HPContext with collaborative filtering features, which enables it to predict the current context of the primary user based on the context observations of users related to the primary user, e.g., same team colleagues in company, gym friends, family members, etc. Each of the proposed models can also be used to enhance or complement the context obtained from sensors. Furthermore, since privacy is a concern in collaborative filtering, a privacy-preserving method is proposed to derive HCFContext model parameters based on the concepts of homomorphic encryption. Finally, these models are thoroughly validated on a real-life dataset.
* Mobile context, collaborative filtering, privacy-preserving, personalized model, sensors, location, prediction, hidden markov models, google now, apple siri, cortana, alexa
CollabLoc: Privacy-Preserving Multi-Modal Localization via Collaborative Information Fusion
Sep 29, 2017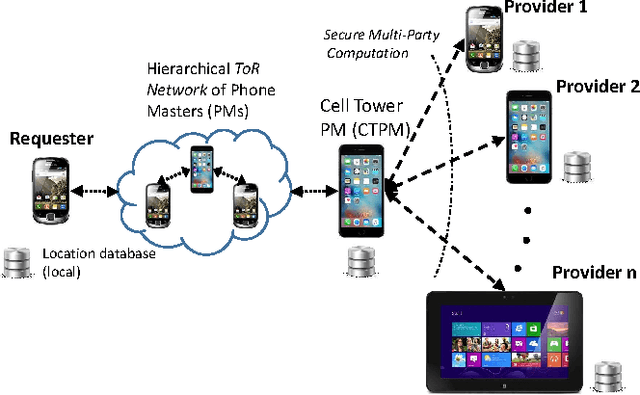
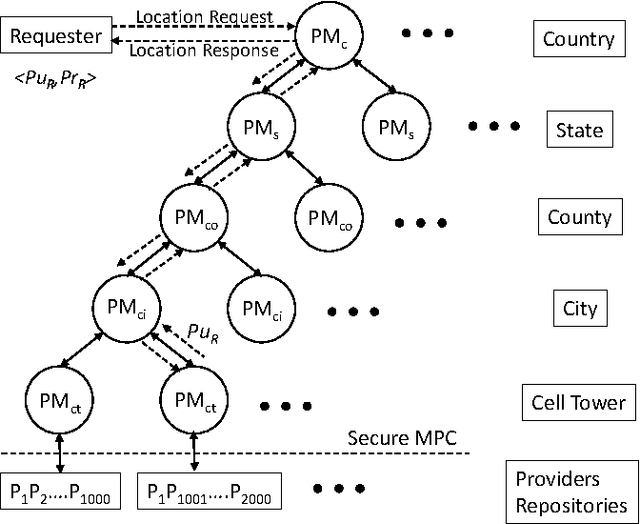
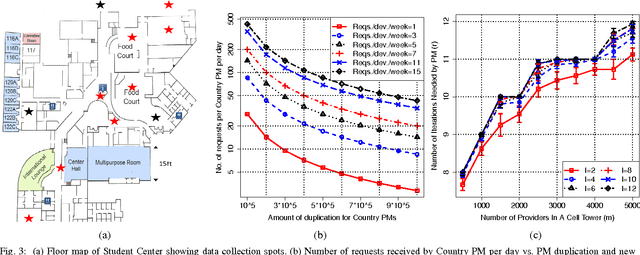
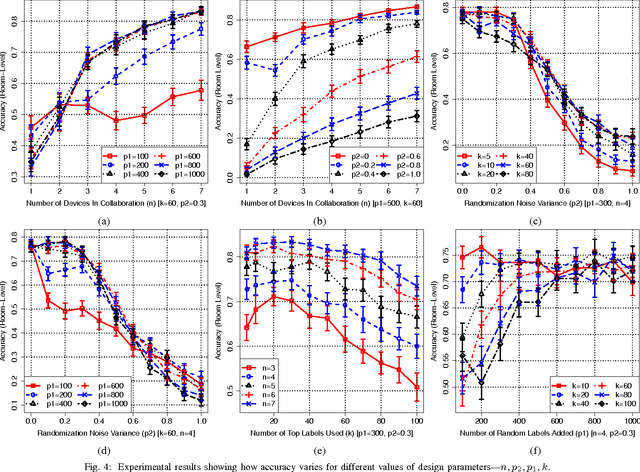
Mobile phones provide an excellent opportunity for building context-aware applications. In particular, location-based services are important context-aware services that are more and more used for enforcing security policies, for supporting indoor room navigation, and for providing personalized assistance. However, a major problem still remains unaddressed---the lack of solutions that work across buildings while not using additional infrastructure and also accounting for privacy and reliability needs. In this paper, a privacy-preserving, multi-modal, cross-building, collaborative localization platform is proposed based on Wi-Fi RSSI (existing infrastructure), Cellular RSSI, sound and light levels, that enables room-level localization as main application (though sub room level granularity is possible). The privacy is inherently built into the solution based on onion routing, and perturbation/randomization techniques, and exploits the idea of weighted collaboration to increase the reliability as well as to limit the effect of noisy devices (due to sensor noise/privacy). The proposed solution has been analyzed in terms of privacy, accuracy, optimum parameters, and other overheads on location data collected at multiple indoor and outdoor locations using an Android app.