 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlock Circulant Adapter for Large Language Models
May 01, 2025Fine-tuning large language models (LLMs) is difficult due to their huge model size. Recent Fourier domain-based methods show potential for reducing fine-tuning costs. We propose a block circulant matrix-based fine-tuning method with a stable training heuristic to leverage the properties of circulant matrices and one-dimensional Fourier transforms to reduce storage and computation costs. Experiments show that our method uses $14\times$ less number of parameters than VeRA, $16\times$ smaller than LoRA and $32\times$ less FLOPs than FourierFT, while maintaining close or better task performance. Our approach presents a promising way in frequency domain to fine-tune large models on downstream tasks.
Parameter-Efficient Fine-Tuning with Circulant and Diagonal Vectors
May 01, 2025Foundation models have achieved tremendous success in different domains. However, their huge computation and storage complexity make these models difficult to fine-tune and also less applicable in practice. Recent study shows training in Fourier domain can be an effective fine-tuning method in terms of both model performance and number of training parameters. In this work, we propose to further reduce the complexity by the factorization through the product of interleaved circulant and diagonal matrices. In addition, we address the case of non-square fine-tuning weights by partitioning the circulant matrix into blocks. Our method avoids the construction of weight change matrix and utilizes 1D fast Fourier transform (FFT) instead of 2D FFT. Experimental results show that our method achieves similar or better performance across various tasks with much less floating-point operations (FLOPs) and the number of trainable parameters.
Towards Efficient Tensor Decomposition-Based DNN Model Compression with Optimization Framework
Jul 26, 2021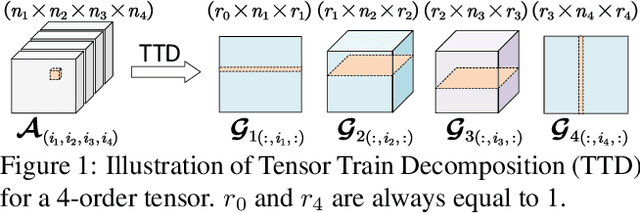
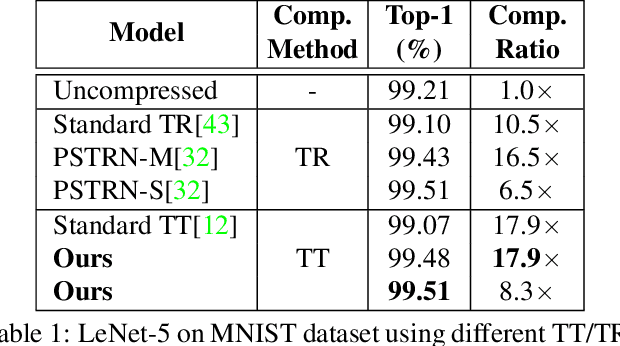
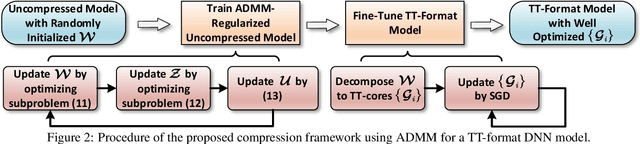
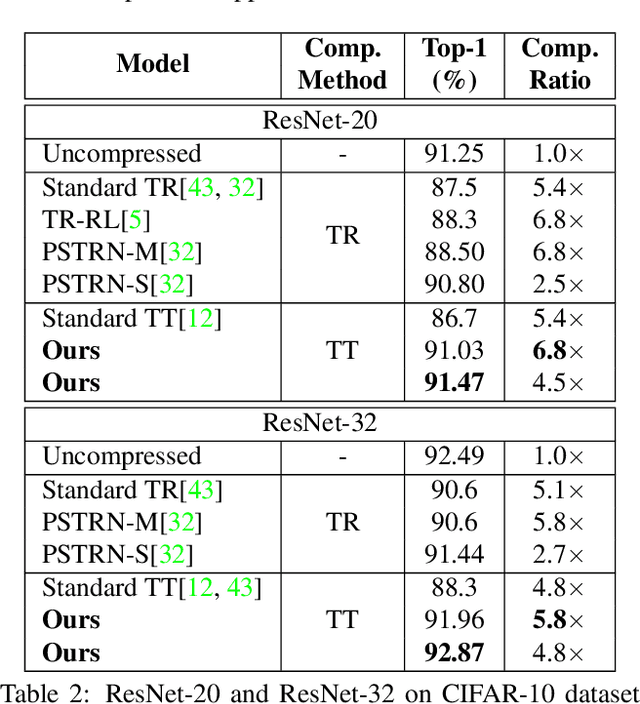
Advanced tensor decomposition, such as Tensor train (TT) and Tensor ring (TR), has been widely studied for deep neural network (DNN) model compression, especially for recurrent neural networks (RNNs). However, compressing convolutional neural networks (CNNs) using TT/TR always suffers significant accuracy loss. In this paper, we propose a systematic framework for tensor decomposition-based model compression using Alternating Direction Method of Multipliers (ADMM). By formulating TT decomposition-based model compression to an optimization problem with constraints on tensor ranks, we leverage ADMM technique to systemically solve this optimization problem in an iterative way. During this procedure, the entire DNN model is trained in the original structure instead of TT format, but gradually enjoys the desired low tensor rank characteristics. We then decompose this uncompressed model to TT format and fine-tune it to finally obtain a high-accuracy TT-format DNN model. Our framework is very general, and it works for both CNNs and RNNs, and can be easily modified to fit other tensor decomposition approaches. We evaluate our proposed framework on different DNN models for image classification and video recognition tasks. Experimental results show that our ADMM-based TT-format models demonstrate very high compression performance with high accuracy. Notably, on CIFAR-100, with 2.3X and 2.4X compression ratios, our models have 1.96% and 2.21% higher top-1 accuracy than the original ResNet-20 and ResNet-32, respectively. For compressing ResNet-18 on ImageNet, our model achieves 2.47X FLOPs reduction without accuracy loss.
Towards Extremely Compact RNNs for Video Recognition with Fully Decomposed Hierarchical Tucker Structure
Apr 20, 2021
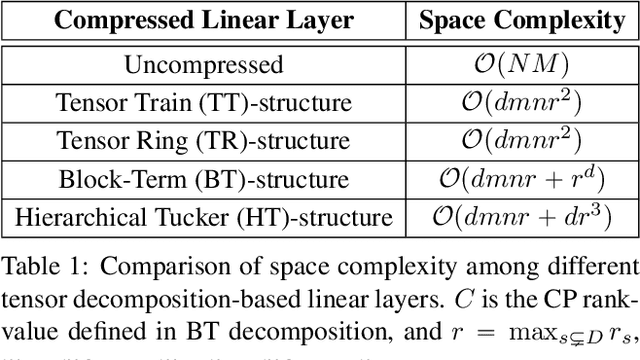
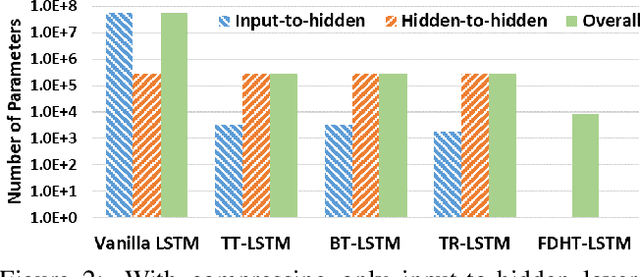
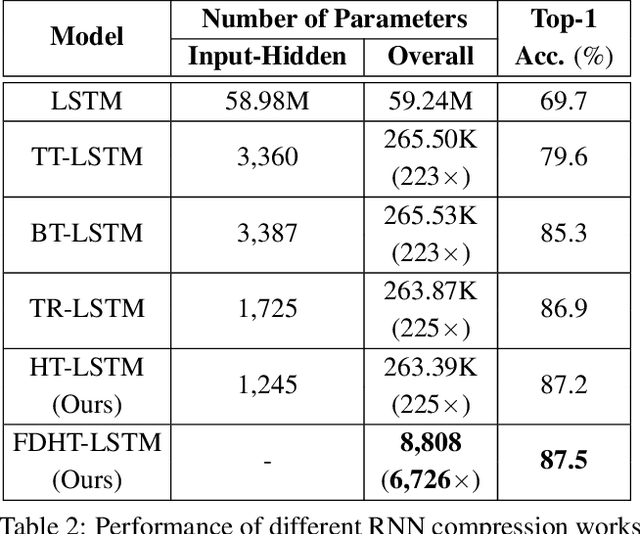
Recurrent Neural Networks (RNNs) have been widely used in sequence analysis and modeling. However, when processing high-dimensional data, RNNs typically require very large model sizes, thereby bringing a series of deployment challenges. Although various prior works have been proposed to reduce the RNN model sizes, executing RNN models in resource-restricted environments is still a very challenging problem. In this paper, we propose to develop extremely compact RNN models with fully decomposed hierarchical Tucker (FDHT) structure. The HT decomposition does not only provide much higher storage cost reduction than the other tensor decomposition approaches but also brings better accuracy performance improvement for the compact RNN models. Meanwhile, unlike the existing tensor decomposition-based methods that can only decompose the input-to-hidden layer of RNNs, our proposed fully decomposition approach enables the comprehensive compression for the entire RNN models with maintaining very high accuracy. Our experimental results on several popular video recognition datasets show that our proposed fully decomposed hierarchical tucker-based LSTM (FDHT-LSTM) is extremely compact and highly efficient. To the best of our knowledge, FDHT-LSTM, for the first time, consistently achieves very high accuracy with only few thousand parameters (3,132 to 8,808) on different datasets. Compared with the state-of-the-art compressed RNN models, such as TT-LSTM, TR-LSTM and BT-LSTM, our FDHT-LSTM simultaneously enjoys both order-of-magnitude (3,985x to 10,711x) fewer parameters and significant accuracy improvement (0.6% to 12.7%).
Noise Injection-based Regularization for Point Cloud Processing
Mar 28, 2021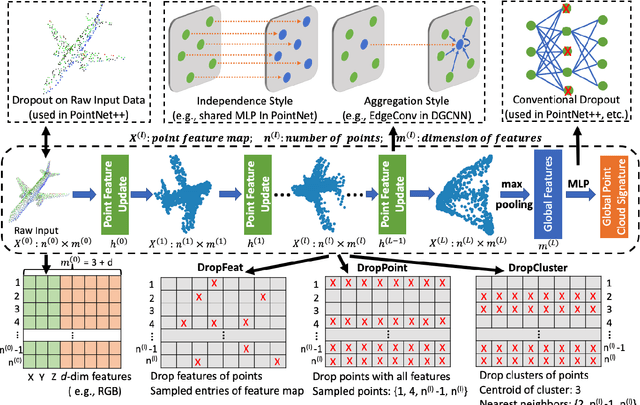
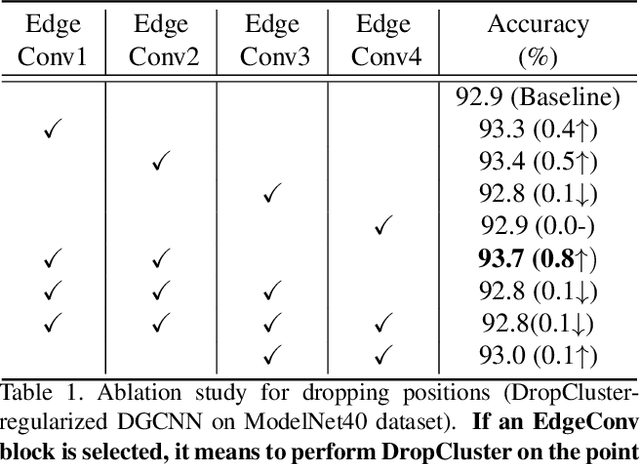
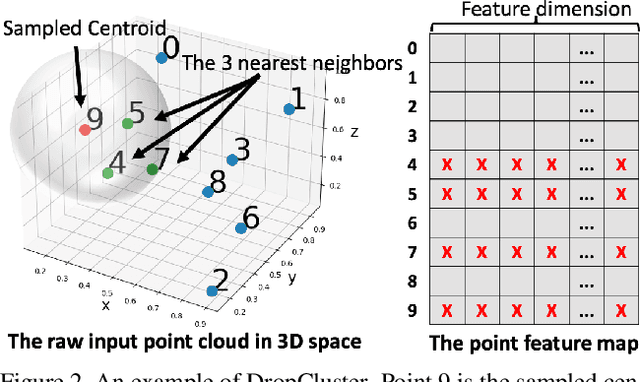
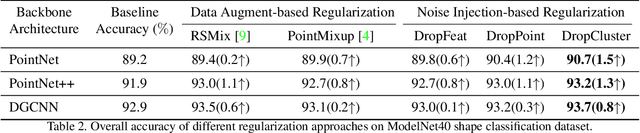
Noise injection-based regularization, such as Dropout, has been widely used in image domain to improve the performance of deep neural networks (DNNs). However, efficient regularization in the point cloud domain is rarely exploited, and most of the state-of-the-art works focus on data augmentation-based regularization. In this paper, we, for the first time, perform systematic investigation on noise injection-based regularization for point cloud-domain DNNs. To be specific, we propose a series of regularization techniques, namely DropFeat, DropPoint and DropCluster, to perform noise injection on the point feature maps at the feature level, point level and cluster level, respectively. We also empirically analyze the impacts of different factors, including dropping rate, cluster size and dropping position, to obtain useful insights and general deployment guidelines, which can facilitate the adoption of our approaches across different datasets and DNN architectures. We evaluate our proposed approaches on various DNN models for different point cloud processing tasks. Experimental results show our approaches enable significant performance improvement. Notably, our DropCluster brings 1.5%, 1.3% and 0.8% higher overall accuracy for PointNet, PointNet++ and DGCNN, respectively, on ModelNet40 shape classification dataset. On ShapeNet part segmentation dataset, DropCluster brings 0.5%, 0.5% and 0.2% mean Intersection-over-union (IoU) increase for PointNet, PointNet++ and DGCNN, respectively. On S3DIS semantic segmentation dataset, DropCluster improves the mean IoU of PointNet, PointNet++ and DGCNN by 3.2%, 2.9% and 3.7%, respectively. Meanwhile, DropCluster also enables the overall accuracy increase for these three popular backbone DNNs by 2.4%, 2.2% and 1.8%, respectively.
Doubly Residual Neural Decoder: Towards Low-Complexity High-Performance Channel Decoding
Feb 08, 2021
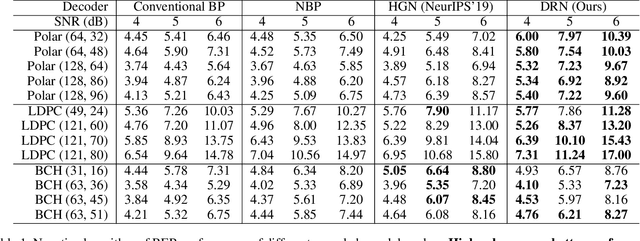
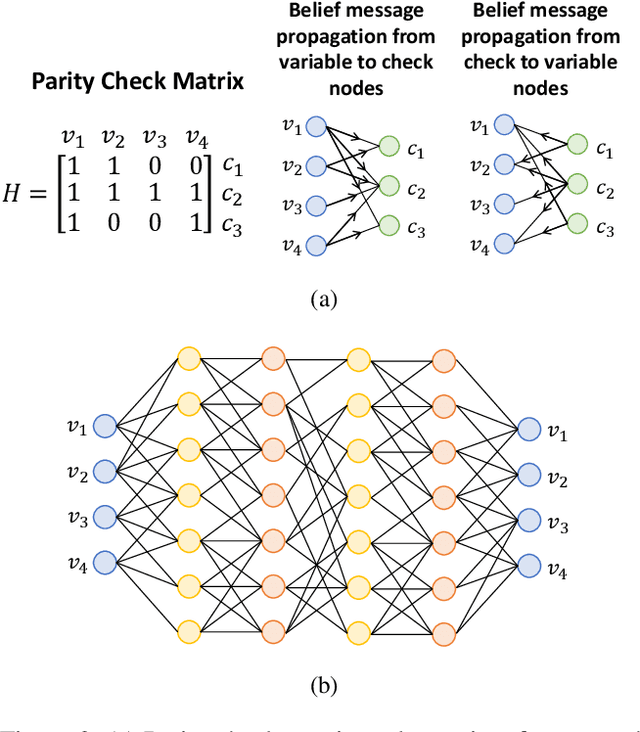
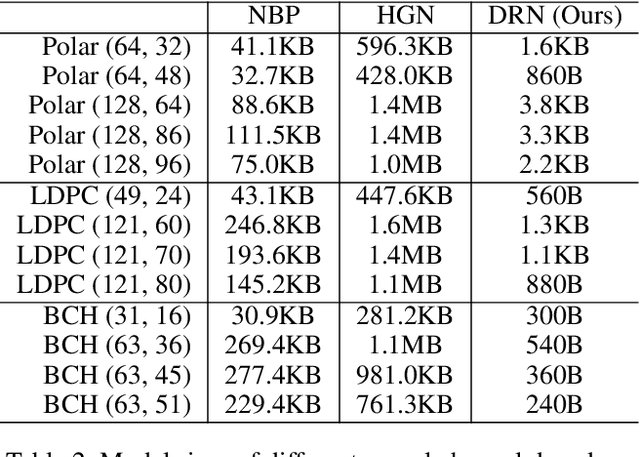
Recently deep neural networks have been successfully applied in channel coding to improve the decoding performance. However, the state-of-the-art neural channel decoders cannot achieve high decoding performance and low complexity simultaneously. To overcome this challenge, in this paper we propose doubly residual neural (DRN) decoder. By integrating both the residual input and residual learning to the design of neural channel decoder, DRN enables significant decoding performance improvement while maintaining low complexity. Extensive experiment results show that on different types of channel codes, our DRN decoder consistently outperform the state-of-the-art decoders in terms of decoding performance, model sizes and computational cost.
Compressing Recurrent Neural Networks Using Hierarchical Tucker Tensor Decomposition
May 09, 2020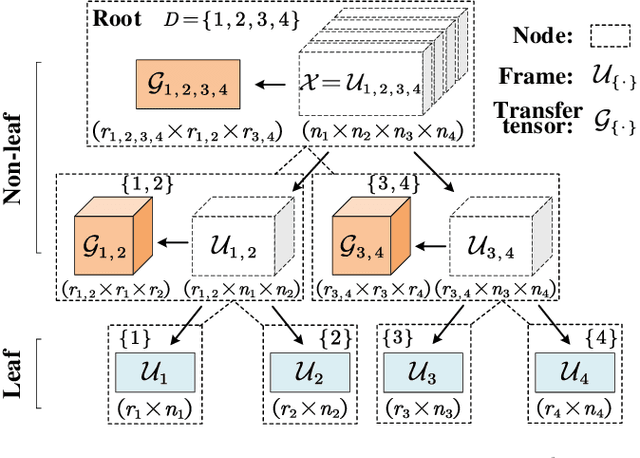
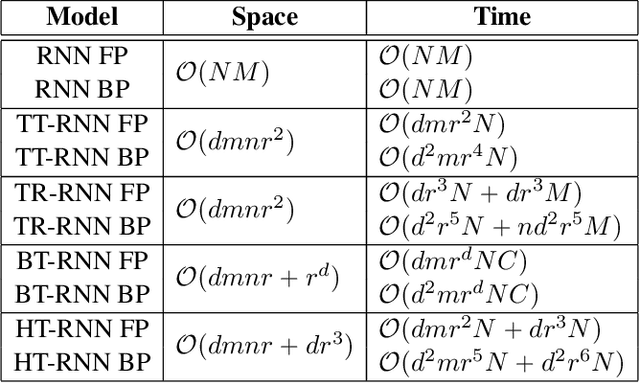
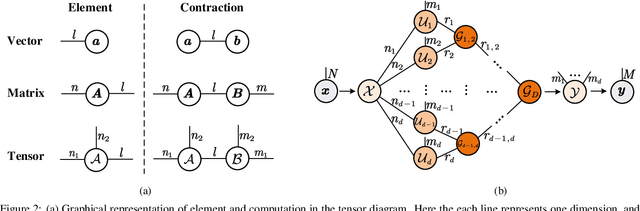
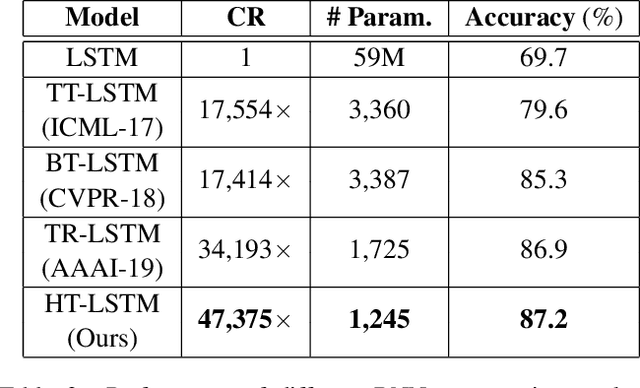
Recurrent Neural Networks (RNNs) have been widely used in sequence analysis and modeling. However, when processing high-dimensional data, RNNs typically require very large model sizes, thereby bringing a series of deployment challenges. Although the state-of-the-art tensor decomposition approaches can provide good model compression performance, these existing methods are still suffering some inherent limitations, such as restricted representation capability and insufficient model complexity reduction. To overcome these limitations, in this paper we propose to develop compact RNN models using Hierarchical Tucker (HT) decomposition. HT decomposition brings strong hierarchical structure to the decomposed RNN models, which is very useful and important for enhancing the representation capability. Meanwhile, HT decomposition provides higher storage and computational cost reduction than the existing tensor decomposition approaches for RNN compression. Our experimental results show that, compared with the state-of-the-art compressed RNN models, such as TT-LSTM, TR-LSTM and BT-LSTM, our proposed HT-based LSTM (HT-LSTM), consistently achieves simultaneous and significant increases in both compression ratio and test accuracy on different datasets.
PERMDNN: Efficient Compressed DNN Architecture with Permuted Diagonal Matrices
Apr 23, 2020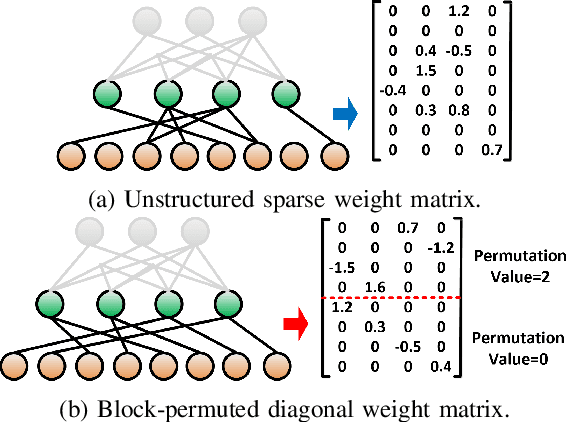
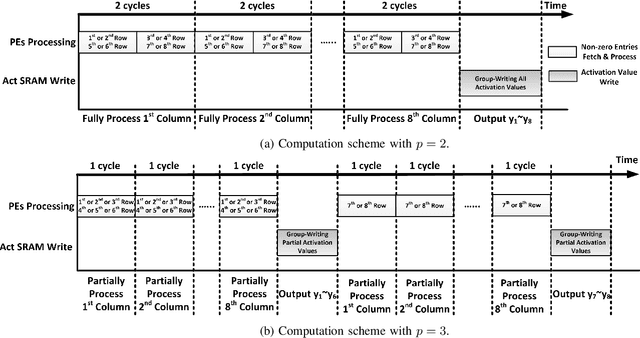

Deep neural network (DNN) has emerged as the most important and popular artificial intelligent (AI) technique. The growth of model size poses a key energy efficiency challenge for the underlying computing platform. Thus, model compression becomes a crucial problem. However, the current approaches are limited by various drawbacks. Specifically, network sparsification approach suffers from irregularity, heuristic nature and large indexing overhead. On the other hand, the recent structured matrix-based approach (i.e., CirCNN) is limited by the relatively complex arithmetic computation (i.e., FFT), less flexible compression ratio, and its inability to fully utilize input sparsity. To address these drawbacks, this paper proposes PermDNN, a novel approach to generate and execute hardware-friendly structured sparse DNN models using permuted diagonal matrices. Compared with unstructured sparsification approach, PermDNN eliminates the drawbacks of indexing overhead, non-heuristic compression effects and time-consuming retraining. Compared with circulant structure-imposing approach, PermDNN enjoys the benefits of higher reduction in computational complexity, flexible compression ratio, simple arithmetic computation and full utilization of input sparsity. We propose PermDNN architecture, a multi-processing element (PE) fully-connected (FC) layer-targeted computing engine. The entire architecture is highly scalable and flexible, and hence it can support the needs of different applications with different model configurations. We implement a 32-PE design using CMOS 28nm technology. Compared with EIE, PermDNN achieves 3.3x~4.8x higher throughout, 5.9x~8.5x better area efficiency and 2.8x~4.0x better energy efficiency on different workloads. Compared with CirCNN, PermDNN achieves 11.51x higher throughput and 3.89x better energy efficiency.
Embedding Compression with Isotropic Iterative Quantization
Jan 23, 2020
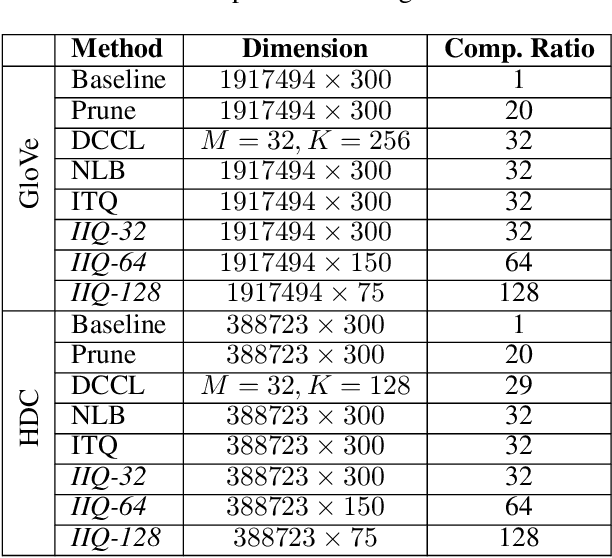
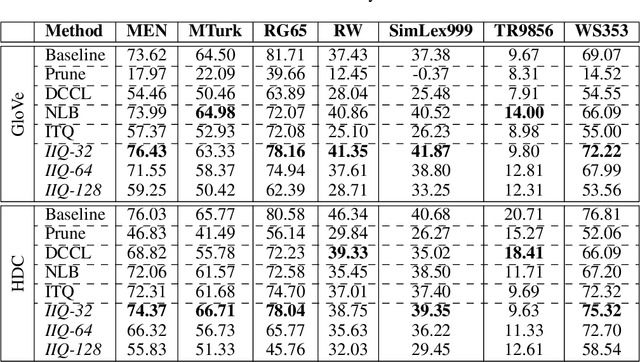
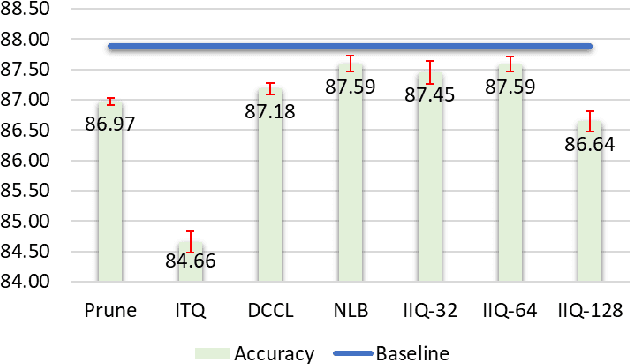
Continuous representation of words is a standard component in deep learning-based NLP models. However, representing a large vocabulary requires significant memory, which can cause problems, particularly on resource-constrained platforms. Therefore, in this paper we propose an isotropic iterative quantization (IIQ) approach for compressing embedding vectors into binary ones, leveraging the iterative quantization technique well established for image retrieval, while satisfying the desired isotropic property of PMI based models. Experiments with pre-trained embeddings (i.e., GloVe and HDC) demonstrate a more than thirty-fold compression ratio with comparable and sometimes even improved performance over the original real-valued embedding vectors.
CAG: A Real-time Low-cost Enhanced-robustness High-transferability Content-aware Adversarial Attack Generator
Dec 16, 2019
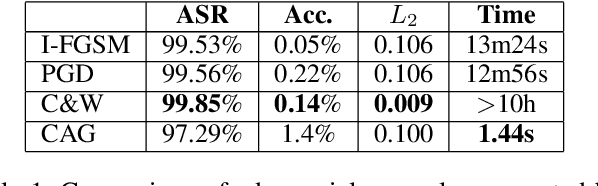
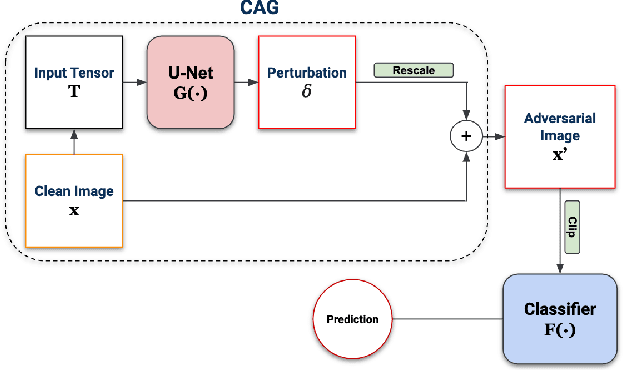
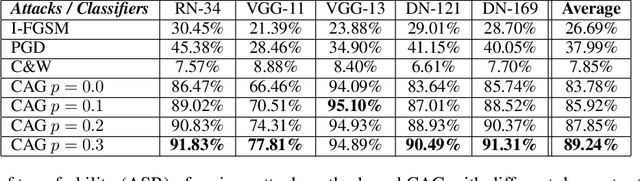
Deep neural networks (DNNs) are vulnerable to adversarial attack despite their tremendous success in many AI fields. Adversarial attack is a method that causes the intended misclassfication by adding imperceptible perturbations to legitimate inputs. Researchers have developed numerous types of adversarial attack methods. However, from the perspective of practical deployment, these methods suffer from several drawbacks such as long attack generating time, high memory cost, insufficient robustness and low transferability. We propose a Content-aware Adversarial Attack Generator (CAG) to achieve real-time, low-cost, enhanced-robustness and high-transferability adversarial attack. First, as a type of generative model-based attack, CAG shows significant speedup (at least 500 times) in generating adversarial examples compared to the state-of-the-art attacks such as PGD and C\&W. CAG only needs a single generative model to perform targeted attack to any targeted class. Because CAG encodes the label information into a trainable embedding layer, it differs from prior generative model-based adversarial attacks that use $n$ different copies of generative models for $n$ different targeted classes. As a result, CAG significantly reduces the required memory cost for generating adversarial examples. CAG can generate adversarial perturbations that focus on the critical areas of input by integrating the class activation maps information in the training process, and hence improve the robustness of CAG attack against the state-of-art adversarial defenses. In addition, CAG exhibits high transferability across different DNN classifier models in black-box attack scenario by introducing random dropout in the process of generating perturbations. Extensive experiments on different datasets and DNN models have verified the real-time, low-cost, enhanced-robustness, and high-transferability benefits of CAG.